FP-growth算法思想和其python实现
第十二章 使用FP-growth算法高效的发现频繁项集
一.导语
FP-growth算法是用于发现频繁项集的算法,它不能够用于发现关联规则。FP-growth算法的特殊之处在于它是通过构建一棵Fp树,然后从FP树上发现频繁项集。
FP-growth算法它比Apriori算法的速度更快,一般能够提高两个数量级,因为它只需要遍历两遍数据库,它的过程分为两步:
1.构建FP树
2.利用FP树发现频繁项集
二.FP树
FP树它的形状与普通的树类似,树中的节点记录了一个项和在此路径上该项出现的频率。FP树允许项重复出现,但是它的频率可能是不同的。重复出现的项就是相似项,相似项之间的连接称之为节点连接,沿着节点连接我们可以快速的发现相似的项。
FP树中的项必须是频繁项,也就是它必须要满足Apriori算法。FP树的构建过程需要遍历两边数据库,第一遍的时候我们统计出所有项的频率,过滤掉不满足最小支持度的项;第二遍的时候我们统计出每个项集的频率。
三.构建FP树
1.要创建一棵树,首先我们需要定义树的数据结构。
这个数据结构有五个数据项,其中的parent表示父节点, children表示孩子节点, similar表示的相似项。
2.创建一棵Fp树
def createTree(dataSet, minSup=1):
headerTable = {}
# in order to catch the all the item and it's frequent
for transaction in dataSet:
for item in transaction:
headerTable[item] = headerTable.get(item, 0) + dataSet[transaction]
# delete the item which is not frequent item
for key in headerTable.keys():
if headerTable[key] < minSup:
del(headerTable[key])
frequentSet = headerTable.keys()
# if the frequentSet is empty, then we can finish the program early
if len(frequentSet) == 0:
return None, None
# initialize the begin link of headerTable is None
for key in headerTable.keys():
headerTable[key] = [headerTable[key], None]
# initialize the fp-tree
retTree = treeNode("RootNode", 1, None)
# rearrange the transaction and add the transaction into the tree
for transData, times in dataSet.items():
arrangeTrans = {}
for item in transData:
if item in frequentSet:
arrangeTrans[item] = headerTable[item][0]
if len(arrangeTrans)>0:
sortTrans = [v[0] for v in sorted(arrangeTrans.items(), key=lambda p:p[1], reverse=True)]
updateTree(sortTrans, retTree, headerTable, times)
return headerTable, retTree
def updateTree(sortTrans, retTree, headerTable, times):
if sortTrans[0] in retTree.children:
retTree.children[sortTrans[0]].inc(times)
else:
retTree.children[sortTrans[0]] = treeNode(sortTrans[0], times, retTree)
