kafka简单介绍
Kafka是分布式发布-订阅消息系统。它最初由LinkedIn公司开发,之后成为Apache项目的一部分。Kafka是一个分布式的,可划分的,冗余备份的持久性的日志服务。它主要用于处理活跃的流式数据。
在大数据系统中,常常会碰到一个问题,整个大数据是由各个子系统组成,数据需要在各个子系统中高性能,低延迟的不停流转。传统的企业消息系统并不是非常适合大规模的数据处理。为了已在同时搞定在线应用(消息)和离线应用(数据文件,日志)Kafka就出现了。Kafka可以起到两个作用:
1.降低系统组网复杂度。
2.降低编程复杂度,各个子系统不在是相互协商接口,各个子系统类似插口插在插座上,Kafka承担高速数据总线的作用。
1.Kafka主要特点
1.同时为发布和订阅提供高吞吐量。据了解,Kafka每秒可以生产约25万消息(50 MB),每秒处理55万消息(110 MB)。
2.可进行持久化操作。将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。通过将数据持久化到硬盘以及replication防止数据丢失。
3.分布式系统,易于向外扩展。所有的producer、broker和consumer都会有多个,均为分布式的。无需停机即可扩展机器。
4.消息被处理的状态是在consumer端维护,而不是由server端维护。当失败时能自动平衡。
5.支持online和offline的场景。
2.Kafka的架构

Kafka的整体架构非常简单,是显式分布式架构,producer、broker(kafka)和consumer都可以有多个。Producer,consumer实现Kafka注册的接口,数据从producer发送到broker,broker承担一个中间缓存和分发的作用。broker分发注册到系统中的consumer。broker的作用类似于缓存,即活跃的数据和离线处理系统之间的缓存。客户端和服务器端的通信,是基于简单,高性能,且与编程语言无关的TCP协议。几个基本概念:
1.Topic:特指Kafka处理的消息源(feeds of messages)的不同分类。
2.Partition:Topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。
3.Message:消息,是通信的基本单位,每个producer可以向一个topic(主题)发布一些消息。
4.Producers:消息和数据生产者,向Kafka的一个topic发布消息的过程叫做producers。
5.Consumers:消息和数据消费者,订阅topics并处理其发布的消息的过程叫做consumers。
6.Broker:缓存代理,Kafka集群中的一台或多台服务器统称为broker。
3.消息发送的流程
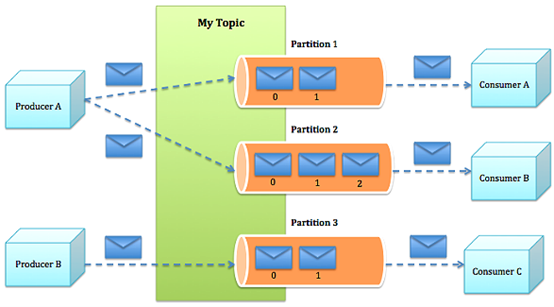
1.Producer根据指定的partition方法(round-robin、hash等),将消息发布到指定topic的partition里。。
2.kafka集群接收到Producer发过来的消息后,将其持久化到硬盘,并保留消息指定时长(可配置),而不关注消息是否被消费。
3.Consumer从kafka集群pull数据,并控制获取消息的offset。
4.Kafka的设计
4.1 吞吐量
高吞吐是kafka需要实现的核心目标之一,为此kafka做了以下一些设计:
1.数据磁盘持久化:消息不在内存中cache,直接写入到磁盘,充分利用磁盘的顺序读写性能
2.zero-copy:减少IO操作步骤
3.数据批量发送
4.数据压缩
5.Topic划分为多个partition,提高parallelism
4.2 负载均衡
1.producer根据用户指定的算法,将消息发送到指定的partition
2.存在多个partiiton,每个partition有自己的replica,每个replica分布在不同的Broker节点上
3.多个partition需要选取出lead partition,lead partition负责读写,并由zookeeper负责fail over
4.通过zookeeper管理broker与consumer的动态加入与离开
4.3 拉取系统
由于kafka broker会持久化数据,broker没有内存压力,因此,consumer非常适合采取pull的方式消费数据,具有以下几点好处:
1.简化kafka设计
2.consumer根据消费能力自主控制消息拉取速度
3.consumer根据自身情况自主选择消费模式,例如批量,重复消费,从尾端开始消费等
4.4 可扩展性
当需要增加broker结点时,新增的broker会向zookeeper注册,而producer及consumer会根据注册在zookeeper上的watcher感知这些变化,并及时作出调整。
Kafka的应用场景:
1.消息队列
