过去,我买漫画看;现在,我用Python爬虫来看
原标题:运用Python多线程爬虫下载漫画
前言:
以前,我都是买漫画书看的,那个时候没有电脑。今天,我到网上看了一下,发现网上提供漫画看,但是时时需要网络啊!为什么不将它下载下来呢!
1.怎样实现
这个项目需要的模块有:requests、urllib、threading、os、sys
其中requests模块也可以不用,只要urllib模块即可,但我觉得requests模块爬取数据代码量少。
os模块主要是为了创建文件夹,sys主要是为了结束程序(当然,这里我只是判断是否已经存在我即将创建的文件夹,如果存在,我就直接结束程序了,这个位于代码的开头)。
1.1 爬取我们需要的数据(网页链接、漫画名称、漫画章节名称)

我爬取漫画的网址为:https://www.mkzhan.com/
我们到搜索栏上输入 一个漫画名称
我输入的是:斗破苍穹,点击搜索,可以看到这个界面:
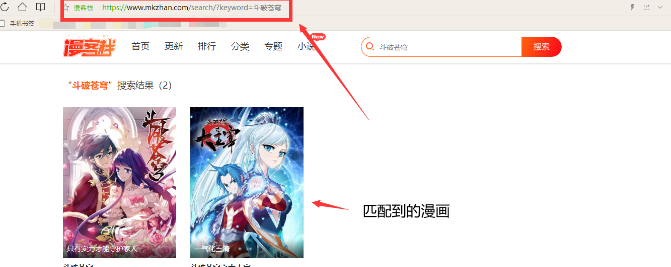
对这个网址进行分析:https://www.mkzhan.com/search/?keyword={}
大括号代表的内容就是我们输入的漫画名称,我们只要这样组合,就可以得到这个网址:
from urllib import parse
_name=input('请输入你想看的漫画:')
name_=parse.urlencode({'keyword':_name})
url='https://www.mkzhan.com/search/?{}'.format(name_)
之后,就是对这个网址下面的内容进行爬取了,这个过程很容易,我就不讲了。
我们点击一下其中的一本漫画,来到这个界面
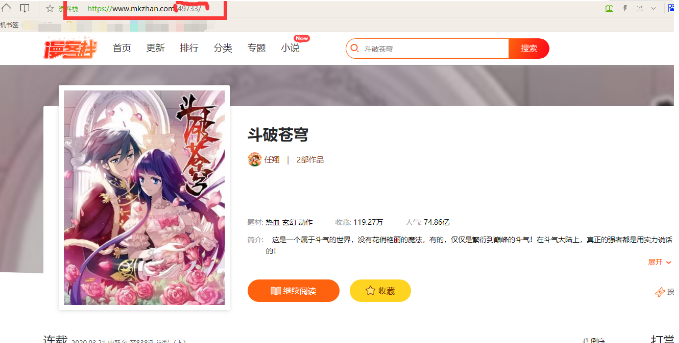
这个网址,需要我们从上一个网址中得到并进行拼接,我们需要得到这个网址下面的漫画所有章节的链接和名称。
我们按F12来到开发者工具:
可以发现这些章节的内容在这个标签下面:
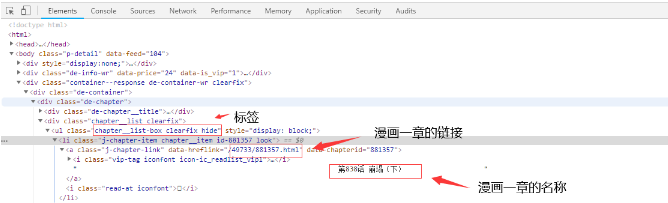
html1=requests.get(url=url1)
content1=html1.text
soup1=BeautifulSoup(content1,'lxml')
str2=soup1.select('ul.chapter__list-box.clearfix.hide')[0]
list2=str2.select('li>a')
name1=[]
href1=[]
for str3 in list2:
href1.append(str3['data-hreflink']) # 漫画一章的链接
name1.append(str3.get_text().strip()) # 漫画一章的题目,去空格
这样我们就可以得到我们想要的内容了,我们点击其中的一章进入,发现里面只不过是一些图片罢了,我们只需把这些图片下载下来就行了。

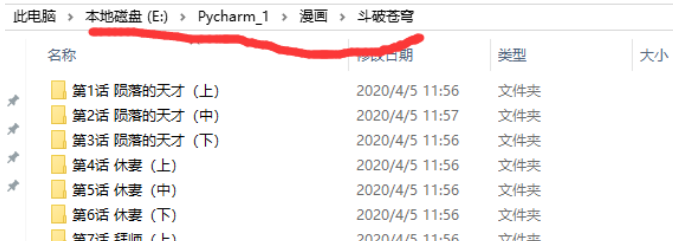
代码运行结果:


下载完成之后,会在同一个文件夹下面多出一个文件夹,文件夹的名称为你输入漫画名称,这个文件夹下面会有很多文件夹,这些文件夹的名称是漫画章节的名称。


2.完整代码:
import requests
from urllib import parse
from bs4 import BeautifulSoup
import threading
import os
import sys _name=input('请输入你想看的漫画:') try:
os.mkdir('./{}'.format(_name))
except:
print('已经存在相同的文件夹了,程序无法在继续进行!')
