K8s Scheduler 在调度 pod 过程中遗漏部分节点的问题排查
问题现象
在TKE控制台上新建版本为v1.18.4(详细版本号 < v1.18.4-tke.5)的独立集群,其中,集群的节点信息如下:
有3个master node和1个worker node,并且worker 和 master在不同的可用区。
| node | 角色 | label信息 |
|---|---|---|
| ss-stg-ma-01 | master | label[failure-domain.beta.kubernetes.io/region=sh,failure-domain.beta.kubernetes.io/zone=200002] |
| ss-stg-ma-02 | master | label[failure-domain.beta.kubernetes.io/region=sh,failure-domain.beta.kubernetes.io/zone=200002] |
| ss-stg-ma-03 | master | label[failure-domain.beta.kubernetes.io/region=sh,failure-domain.beta.kubernetes.io/zone=200002] |
| ss-stg-test-01 | worker | label[failure-domain.beta.kubernetes.io/region=sh,failure-domain.beta.kubernetes.io/zone=200004] |
待集群创建好之后,再创建出一个daemonset对象,会出现daemonset的某个pod一直卡住pending状态的现象。
现象如下:
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE NODE
debug-4m8lc 1/1 Running 1 89m ss-stg-ma-01
debug-dn47c 0/1 Pending 0 89m <none>
debug-lkmfs 1/1 Running 1 89m ss-stg-ma-02
debug-qwdbc 1/1 Running 1 89m ss-stg-test-01
(补充:TKE当前支持的最新版本号为v1.18.4-tke.8,新建集群默认使用最新版本)
问题结论
k8s的调度器在调度某个pod时,会从调度器的内部cache中同步一份快照(snapshot),其中保存了pod可以调度的node信息。
上面问题(daemonset的某个pod实例卡在pending状态)的原因就是同步的过程发生了部分node信息丢失,导致了daemonset的部分pod实例无法调度到指定的节点上,卡在了pending状态。
接下来是详细的排查过程。
日志排查
截图中出现的节点信息(来自客户线上集群):
k8s master节点:ss-stg-ma-01、ss-stg-ma-02、ss-stg-ma-03
k8s worker节点:ss-stg-test-01
1、获取调度器的日志
这里首先是通过动态调大调度器的日志级别,比如,直接调大到V(10),尝试获取一些相关日志。
当日志级别调大之后,有抓取到一些关键信息,信息如下:

解释一下,当调度某个pod时,有可能会进入到调度器的抢占preempt环节,而上面的日志就是出自于抢占环节。
集群中有4个节点(3个master node和1个worker node),但是日志中只显示了3个节点,缺少了一个master节点。
所以,这里暂时怀疑下是调度器内部缓存cache中少了node info。
2、获取调度器内部cache信息
k8s v1.18已经支持打印调度器内部的缓存cache信息。打印出来的调度器内部缓存cache信息如下:




可以看出,调度器的内部缓存cache中的node info是完整的(3个master node和1个worker node)。
通过分析日志,可以得到一个初步结论:调度器内部缓存cache中的node info是完整的,但是当调度pod时,缓存cache中又会缺少部分node信息。
问题根因
在进一步分析之前,我们先一起再熟悉下调度器调度pod的流程(部分展示)和nodeTree数据结构。
pod调度流程(部分展示)
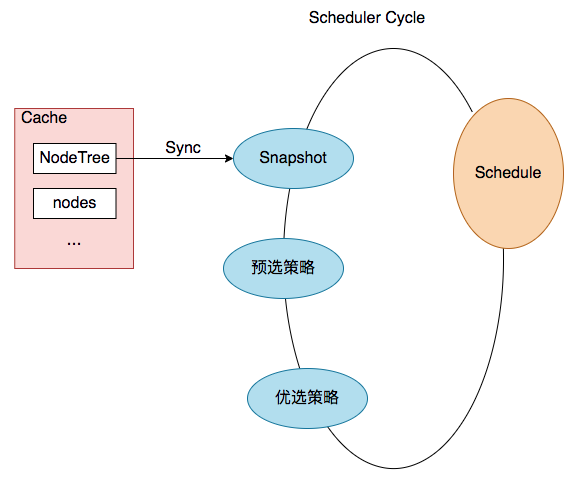
结合上图,一次pod的调度过程就是 一次Scheduler Cycle。 在这个Cycle开始时,第一步就是update snapshot。snapshot我们可以理解为cycle内的cache,其中保存了pod调度时所需的node info,而update snapshot,就是一次nodeTree(调度器内部cache中保存的node信息)到snapshot的同步过程。
而同步过程主要是通过nodeTree.next()函数来实现,函数逻辑如下:
// next returns the name of the next node. NodeTree iterates over zones and in each zone iterates
// over nodes in a round robin fashion.
