[MySQL数据库之表的约束条件:primary key、auto_increment、not null与default、unique、foreign key:表与表之间建立关联]
[MySQL数据库之表的约束条件:primary key、auto_increment、not null与default、unique、foreign key:表与表之间建立关联]
表的约束条件
约束条件与数据类型的宽度一样,都是可选参数
作用:用于保证数据的完整性和一致性
主要分为:
PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录
FOREIGN KEY (FK) 标识该字段为该表的外键
NOT NULL 标识该字段不能为空
UNIQUE KEY (UK) 标识该字段的值是唯一的
AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键)
DEFAULT 为该字段设置默认值
UNSIGNED 无符号
ZEROFILL 使用0填充
说明:
1. 是否允许为空,默认NULL,可设置NOT NULL,字段不允许为空,必须赋值
2. 字段是否有默认值,缺省的默认值是NULL,如果插入记录时不给字段赋值,此字段使用默认值
sex enum('male','female') not null default 'male'
age int unsigned NOT NULL default 20 必须为正值(无符号) 不允许为空 默认是20
3. 是否是key
主键 primary key
外键 foreign key
索引 (index,unique...)
primary key
从约束角度看primary key字段的值不为空且唯一
主键primary key是innodb存储引擎组织数据的依据,innodb称之为索引组织表,一张表中必须有且只有一个主键。
一个表中可以:
单列做主键
多列做主键(复合主键)
主键通常都是id字段:对于以后建的表都是innodb存储引擎的,
在建表的时候一定要有id,id一定得是主键
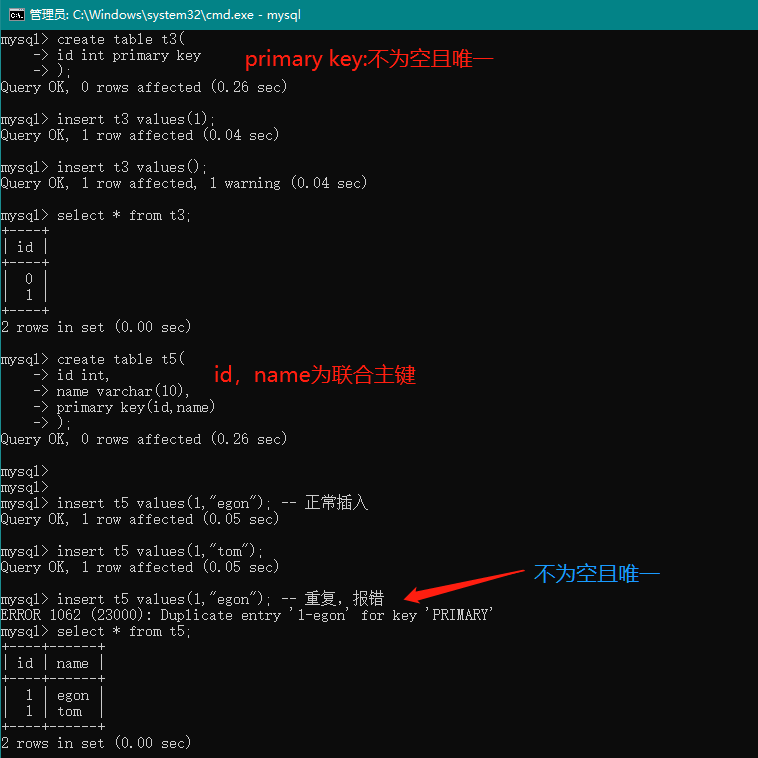
create table t3(
id int primary key
);
insert t3 values(1);
联合主键(了解)
create table t5(
id int,
name varchar(10),
primary key(id,name)
);
insert t5 values(1,"egon"); -- 正常插入
insert t5 values(1,"tom"); -- 正常插入
insert t5 values(1,"egon"); -- 重复,报错
auto_increment
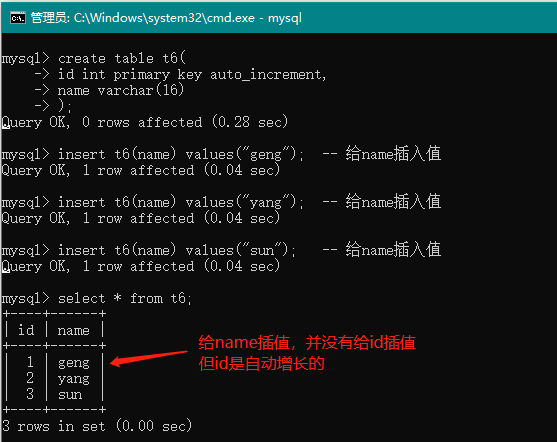
约束字段为自动增长,被约束的字段必须同时被key约束
create table t6(
id int primary key auto_increment,
name varchar(16)
);
insert t6(name) values("geng"); -- 给name插入值
insert t6(name) values("yang"); -- 给name插入值
insert t6(name) values("sun"); -- 给name插入值
not null与default
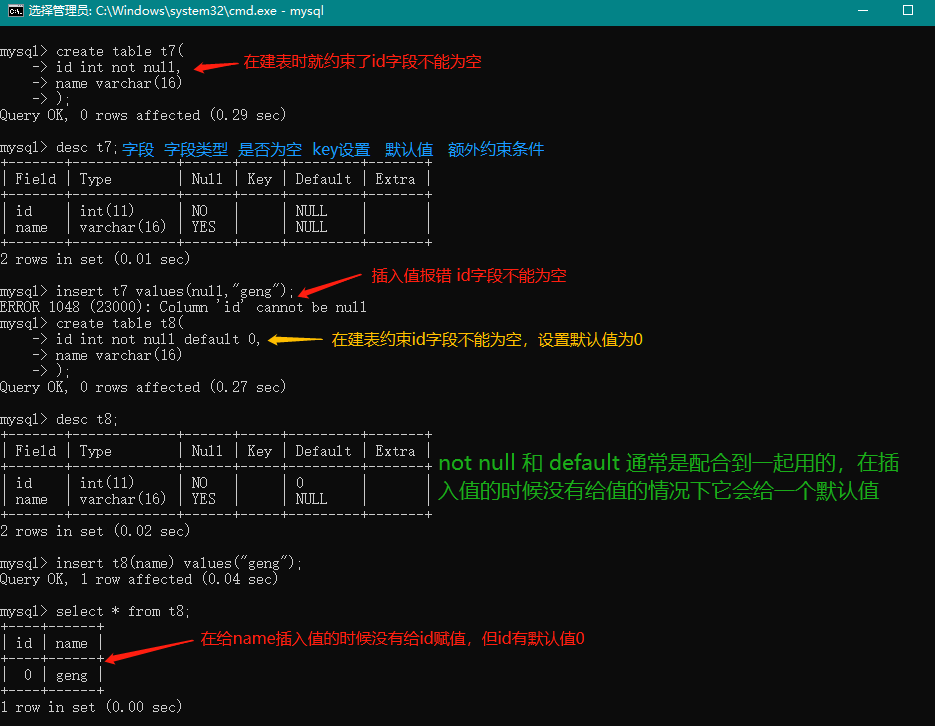
是否可空,null表示空,非字符串
not null - 不可空
null - 可空
default - 默认值,创建列时可以指定默认值,当插入数据时如果未主动设置,则自动添加默认值
设置id字段有默认值后,则无论id字段是null还是not null,都可以插入空,插入空默认填入default指定的默认值
create table t7(
id int not null,
name varchar(16)
);
insert t7 values(null,"geng");
create table t8(
id int not null default 0,
name varchar(16)
);
insert t8(name) values("geng");
unique
unique设置唯一约束,不允许重复
create table t9(
id int unique,
name varchar(16)
);
insert t9 values(1,"geng");
insert t9 values(1,"yang"); -- 报错id重复
补充知识:not null+unique的化学反应
create table t10(
id int not null unique,
name varchar(16)