sys.exit() name_=parse.urlencode({'keyword':_name})
url='https://www.mkzhan.com/search/?{}'.format(name_)
html=requests.get(url=url)
content=html.text
soup=BeautifulSoup(content,'lxml')
list1=soup.select('div.common-comic-item')
names=[]
hrefs=[]
keywords=[]
for str1 in list1:
names.append(str1.select('p.comic__title>a')[0].get_text()) # 匹配到的漫画名称
hrefs.append(str1.select('p.comic__title>a')[0]['href']) # 漫画的网址
keywords.append(str1.select('p.comic-feature')[0].get_text()) # 漫画的主题
print('匹配到的结果如下:')
for i in range(len(names)):
print('【{}】-{} {}'.format(i+1,names[i],keywords[i])) i=int(input('请输入你想看的漫画序号:'))
print('你选择的是{}'.format(names[i-1])) url1='https://www.mkzhan.com'+hrefs[i-1] # 漫画的链接
html1=requests.get(url=url1)
content1=html1.text
soup1=BeautifulSoup(content1,'lxml')
str2=soup1.select('ul.chapter__list-box.clearfix.hide')[0]
list2=str2.select('li>a')
name1=[]
href1=[]
for str3 in list2:
href1.append(str3['data-hreflink']) # 漫画一章的链接
name1.append(str3.get_text().strip()) # 漫画一章的题目,去空格 def Downlad(href1,path):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3756.400 QQBrowser/10.5.4039.400'}
url2='https://www.mkzhan.com'+href1
html2=requests.get(url=url2,headers=headers)
content2=html2.text
soup2=BeautifulSoup(content2,'lxml')
list_1=soup2.select('div.rd-article__pic.hide>img.lazy-read') # 漫画一章中的所有内容列表
urls=[]
for str_1 in list_1:
urls.append(str_1['data-src']) for i in range(len(urls)):
url=urls[i]
content3=requests.get(url=url,headers=headers)
with open(file=path+'/{}.jpg'.format(i+1),mode='wb') as f:
f.write(content3.content)
return True def Main_Downlad(href1:list,name1:list):
while True:
if len(href1)==0:
break
href=href1.pop()
name=name1.pop()
try:
path='./{}/{}'.format(_name,name)
os.mkdir(path=path)
if Downlad(href, path):
print('线程{}正在下载章节{}'.format(threading.current_thread().getName(),name))
except:
pass threading_1=[]
for i in range(30):
threading1=threading.Thread(target=Main_Downlad,args=(href1,name1,))
threading1.start()
threading_1.append(threading1)
for i in threading_1:
i.join()
print('当前线程为{}'.format(threading.current_thread().getName()))
3.总结
我觉得这个程序还有很大的改进空间,如做一个ip代理池,这样再也不用担心ip被封了,另外,还可以做一个自动播放漫画图片的程序,这样就可以减少一些麻烦了。
注意:本程序代码仅供娱乐和学习,且莫用于商业活动,一经发现,概不负责。
如果大家觉得这个还可以的话,记得给我点一个小小的赞。
过去,我买漫画看;现在,我用Python爬虫来看的更多相关文章
- 《奥威Power-BI案例应用:带着漫画看报告》腾讯课程开课啦
元旦小假期过去了,不管是每天只给自己两次下床机会的你,还是唱K看电影逛街样样都嗨的你,是时候重振旗鼓,重新上路了!毕竟为了不给国家的平均工资水平拖后腿,还是要努力工作的.话说2016年已经过去了,什么 ...
- 小白学 Python 爬虫(26):为啥上海二手房你都买不起
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 面试前赶紧看了5道Python Web面试题,Python面试题No17
目录 本面试题题库,由公号:非本科程序员 整理发布 第1题: Flask中的请求上下文和应用上下文是什么? 第2题:django中间件的使用? 第3题: django开发中数据做过什么优化? 第4题: ...