func (nt *nodeTree) next() string {
if len(nt.zones) == 0 {
return ""
}
numExhaustedZones := 0
for {
if nt.zoneIndex >= len(nt.zones) {
nt.zoneIndex = 0
}
zone := nt.zones[nt.zoneIndex]
nt.zoneIndex++
// We do not check the exhausted zones before calling next() on the zone. This ensures
// that if more nodes are added to a zone after it is exhausted, we iterate over the new nodes.
nodeName, exhausted := nt.tree[zone].next()
if exhausted {
numExhaustedZones++
if numExhaustedZones >= len(nt.zones) { // all zones are exhausted. we should reset.
nt.resetExhausted()
}
} else {
return nodeName
}
}
}
再结合上面排查过程得出的结论,我们可以再进一步缩小问题范围:nodeTree(调度器内部cache)到的同步过程丢失了某个节点信息。
### nodeTree数据结构
(方便理解,本文使用了链表来展示)
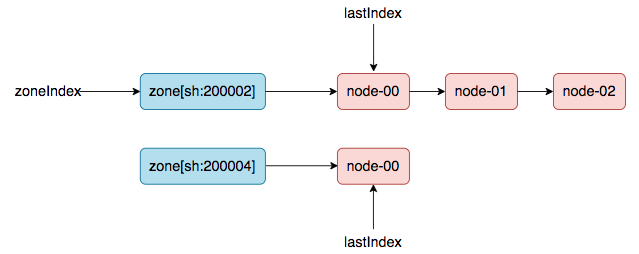
在nodeTree数据结构中,有两个游标zoneIndex 和 lastIndex(zone级别),用来控制 nodeTree(调度器内部cache)到snapshot.nodeInfoList的同步过程。并且,重要的一点是:上次同步后的游标值会被记录下来,用于下次同步过程的初始值。
### 重现问题,定位根因
创建k8s集群时,会先加入master node,然后再加入worker node(意思是worker node时间上会晚于master node加入集群的时间)。
第一轮同步:3台master node创建好,然后发生pod调度(比如,cni 插件,以daemonset的方式部署在集群中),会触发一次nodeTree(调度器内部cache)到的同步。同步之后,nodeTree的两个游标就变成了如下结果:
nodeTree.zoneIndex = 1,
nodeTree.nodeArray[sh:200002].lastIndex = 3,
第二轮同步:当worker node加入集群中后,然后新建一个daemonset,就会触发第二轮的同步(nodeTree(调度器内部cache)到的同步)。同步过程如下:
1、 zoneIndex=1, nodeArray[sh:200004].lastIndex=0, we get ss-stg-test-01.
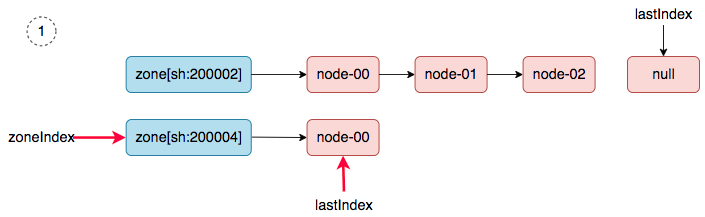
2、 zoneIndex=2 >= len(zones); zoneIndex=0, nodeArray[sh:200002].lastIndex=3, return.
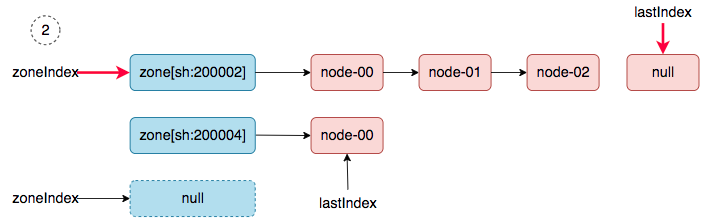
3、 zoneIndex=1, nodeArray[sh:200004].lastIndex=1, return.