);
id 字段变成了主键:不为空且唯一
mysql> create table t10(
-> id int not null unique,
-> name varchar(16)
-> );
Query OK, 0 rows affected (0.24 sec)
mysql> desc t10;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(16) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.02 sec)
foreign key
员工信息表有三个字段:工号 姓名 部门
公司有3个部门,但是有1个亿的员工,那意味着部门这个字段需要重复存储,部门名字越长,越浪费
解决方法:
我们完全可以定义一个部门表
然后让员工信息表关联该表,如何关联,即foreign key
表与表之间建立关联
多对一关系
创建表时需要先建立被关联表
create table dep(
id int primary key auto_increment,
name varchar(20),
comment varchar(50)
);
再创建关联表(同步更新,同步删除)
create table emp(
id int primary key auto_increment,
name varchar(16),
age int,
dep_id int,
foreign key(dep_id) references dep(id)
on update cascade
on delete cascade
);
插入数据时,应该先往dep插入数据,再往emp插入数据
insert dep(name,comment) values
("IT","搞技术"),
("sale","卖东西"),
("HR","招聘")
;
insert emp(name,age,dep_id) values
("egon",18,1),
("tom",19,2),
("lili",28,2),
("jack",38,1),
("lxx",78,3);
》》加了foreign key之后级联更新级联删除会带来额外的效果
更新dep,emp中对应的数据跟着改
update dep set id=33 where name ="HR";

删除dep,emp中对应的数据跟着删除
delete from dep where id=2;
# 删除dep表中的id为2的销售部门,emp表中对应dep销售部门的员工也跟着删除了
mysql> delete from dep where id=2;
Query OK, 1 row affected (0.23 sec)
mysql> select * from dep;
+----+------+-----------+
| id | name | comment |
+----+------+-----------+
| 1 | IT | 搞技术 |
| 33 | HR | 招聘 |
+----+------+-----------+
2 rows in set (0.00 sec)
mysql> select * from emp;
+----+------+------+--------+
| id | name | age | dep_id |
+----+------+------+--------+
| 1 | egon | 18 | 1 |
| 4 | jack | 38 | 1 |
| 5 | lxx | 78 | 33 |
+----+------+------+--------+
3 rows in set (0.00 sec)
多对多关系
egon 九阳神功
egon 祥龙十八掌
egon 易筋经
egon 九阴真经
egon 葵花宝典
jason 九阳神功
jason 祥龙十八掌
lxx 易筋经
lxx 九阴真经
hxx 祥龙十八掌
hxx 易筋经
hxx 九阴真经
# 多个作者编写一本书
# 一个作者编写多本书
create table author(
id int primary key auto_increment,
name varchar(16)
);
create table book(
id int primary key auto_increment,
name varchar(20)
);
create author2book(
id int primary key auto_increment,
author_id int,
book_id int,
foreign key(author_id) references author(id)
on update cascade
on delete cascade,
foreign key(book_id) references book(id)