比起大多数的消息系统来说,Kafka有更好的吞吐量,内置的分区,冗余及容错性,这让Kafka成为了一个很好的大规模消息处理应用的解决方案。消息系统一般吞吐量相对较低,但是需要更小的端到端延时,并常常依赖于Kafka提供的强大的持久性保障。在这个领域,Kafka足以媲美传统消息系统,如ActiveMR或RabbitMQ。
2.行为跟踪
Kafka的另一个应用场景是跟踪用户浏览页面、搜索及其他行为,以发布-订阅的模式实时记录到对应的topic里。那么这些结果被订阅者拿到后,就可以做进一步的实时处理,或实时监控,或放到hadoop/离线数据仓库里处理。
3.元信息监控
作为操作记录的监控模块来使用,即汇集记录一些操作信息,可以理解为运维性质的数据监控吧。
4.日志收集
日志收集方面,其实开源产品有很多,包括Scribe、Apache Flume。很多人使用Kafka代替日志聚合(log aggregation)。日志聚合一般来说是从服务器上收集日志文件,然后放到一个集中的位置(文件服务器或HDFS)进行处理。然而Kafka忽略掉文件的细节,将其更清晰地抽象成一个个日志或事件的消息流。这就让Kafka处理过程延迟更低,更容易支持多数据源和分布式数据处理。比起以日志为中心的系统比如Scribe或者Flume来说,Kafka提供同样高效的性能和因为复制导致的更高的耐用性保证,以及更低的端到端延迟。
5.流处理
这个场景可能比较多,也很好理解。保存收集流数据,以提供之后对接的Storm或其他流式计算框架进行处理。很多用户会将那些从原始topic来的数据进行阶段性处理,汇总,扩充或者以其他的方式转换到新的topic下再继续后面的处理。例如一个文章推荐的处理流程,可能是先从RSS数据源中抓取文章的内容,然后将其丢入一个叫做“文章”的topic中;后续操作可能是需要对这个内容进行清理,比如回复正常数据或者删除重复数据,最后再将内容匹配的结果返还给用户。这就在一个独立的topic之外,产生了一系列的实时数据处理的流程。Strom和Samza是非常著名的实现这种类型数据转换的框架。
6.事件源
事件源是一种应用程序设计的方式,该方式的状态转移被记录为按时间顺序排序的记录序列。Kafka可以存储大量的日志数据,这使得它成为一个对这种方式的应用来说绝佳的后台。比如动态汇总(News feed)。
7.持久性日志(commit log)
Kafka可以为一种外部的持久性日志的分布式系统提供服务。这种日志可以在节点间备份数据,并为故障节点数据回复提供一种重新同步的机制。Kafka中日志压缩功能为这种用法提供了条件。在这种用法中,Kafka类似于Apache BookKeeper项目。
5.Kafka的设计要点
1.直接使用linux 文件系统的cache,来高效缓存数据。
2.采用linux Zero-Copy提高发送性能。传统的数据发送需要发送4次上下文切换,采用sendfile系统调用之后,数据直接在内核态交换,系统上下文切换减少为2次。根据测试结果,可以提高60%的数据发送性能。Zero-Copy详细的技术细节可以参考:https://www.ibm.com/developerworks/linux/library/j-zerocopy/
3.数据在磁盘上存取代价为O(1)。kafka以topic来进行消息管理,每个topic包含多个part(ition),每个part对应一个逻辑log,有多个segment组成。每个segment中存储多条消息(见下图),消息id由其逻辑位置决定,即从消息id可直接定位到消息的存储位置,避免id到位置的额外映射。每个part在内存中对应一个index,记录每个segment中的第一条消息偏移。发布者发到某个topic的消息会被均匀的分布到多个part上(随机或根据用户指定的回调函数进行分布),broker收到发布消息往对应part的最后一个segment上添加该消息,当某个segment上的消息条数达到配置值或消息发布时间超过阈值时,segment上的消息会被flush到磁盘,只有flush到磁盘上的消息订阅者才能订阅到,segment达到一定的大小后将不会再往该segment写数据,broker会创建新的segment。
4.显式分布式,即所有的producer、broker和consumer都会有多个,均为分布式的。Producer和broker之间没有负载均衡机制。broker和consumer之间利用zookeeper进行负载均衡。所有broker和consumer都会在zookeeper中进行注册,且zookeeper会保存他们的一些元数据信息。如果某个broker和consumer发生了变化,所有其他的broker和consumer都会得到通知。
kafka简单介绍的更多相关文章
- kafka具体解释一、Kafka简单介绍
背景: 当今社会各种应用系统诸如商业.社交.搜索.浏览等像信息工厂一样不断的生产出各种信息,在大数据时代,我们面临例如以下几个挑战: 怎样收集这些巨大的信息 怎样分析它 怎样及时做到如上两点 ...
