深度学习课程笔记(七):模仿学习(imitation learning)
深度学习课程笔记(七):模仿学习(imitation learning)
2017.12.10

本文所涉及到的 模仿学习,则是从给定的展示中进行学习。机器在这个过程中,也和环境进行交互,但是,并没有显示的得到 reward。在某些任务上,也很难定义 reward。如:自动驾驶,撞死一人,reward为多少,撞到一辆车,reward 为多少,撞到小动物,reward 为多少,撞到 X,reward 又是多少,诸如此类。。。而某些人类所定义的 reward,可能会造成不可控制的行为,如:我们想让 agent 去考试,目标是让其考 100,那么,这个 agent 则可能会为了考 100,而采取作弊的方式,那么,这个就比较尴尬了,是吧 ?我们当然想让 agent 在学习到某些本领的同时,能遵守一定的规则。给他们展示怎么做,然后让其自己去学习,会是一个比较好的方式。
本文所涉及的三种方法:1. 行为克隆,2. 逆强化学习,3. GAN 的方法
接下来,我们将分别介绍这三种方法:
一、Behavior Cloning :
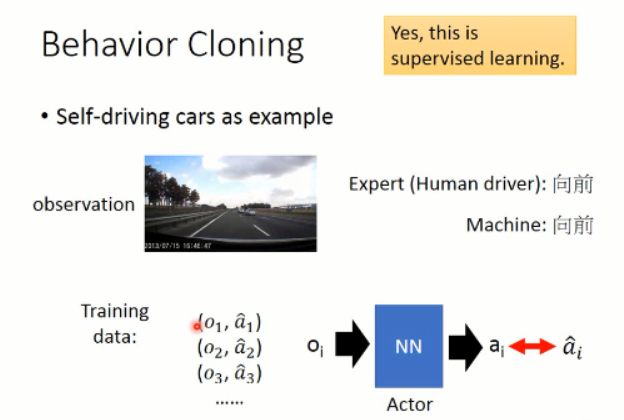
这里以自动驾驶为例,首先我们要收集一堆数据,就是 demo,然后人类做什么,就让机器做什么。其实就是监督学习(supervised learning),让 agent 选择的动作和 给定的动作是一致的。。。
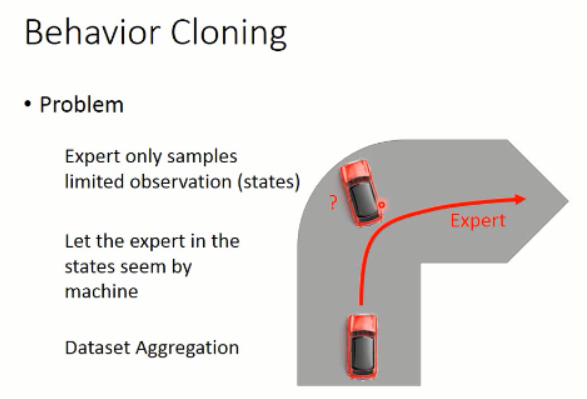
但是,这个方法是有问题的,因为 你给定的 data,是有限的,而且是有限制的。那么,在其他数据上进行测试,则可能不会很好。
要么,你增加 training data,加入平常 agent 没有看到过的数据,即:dataset aggregation 。

通过不断地增加数据,那么,就可以很好的改进 agent 的策略。有些场景下,也许适应这种方法。。。

而且,你的观测数据 和 策略是有联系的。因为在监督学习当中,我们需要 training data 和 test data 独立同分布。但是,有时候,这两者是不同的,那么,就惨了。。。
于是,另一类方法,出现了,即:Inverse Reinforcement Learning (也称为:Inverse Optimal Control,Inverse Optimal Planning)。
二、Inverse Reinforcement Learning (“Apprenticeship learning via Inverse Reinforcement Learning”, ICML 2004)
顾名思义,IRL 是 反过来的 RL,RL 是根据 reward 进行参数的调整,然后得到一个 policy。大致流程应该是这个样子:

但是, IRL 就不同了,因为他没有显示的 reward,只能根据 人类行为,进行 reward的估计(反推 reward 的函数)。
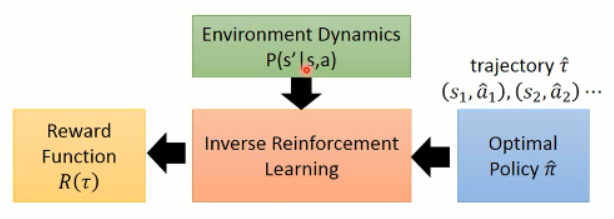
在得到 reward 函数估计出来之后,再进行 策略函数的估计。。。
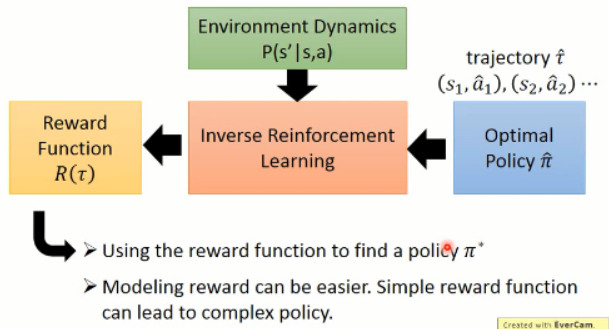
原本的 RL,就是给定一个 reward function R(t)(奖励的加和,即:回报),然后,这里我们回顾一下 RL 的大致过程(这里以 policy gradient 方法为例)

而 Inverse Reinforcement Learning 这是下面的这个思路:

逆强化学习 则是在给定一个专家之后(expert policy),通过不断地寻找 reward function 来满足给定的 statement(即,解释专家的行为,explaining expert behavior)。。。
专家的这个回报是最大的,英雄级别的,比任何其他的 actor 得到的都多。。。
据说,这个 IRL 和 structure learning 是非常相似的:
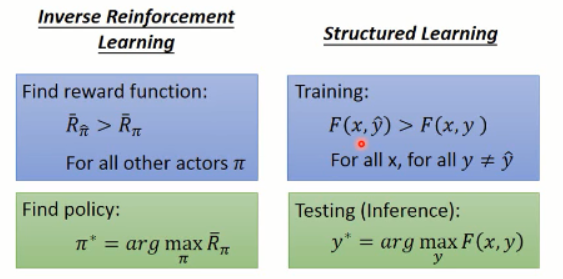
可以看到,貌似真是的哎。。。然后,复习下什么是 结构化学习:

我们对比下, IRL 和 结构化学习:
=======================================================================
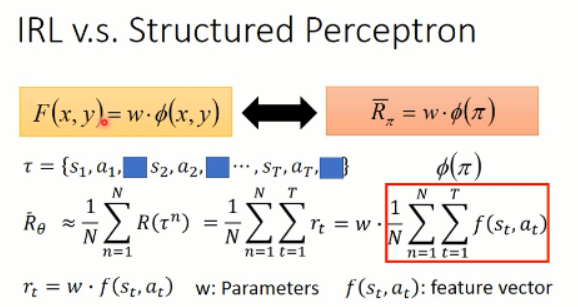
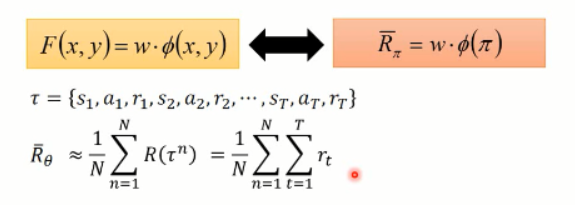
我们可以看到,由于我们无法知道得到的 reward 情况,所以,我们只能去估计这些 奖励的函数,然后,我们用参数 w 来进行估计:
所以, r 可以写成 w 和 f(s, a) 相乘的形式。w 就是我们所要优化的参数,而 f(s,a)就是我们提取的 feature vector。