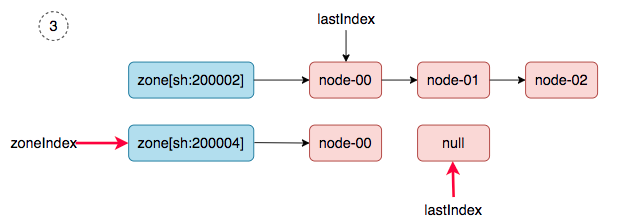
4、 zoneIndex=0, nodeArray[sh:200002].lastIndex=0, we get ss-stg-ma-01.
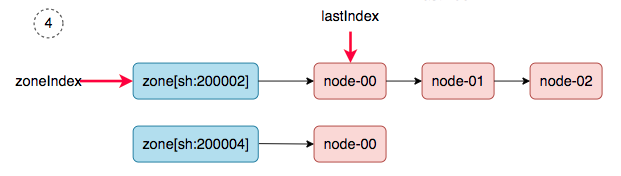
5、 zoneIndex=1, nodeArray[sh:200004].lastIndex=0, we get ss-stg-test-01.
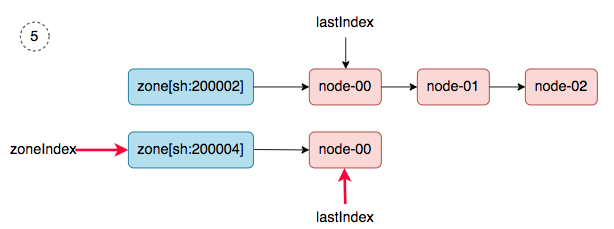
6、 zoneIndex=2 >= len(zones); zoneIndex=0, nodeArray[sh:200002].lastIndex=1, we get ss-stg-ma-02.
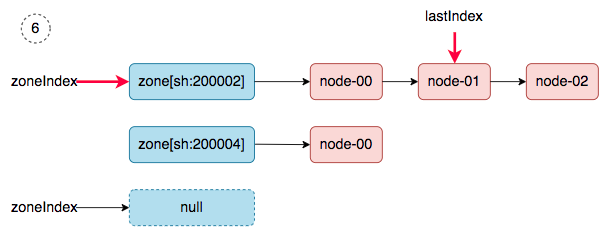
同步完成之后,调度器的snapshot.nodeInfoList得到如下的结果:
[
ss-stg-test-01,
ss-stg-ma-01,
ss-stg-test-01,
ss-stg-ma-02,
]
ss-stg-ma-03 去哪了?在第二轮同步的过程中丢了。
解决方案
从问题根因的分析中,可以看出,导致问题发生的原因,在于 nodeTree 数据结构中的游标 zoneIndex 和 lastIndex(zone级别)值被保留了,所以,解决的方案就是在每次同步SYNC时,强制重置游标(归0)。
相关issue:https://github.com/kubernetes/kubernetes/issues/97120
相关pr(k8s v1.18): https://github.com/kubernetes/kubernetes/pull/93387
TKE修复版本:v1.18.4-tke.5
K8s Scheduler 在调度 pod 过程中遗漏部分节点的问题排查的更多相关文章
- ambari过程中要求各个节点时间同步
设置时间同步 控制节点机器 cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime #设置时区为北京时间,这里为上海,因为centos里面只有上海... ...
- Kubernetes集群搭建过程中遇到的问题
1. 创建Nginx Pod过程中报如下错误: #kubectlcreate -f nginx-pod.yaml Error from server: error when creating &quo ...
- 国内不fq安装K8S四: 安装过程中遇到的问题和解决方法
目录 4 安装过程中遇到的问题和解决方法 4.1 常见问题 4.2 常用的操作命令 4.3 比较好的博客 国内不fq安装K8S一: 安装docker 国内不fq安装K8S二: 安装kubernet 国 ...
- 十五,K8S集群调度原理及调度策略
目录 k8s调度器Scheduler Scheduler工作原理 请求及Scheduler调度步骤: k8s的调用工作方式 常用预选策略 常用优先函数 节点亲和性调度 节点硬亲和性 节点软亲和性 Po ...
- k8s集群调度方案
Scheduler是k8s集群的调度器,主要的任务是把定义好的pod分配到集群节点上 有以下特征: 1 公平 保证每一个节点都能被合理分配资源或者能被分配资源 2 资源高效利用 集群所有资 ...