- 【Kafka】Kafka简单介绍
目录 基本介绍 概述 优点 主要应用场景 Kafka的架构 四大核心API 架构内部细节 基本介绍 概述 Kafka官网网站:http://kafka.apache.org/ Kafka是由Apach ...
- Kafka入门介绍
1. Kafka入门介绍 1.1 Apache Kafka是一个分布式的流平台.这到底意味着什么? 我们认为,一个流平台具有三个关键能力: ① 发布和订阅消息.在这方面,它类似一个消息队列或企业消息系 ...
- MQTT介绍(1)简单介绍
MQTT目录: MQTT简单介绍 window安装MQTT服务器和client java模拟MQTT的发布,订阅 MQTT: MQTT(Message Queuing Telemetry Transp ...
- Kafka设计解析(十四)Kafka producer介绍
转载自 huxihx,原文链接 Kafka producer介绍 Kafka 0.9版本正式使用Java版本的producer替换了原Scala版本的producer.本文着重讨论新版本produce ...
- storm笔记:Storm+Kafka简单应用
storm笔记:Storm+Kafka简单应用 这几天工作须要使用storm+kafka,基本场景是应用出现错误,发送日志到kafka的某个topic.storm订阅该topic.然后进行兴许处理.场 ...
- spring cloud之简单介绍
以下是来自官方的一篇简单介绍: spring Cloud provides tools for developers to quickly build some of the common patte ...
- 【转帖】Kafka入门介绍
Kafka入门介绍 https://www.cnblogs.com/swordfall/p/8251700.html 最近在看hdoop的hdfs 以及看了下kafka的底层存储,发现分布式的技术基本 ...
- [原创]关于mybatis中一级缓存和二级缓存的简单介绍
关于mybatis中一级缓存和二级缓存的简单介绍 mybatis的一级缓存: MyBatis会在表示会话的SqlSession对象中建立一个简单的缓存,将每次查询到的结果结果缓存起来,当下次查询的时候 ...
随机推荐
- 19 常用API
API 什么是API? API (Application Programming Interface) :应用程序编程接口 简单来说:就是Java帮我们已经写好的一些方法,我们直接拿过来用就可以了 1 ...
- 重新整理 .net core 实践篇————依赖注入应用[二]
前言 这里介绍一下.net core的依赖注入框架,其中其代码原理在我的另一个整理<<重新整理 1400篇>>中已经写了,故而专门整理应用这一块. 以下只是个人整理,如有问题, ...
- [转载]性能测试工具 2 步解决 too many open files 的问题,让服务器支持更多连接数
[转载]性能测试工具 2 步解决 too many open files 的问题,让服务器支持更多连接数 大话性能 · 2018年10月09日 · 最后由 大话性能 回复于 2018年10月09日 · ...
- 关于typedef的用法总结-(转自Bigcoder)
不管实在C还是C++代码中,typedef这个词都不少见,当然出现频率较高的还是在C代码中.typedef与#define有些相似,但更多的是不同,特别是在一些复杂的用法上,就完全不同了,看了网上一些 ...
- 大师画PCB板子
1.低频电路对于模拟地和数字地要分开布线,不能混用 2.如果有多个A/D转换电路,几个ADC尽量放在一起,只在尽量靠近该器件处单点接地,AGND和DGND都要接到模拟地,电源端子都要接到模拟电源端子: ...
- 程序"三高"解决方案
0. 程序三高 1. 缓存 2. 预处理和延后处理 3. 池化 3.1 内存池 3.2 线程池 3.3 连接池 4. 异步(回调) 5. 消息队列 5.1 服务解耦 5.2 异步处理 5.3 流量削峰 ...
- Linux 查看实时网卡流量的方法 网速 nload sar iftop dstat
1.使用nload yum install -y gcc gcc-c++ ncurses-devel make wgetwget http://www.roland-riegel.de/nload/n ...
- 根据swagger.json生成flutter model,暂无空安全支持
一般的服务端类型都有泛型支持,对于flutter来说虽然也支持泛型,但是在序列化这里却始终存在问题,flutter不允许用反射,对于flutter项目的开发来说除了画页面,可能最烦人的就是跟服务端打交 ...
- 人体姿态和形状估计的视频推理:CVPR2020论文解析
人体姿态和形状估计的视频推理:CVPR2020论文解析 VIBE: Video Inference for Human Body Pose and Shape Estimation 论文链接:http ...
- 实时实例分割的Deep Snake:CVPR2020论文点评
实时实例分割的Deep Snake:CVPR2020论文点评 Deep Snake for Real-Time Instance Segmentation 论文链接:https://arxiv.org ...