那么 IRL 的流程究竟是怎样的呢???
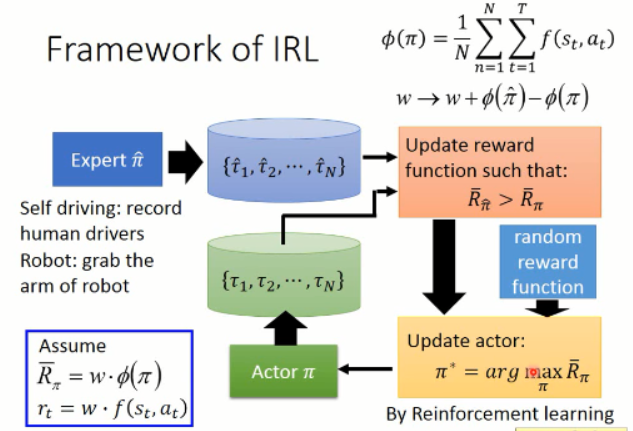
上面就是 IRL 所做的整个流程了。
三、GAN for Imitation Learning (Generative Adversarial imitation learning, NIPS, 2016)
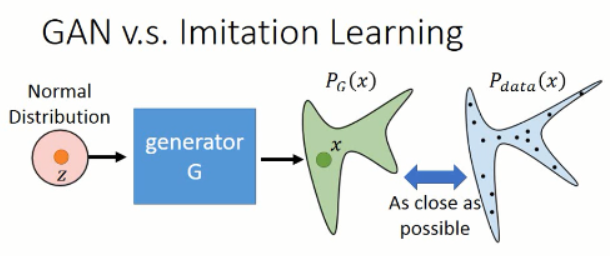
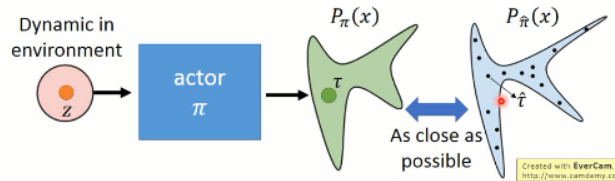
那么如何用 GAN 来做这个事情呢?对应到这件事情上,我们知道,我们想得到的 轨迹 是属于某一个高维的空间中,而 expert 给定的那些轨迹,我们假设是属于一个 distribution,我们想让我们的 model,也去 predict 一个分布出来,然后使得这两者之间尽可能的接近。从而完成 actor 的训练过程,示意图如下所示:
=============================== 过程 ================================
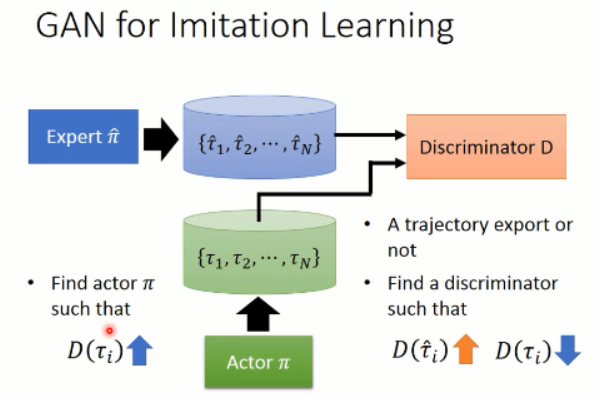
====>> Generator:产生出一个轨迹,
====>> Discriminator:判断给定的轨迹是否是 expert 做的?

==========================================================================
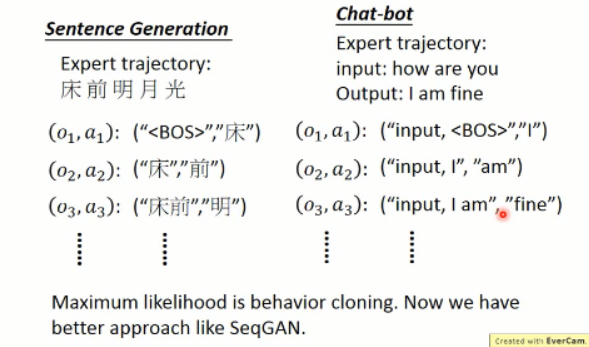
Recap:Sentence Generation and Chat-bot
==========================================================================
===========================================================
===========================================================
Examples of Recent Study :