if headerTable[sortTrans[0]][1] == None:
headerTable[sortTrans[0]][1] = retTree.children[sortTrans[0]]
else:
updateHeader(headerTable[sortTrans[0]][1], retTree.children[sortTrans[0]])
if len(sortTrans) > 1:
updateTree(sortTrans[1::], retTree.children[sortTrans[0]], headerTable, times)
def updateHeader(nodeToTest, targetNode):
while nodeToTest.similarNode != None:
nodeToTest = nodeToTest.similarNode
nodeToTest.similarNode = targetNode
四.从一棵FP树中挖掘频繁项集
从一棵FP树中挖掘频繁项集需要三个步骤,首先我们需要找到所有的条件模式基,其次是根据条件模式基创建一棵条件FP树,最后我们不断的重复前两个步骤直到树只包含一个元素项为止
首先我们要寻找条件模式基,那么什么是条件模式基呢?所谓的条件模式基就是以查找元素结尾的所有路径的集合。我们可以根据headertable中的nodelink来找到某一个元素在树中的所有位置,然后根据这些位置进行前缀路径的搜索。以下是它的python代码:
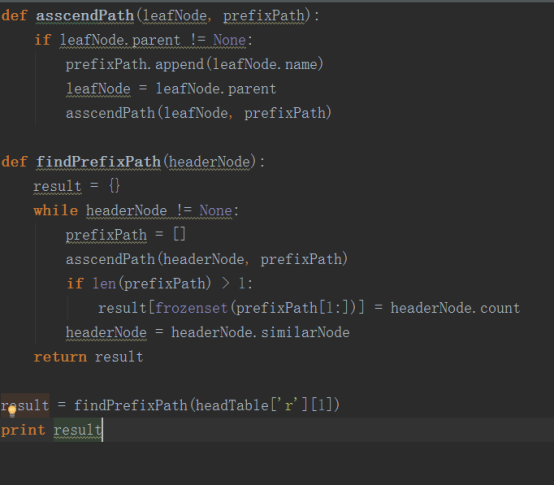
现在我们知道了如何找条件模式基,接下来就是创建一个FP条件树。在创建树之前我们首先要知道什么是FP条件树,所谓的FP条件树就是将针对某一个条件的条件模式基构建的一棵FP树。以下是python代码
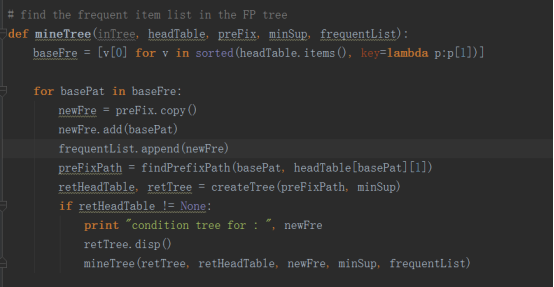
五.一个浏览新闻共现的例子
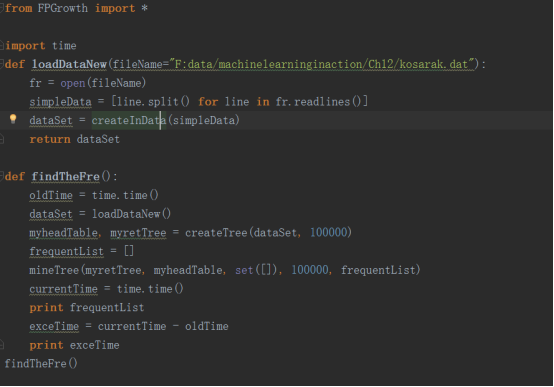
korasa.dat中有100万条数据,我们需要从这一百万条数据中知道最小支持度为100000的频繁项集。如果采用Apriori算法时间非常的长,我等了好几分钟还没出结果,就不等了。
然后采用本节的FP-growth算法只用了11秒多就算完了。以下是具体的代码
六.总结
FP-growth算法作为一种专门发现频繁项集的算法,比Apriori算法的执行效率更高。它只需要扫描数据库两遍,第一遍是为了找到headerTable,也就是找到所有单个的频繁项。第二遍的时候是为了将每一个事务融入到树中。
发现频繁项集是非常有用的操作,经常需要用到,我们可以将其用于搜索,购物交易等多种场景。
FP-growth算法思想和其python实现的更多相关文章
- Frequent Pattern 挖掘之二(FP Growth算法)(转)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达到这样的效果,它采用了一种简洁的数据结 ...
- FP—Growth算法
FP_growth算法是韩家炜老师在2000年提出的关联分析算法,该算法和Apriori算法最大的不同有两点: 第一,不产生候选集,第二,只需要两次遍历数据库,大大提高了效率,用31646条测试记录, ...
- 关联规则算法之FP growth算法
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达到这样的效果,它采用了一种简洁的数据结 ...
- Frequent Pattern (FP Growth算法)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达 到这样的效果,它采用了一种简洁的数据 ...
- Frequent Pattern 挖掘之二(FP Growth算法)
Frequent Pattern 挖掘之二(FP Growth算法) FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断 ...