- k8s运维之pod排错
k8s运维之pod排错 K8S是一个开源的,用于管理云平台中多个主机上的容器化应用,Kubernetes的目标是让部署容器化变得简单并且高效 K8S的核心优势: 1,基于yaml文件实现容器的自动创建 ...
- k8s核心资源之Pod概念&入门使用讲解(三)
目录 1. k8s核心资源之Pod 1.1 什么是Pod? 1.2 Pod如何管理多个容器? 1.3 Pod网络 1.4 Pod存储 1.5 Pod工作方式 1.5.1 自主式Pod 1.5.2 控制 ...
- Cocos2d-x 3.x 学习笔记(三):Scheduler Timer 调度与定时
1. 概述 Cocos2d-x 的 Scheduler 离不开 Timer.Timer 类是定时器,用来规定一个回调函数应该在何时被触发.Timer 封装了已运行时间.重复次数.已执行次数.延迟秒数 ...
- k8s之深入解剖Pod(三)
目录: Pod的调度 Pod的扩容和缩容 Pod的滚动升级 一.Pod的调度 Pod只是容器的载体,通常需要通过RC.Deployment.DaemonSet.Job等对象来完成Pod的调度和自动控制 ...
随机推荐
- 2019HDU多校第七场 HDU6646 A + B = C 【模拟】
一.题目 A + B = C 二.分析 比较考验码力的题. 对于$c$,因为首位肯定不为0,那么$a$或者$b$至少有一个最高位是和$c$平齐的,或者少一位(相当于$a$+$b$进位得到). 那么这里 ...
- Win 10 下Pipenv源码安装 odoo12
因为,本身电脑已经安装odoo8,9,10等odoo的版本,当时,没有考虑是直接是统一的环境很配置. 现在,在odoo11的环境下,需要Python 3的语言环境可以很好地支持odoo11的功能,所以 ...
- Scientific Internet Access
下载小飞机 https://github.com/shadowsocksr-backup 寻找ssr https://github.com/Alvin9999/new-pac/wiki/ss%E5%8 ...
- 攻防世界 reverse tt3441810
tt3441810 tinyctf-2014 附件给了一堆数据,将十六进制数据部分提取出来, flag应该隐藏在里面,(这算啥子re,) 保留可显示字符,然后去除填充字符(找规律 0.0) 处理脚本: ...
- java例题_43 求0—7所能组成的奇数个数
1 /*43 [程序 43 求奇数个数] 2 题目:求 0-7 所能组成的奇数个数. 3 */ 4 5 /*分析 6 * 1.0不能作最高位且最低位只能是1,3,5,7; 7 * 2.没有限定是几位数 ...
- Android学习之CoordinatorLayout+AppBarLayout
•AppBarLayout 简介 AppbarLayout 是一种支持响应滚动手势的 app bar 布局: 基本使用 新建一个项目,命名为 TestAppBarLayout: 修改 activity ...
- Kubernetes 常用日志收集方案
Kubernetes 常用日志收集方案 学习了 Kubernetes 集群中监控系统的搭建,除了对集群的监控报警之外,还有一项运维工作是非常重要的,那就是日志的收集. 介绍 应用程序和系统日志可以帮助 ...
- 抗DDOS应急预案实践-生产环境总结-建议必看
一.首先摸清楚环境与资源 为DDoS应急预案提供支撑 所在的网络环境中,有多少条互联网出口?每一条带宽多少? 每一条互联网出口的运营商是否支持DDoS攻击清洗,我们是否购买,或可以紧急试用?当发生DD ...
- String 的不可变真的是因为 final 吗?
尽人事,听天命.博主东南大学硕士在读,热爱健身和篮球,乐于分享技术相关的所见所得,关注公众号 @ 飞天小牛肉,第一时间获取文章更新,成长的路上我们一起进步 本文已收录于 「CS-Wiki」Gitee ...
- (5)MySQL进阶篇SQL优化(优化数据库对象)
1.概述 在数据库设计过程中,用户可能会经常遇到这种问题:是否应该把所有表都按照第三范式来设计?表里面的字段到底改设置为多大长度合适?这些问题虽然很小,但是如果设计不当则可能会给将来的应用带来很多的性 ...