深度学习课程笔记(七):模仿学习(imitation learning)的更多相关文章
- 深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE
深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE 201 ...
- 深度学习课程笔记(十七)Meta-learning (Model Agnostic Meta Learning)
深度学习课程笔记(十七)Meta-learning (Model Agnostic Meta Learning) 2018-08-09 12:21:33 The video tutorial can ...
- 深度学习课程笔记(十二) Matrix Capsule
深度学习课程笔记(十二) Matrix Capsule with EM Routing 2018-02-02 21:21:09 Paper: https://openreview.net/pdf ...
- 深度学习课程笔记(十一)初探 Capsule Network
深度学习课程笔记(十一)初探 Capsule Network 2018-02-01 15:58:52 一.先列出几个不错的 reference: 1. https://medium.com/ai% ...
- 深度学习课程笔记(四)Gradient Descent 梯度下降算法
深度学习课程笔记(四)Gradient Descent 梯度下降算法 2017.10.06 材料来自:http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS1 ...
- 深度学习课程笔记(一)CNN 卷积神经网络
深度学习课程笔记(一)CNN 解析篇 相关资料来自:http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17_2.html 首先提到 Why CNN for I ...
- 深度学习课程笔记(十六)Recursive Neural Network
深度学习课程笔记(十六)Recursive Neural Network 2018-08-07 22:47:14 This video tutorial is adopted from: Youtu ...
- 深度学习课程笔记(十五)Recurrent Neural Network
深度学习课程笔记(十五)Recurrent Neural Network 2018-08-07 18:55:12 This video tutorial can be found from: Yout ...
- 深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO)
深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO) 2018-07-17 16:54:51 Reference: https://b ...
随机推荐
- Vue系列之 => 使用第三方animated.css动画
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 【Hive学习之一】Hive简介
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 apache-hive-3.1.1 ...
- linux lsof用法
linux lsof命令详解 简介 lsof(list open files)是一个列出当前系统打开文件的工具.在linux环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可 ...
- win7 怎么设置开机直接进入桌面? netplwiz 命令
电脑没设置密码,开机如何跳过帐户已锁定的界面,直接进入桌面呢? 1.单击[运行],或按快捷键:win+r2.输入命令:netplwiz 单击[确定]3.单击你的登录账户4.去掉[要使用本机,用户名必须 ...
- Wi-Fi Mesh网络技术
Wi-Fi在很早的时候就引入了mesh技术,并且最近得到了越来越多的关注.谷歌.Eero.Linksys.Netgear以及几乎所有以家庭和小型办公室为目标的网络品牌都提供了mesh网格系统.但是也有 ...
- sql语句查询排序
一:sql语句单词意义 order by 是用在where条件之后,用来对查询结果进行排序 order by 字段名 asc/desc asc 表示升序(默认为asc,可以省略) desc表示降序 o ...
- 怎样从外网访问内网Linux系统?
本地安装了一个Linux系统,只能在局域网内访问到,怎样从外网也能访问到本地的Linux系统呢?本文将介绍具体的实现步骤. 1. 准备工作 1.1 启动Linux系统 默认Linux系统ssh服务端端 ...
- Mysql初级第二天(wangyun)
SQL 1.LIKE 操作符 SELECT 列名称 FROM 表名称 WHERE 列 LIKE 值('N%'/'%N%'/'%N','N_') SELECT 列名称 FROM 表名称 WHERE 列 ...
- java使用wait(),notify(),notifyAll()实现等待/通知机制
public class WaitNotify { static boolean flag=true; static Object lock=new Object(); static class Wa ...
- PHP 中文工具类,支持汉字转拼音、拼音分词、简繁互转
ChineseUtil 下载地址:https://github.com/Yurunsoft/ChineseUtil 另外一个中文转拼音工具:https://github.com/overtrue/pi ...