- 机器学习(十五)— Apriori算法、FP Growth算法
1.Apriori算法 Apriori算法是常用的用于挖掘出数据关联规则的算法,它用来找出数据值中频繁出现的数据集合,找出这些集合的模式有助于我们做一些决策. Apriori算法采用了迭代的方法,先搜 ...
- Apriori算法思想和其python实现
第十一章 使用Apriori算法进行关联分析 一.导语 "啤酒和尿布"问题属于经典的关联分析.在零售业,医药业等我们经常需要是要关联分析.我们之所以要使用关联分析,其目的是为了从大 ...
- 机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理)
前言: 找工作时(IT行业),除了常见的软件开发以外,机器学习岗位也可以当作是一个选择,不少计算机方向的研究生都会接触这个,如果你的研究方向是机器学习/数据挖掘之类,且又对其非常感兴趣的话,可以考虑考 ...
- paper 17 : 机器学习算法思想简单梳理
前言: 本文总结的常见机器学习算法(主要是一些常规分类器)大概流程和主要思想. 朴素贝叶斯: 有以下几个地方需要注意: 1. 如果给出的特征向量长度可能不同,这是需要归一化为通长度的向量(这里以文本分 ...
随机推荐
- 【Unity Shaders】Using Textures for Effects——让sprite sheets动起来
本系列主要参考<Unity Shaders and Effects Cookbook>一书(感谢原书作者),同时会加上一点个人理解或拓展. 这里是本书所有的插图.这里是本书所需的代码和资源 ...
- (NO.00003)iOS游戏简单的机器人投射游戏成形记(十四)
我们首先必须将Level中所有机器人保存在某个数组里,因为该数组会在不同地方被访问,我们将其放在LevelRestrict类中,按道理应该放到GameState类中,这里从简. 打开LevelRest ...
- Let the Balloon Rise HDU 1004
Let the Balloon Rise Time Limit : 2000/1000ms (Java/Other) Memory Limit : 65536/32768K (Java/Other ...
- 朴素贝叶斯分类法 Naive Bayes ---R
朴素贝叶斯算法 [转载时请注明来源]:http://www.cnblogs.com/runner-ljt/ Ljt 勿忘初心 无畏未来 作为一个初学者,水平有限,欢迎交流指正. 朴素贝叶斯分类法 ...
- Android Widget 开发详解(二) +支持listView滑动的widget
转载请标明出处:http://blog.csdn.net/sk719887916/article/details/47027263 不少开发项目中都会有widget功能,别小瞧了它,他也是androi ...
- mysql进阶(十九)SQL语句如何精准查找某一时间段的数据
SQL语句如何精准查找某一时间段的数据 在项目开发过程中,自己需要查询出一定时间段内的交易.故需要在sql查询语句中加入日期时间要素,sql语句如何实现? SELECT * FROM lmapp.lm ...
- iOS中NSBundle的介绍
bundle是一个目录,其中包含了程序会使用到的资源.这些资源包含了如图像,声音,编译好的代码,nib文件(用户也会把bundle称为plug-in).对应bundle,cocoa提供了类NSBund ...
- github搭建个人网站
1. 注册账号: 地址: https://github.com/ 输入账号.邮箱.密码,然后点击注册按钮. 2. 初始设置 注册完成后,选择Free免费账号完成设置. 2.1 验证邮箱 请打开你的 ...
- RTMPdump(libRTMP) 源代码分析 8: 发送消息(Message)
===================================================== RTMPdump(libRTMP) 源代码分析系列文章: RTMPdump 源代码分析 1: ...
- Volley网络框架完全解析(实战篇)
好了,今天就通过一个瀑布流demo,来使用Volley框架请求网络图片. 前言: 我们使用NetworkImageView显示图片: 1.因为该控件可以自动的管理好请求的生命周期,当与父控件detac ...