on update cascade
on delete cascade
);
一对一关系
#一定是student来foreign key表customer,这样就保证了:
#1 学生一定是一个客户,
#2 客户不一定是学生,但有可能成为一个学生
create table customer(
id int primary key auto_increment,
name varchar(20) not null,
qq varchar(10) not null,
phone char(16) not null
);
create table student(
id int primary key auto_increment,
class_name varchar(20) not null,
customer_id int unique, # 该字段一定要是唯一的
foreign key(customer_id) references customer(id) # 外键的字段一定要保证unique
on delete cascade
on update cascade
);
# 增加客户
insert into customer(name,qq,phone) values
('蔡子奇','31811231',13811341220),
('孙宗伟','123123123',15213146809),
('胡玉康','283818181',1867141331),
('刘洋','283818181',1851143312),
('杨逸轩','888818181',1861243314),
('杨杰','112312312',18811431230)
;
# 增加学生
insert into student(class_name,customer_id) values
('牛逼1班',3),
('装逼2班',4),
('装逼2班',5)
;
如何找出两张表之间的关系
>>分析步骤:
1、先站在左表的角度去找
是否左表的多条记录可以对应右表的一条记录,如果是,则证明左表的一个
字段foreign key 右表一个字段(通常是id)
2、再站在右表的角度去找
是否右表的多条记录可以对应左表的一条记录,如果是,则证明右表的一个
字段foreign key 左表一个字段(通常是id)
3、总结:
# 多对一:
如果只有步骤1成立,则是左表多对一右表
如果只有步骤2成立,则是右表多对一左表
# 多对多
如果步骤1和2同时成立,则证明这两张表时一个双向的多对一,即多对多,
需要定义一个这两张表的关系表来专门存放二者的关系
# 一对一:
如果1和2都不成立,而是左表的一条记录唯一对应右表的一条记录,反之亦然。这种情况
很简单,就是在左表foreign key右表的基础上,将左表的外键字段设置成unique即可
建立表之间的关系
# 一对多或称为多对一
三张表:出版社,作者信息,书
一对多(或多对一):一个出版社可以出版多本书
关联方式:foreign key
# 多对多
三张表:出版社,作者信息,书
多对多:一个作者可以写多本书,一本书也可以有多个作者,双向的一对多,即多对多
关联方式:foreign key+一张新的表
# 一对一
两张表:学生表和客户表
一对一:一个学生是一个客户,一个客户有可能变成一个学校,即一对一的关系
关联方式:foreign key+unique
总结:表之间的三种关系:多对一、多对多、一对一,在设计数据库表结构的时候,这是一个项目的基石,数据库表结构设计好之后项目基本上就算是完成了,要真正写代码就是一个简单的事情了,数据怎么存会影响到后面代码的编写,对于设计数据库表有三个原则
1、把专门的数据放到专门的表
2、表跟表之间要建立好关系(三种关系)
3、在建表关系的时候:能用多对多就不要用多对一,能用多对一就不要用一对一
表的完整约束条件参考: https://www.cnblogs.com/linhaifeng/articles/7238814.html
[MySQL数据库之表的约束条件:primary key、auto_increment、not null与default、unique、foreign key:表与表之间建立关联]的更多相关文章
- 【转】表删除时 Cannot delete or update a parent row: a foreign key constraint fails 异常处理
转载地址:http://lijiejava.iteye.com/blog/790478 有两张表,结构如下: t_item: t_bid: id ...
- 表删除时 Cannot delete or update a parent row: a foreign key constraint fails 异常处理
有两张表,结构如下: t_item: t_bid: id int id int n ...