- python爬虫08 | 你的第二个爬虫,要过年了,爬取豆瓣最受欢迎的250部电影慢慢看
马上就要过年啦 过年在家干啥咧 准备好被七大姑八大姨轮番「轰炸」了没? 你的内心 os 是这样的 但实际上你是这样的 应付完之后 闲暇时刻不妨看看电影 接下来咱们就来爬取豆瓣上评分最高的 250部电影 ...
- 看完100篇Python技术精华文章,平均涨薪30%!
一个以技术为立身根基的教育机构做出来的微信号,干货程度会有多高? 马哥Linux运维公众号运营五年,从一开始的定位就是给技术人分享加薪干货的地方.这五年里,公众号运营最重的任务就是做内容.内容并不好做 ...
- 菜鸟版JAVA设计模式—从买房子看代理模式
今天学习了代理模式. 相对于适配器模式,或者说装饰器模式,代理模式理解起来更加简单. 代理这个词应该比較好理解,取代去做就是代理. 比方,我们买卖房子,那么我们会找中介,我要卖房子,可是我们没有时间去 ...
- 为了给女朋友买件心怡内衣,我用Python爬虫了天猫内衣售卖数据
真爱,请置顶或星标 大家好,希望各位能怀着正直.严谨.专业的心态观看这篇文章.ヾ(๑╹◡╹)ノ" 接下来我们尝试用 Python 抓取天猫内衣销售数据,并分析得到中国女性普遍的罩杯数据.最受 ...
- Python爬虫---爬取腾讯动漫全站漫画
目录 操作环境 网页分析 明确目标 提取漫画地址 提取漫画章节地址 提取漫画图片 编写代码 导入需要的模块 获取漫画地址 提取漫画的内容页 提取章节名 获取漫画源网页代码 下载漫画图片 下载结果 完整 ...
- 大概看了一天python request源码。写下python requests库发送 get,post请求大概过程。
python requests库发送请求时,比如get请求,大概过程. 一.发起get请求过程:调用requests.get(url,**kwargs)-->request('get', url ...
随机推荐
- IDEA部署了项目,其他页面可以正常访问,但访问tomcat的localhost:8080却出现404
解决方案 点击Edit Configurations 点击右边的加号, 把目录放在你tomcat目录下的ROOT目录.之后就可以正常运行了
- HanLP使用教程——NLP初体验
话接上篇NLP的学习坑 自然语言处理(NLP)--简介 ,使用HanLP进行分词标注处词性. HanLP使用简介 HanLP是一系列模型与算法组成的NLP工具包,目标是普及自然语言处理在生产环境中的应 ...
- C#版Nebula客户端编译
一.需求背景 从Nebula的Github上可以发现,Nebula为以下语言提供了客户端SDK: nebula-cpp nebula-java nebula-go nebula-python nebu ...
- C语言:常量写法
float a=7.5f; //7.5为浮点数 long b=100L; //100为长整数 int c=0123;// 0123为8进制数 int d=0x123;//0x123为16进制数
- SyntaxError: unexpected EOF while parsing成功解决
报错在eval()函数: 我加了个 if 判断是否为空,就可以正常运行了!
- vue3 封装简单的 tabs 切换组件
背景:公司项目要求全部换成 vue3 ,而且也没有应用像 element-ui 一类的UI组件,用到的公共组件都是根据项目需求封装的,下面是使用vue3实现简单的tabs组件,我只是把代码分享出来,实 ...
- c++中的基本IO
引言 c++不直接处理输入和输出,而是通过标准库中的类型处理IO.IO的设备可以是文件.控制台.string.c++主要定义了三种IO类型,分别被包含在iostream.fstream.sstream ...
- FiddlerEverywhere 的配置和基本应用
一.下载大家自行在官网下载即可,这个可以当做是fiddler的升级版本,里面加了postman的功能,个人感觉界面比较清晰简约,比较喜欢. 二.下载完成之后大家可以自行注册登录,主页面的基本使用如下: ...
- JS文件延迟和异步加载:defer和async属性
-般情况下,在文档的 <head> 标签中包含 JavaScript 脚本,或者导入的 JavaScript 文件.这意味着必须等到全部 JavaScript 代码都被加载.解析和执行完以 ...
- golang可执行文件瘦身(缩小文件大小)
起因 golang部署起来极其遍历,但有时候希望对可执行文件进行瘦身(缩小文件大小) 尝试 情况允许情况下,交叉编译为32位 删除不必要的符号表.调试信息 尝试用对应平台的upx打压缩壳 解决 经过多 ...