- mysql数据库表自增ID批量清零 AUTO_INCREMENT = 0
mysql数据库表自增ID批量清零 AUTO_INCREMENT = 0 #将数据库表自增ID批量清零 SELECT CONCAT( 'ALTER TABLE ', TABLE_NAME, ' AUT ...
- sqlalchemy.exc.InternalError: (pymysql.err.InternalError) (1091, "Can't DROP 'users_ibfk_1'; check that column/key exists") [SQL: ALTER TABLE users DROP FOREIGN KEY users_ibfk_1]
flask 迁移数据库报错 报错: sqlalchemy.exc.InternalError: (pymysql.err.InternalError) (1091, "Can't DROP ...
- insert时报Cannot add or update a child row: a foreign key constraint fails (`yanchangzichan`.`productstatusrecord`, CONSTRAINT `p_cu` FOREIGN KEY (`cid`) REFERENCES `customer` (`cid`))错误
mybatis在insert时报Cannot add or update a child row: a foreign key constraint fails (`yanchangzichan`.` ...
- MySQL添加foreign key时出现1215 Cannot add the foreign key constraint
引言: MySQL中经常会需要创建父子表之间的约束,这个约束是需要建立在主外键基础之上的,这里解决了一个在创建主外键约束过程中碰到的一个问题. mysql中添加外键约束遇到一下情况: cannot a ...
- 解决Cannot delete or update a parent row: a foreign key constraint fails (`current_source_products`.`product_storage`, CONSTRAINT `product_storage_ibfk_3` FOREIGN KEY (`InOperatorID`)
出现这个异常的原因是因为设置了外键,造成无法更新或删除数据. 1.通过设置FOREIGN_KEY_CHECKS变量来避免这种情况 删除前设置 SET FOREIGN_KEY_CHECKS=0; 删除完 ...
- MySQL数据库(四)—— 记录相关操作之插入、更新、删除、查询(单表、多表)
一.插入数据(insert) 1. 插入完整数据(顺序插入) 语法一: INSERT INTO 表名(字段1,字段2,字段3…字段n) VALUES(值1,值2,值3…值n); # 后面的值必须与字段 ...
- MySQL添加外键报错 - referencing column 'xx' and referenced column 'xx' in foreign key constraint 'xx' are incompatible
MySQL给两个表添加外键时,报错 翻译意思是:外键约束“xx”中的引用列“xx”和引用列“xx”不兼容 说明两个表关联的列数据类型不一致,比如:varchar 与 int,或者 int无符号 与 i ...
随机推荐
- 攻防世界 resver catch-me
catch-me asis-ctf-quals-2016 附件给了个压缩包文件,重命名,解压,获取到elf文件 程序有两处关键比较 第一处: 这里进行动态调试,得到v3=0xB11924E1, byt ...
- [go-linq]-Go的.NET LINQ式查询方法
关于我 我的博客|文章首发 开发者的福音,go也支持linq了 坑爹的集合 go在进行集合操作时,有很不舒服的地方,起初我真的是无力吐槽,又苦于找不到一个好的第三方库,只能每次写着重复代码.举个栗子 ...
- 浅谈意图识别各种实现&数学原理
\[ J_\alpha(x) = \sum_{m=0}^\infty \frac{(-1)^m}{m! \Gamma (m + \alpha + 1)} {\left({ \frac{x}{2} }\ ...
- 接口自动化——读取Excle中遇到的问题
一.module 'openpyxl' has no attribute 'load_workbook'问题 原因:在pycharm中py文件名字为openpyxl导致 修改方法:重新对py名字进行命 ...
- 别人 echo 、你也 echo ,是问 echo 知多少?-- Shell十三问<第三问>
别人 echo .你也 echo ,是问 echo 知多少?-- Shell十三问<第三问> 承接上一章所介绍的 command line ,这里我们用 echo 这个命令加以进一步说明. ...
- 字符串转成KB,MB, GB
import java.text.DecimalFormat; public class SizeUtil { public static String GetImageSize(String ima ...
- Mybatis3源码笔记(五)mapperElement
1.四种解析mapper方式 : package,resource,url,class. <mappers> <mapper resource="org/apache/ib ...
- Day05_26_Overide_方法重写
Overide_方法重写 * 什么是方法重写(Overide)? - 方法重写也叫方法覆盖 ,重写是指子类对父类所允许访问的方法的实现过程进行重新编写, 返回值类型和形参都不能改变.即外壳不变,核心重 ...
- python3存储numpy格式的矩阵
技术背景 numpy在python中的地位是相当高的,即使是入门的python使用者也会经常看到这个库的使用.除了替代python自带的列表数据格式list之外,numpy的一大优势是其底层的高性能实 ...
- 1.8.7- HTML值label标签
1.label直接进行包裹input就可以了.