WordCount项目基本功能
一、项目源代码地址
本人Gitee项目地址:https://gitee.com/yuliu10/WordCount
二、PSP表格
| psp阶段 |
预估耗时 (分钟) |
实际耗时 (分钟) |
| 计划 | 30 | 10 |
| 估计这个任务需要多少时间 | 20 | 20 |
| 开发 | 600 | 660 |
| 需求分析 (包括学习新技术) | 40 | 60 |
| 生成设计文档 | 60 | 30 |
| 设计复审 (和同事审核设计文档) | 30 | 20 |
| 代码规范 | 10 | 0 |
| 具体设计 | 50 | 30 |
| 具体编码 | 500 | 600 |
| 基本功能实现 | 150 | 200 |
| 扩展功能实现 | 350 | 400 |
| 测试(自我测试,修改代码,提交修改) | 60 | 50 |
| 报告 | 300 | 300 |
| 代码复审 | 30 | 20 |
| 测试报告 | 60 | 120 |
| 计算工作量 | 5 | 5 |
| 事后总结, 并提出过程改进计划 | 10 | 10 |
| 合计 | ||
三、解题思路
在拿到题目之后,自己仔细阅读了老师给的任务,一开始觉得文本的行数、字数、单词数的统计没多大问题,后来在写代码的过程中,才发现难点在于命令行,因为自己以前并没有做过此类的练习,所以一片茫然,在搜集过很多资料以后才又继续开始了。
总结了一下自己在编程之前的思考以及解决方案:
♦用什么语言好呢?
自己学过C#,java,C,但是在涉及到命令行的解释是一大盲区,之前看到过某同学写的有关C语言main函数两个参数argc、argv的文章,于是就参考着用C语言写了。
♦如何获取命令行一长串的字符呢?
argc是指从命令行输入的参数个数,包括固定的本文件的路径argv[0],char* argv[]是一个指针数组,index是从0开始的,0存的是本文件的绝对路径,1存的是控制台输入的第一个参数,以此类推,因此控制台输入的命令就存在argv里面。
♦如何对获取到的命令行进行解析呢(即对哪个文件进行操作、有哪些不同的选项)?
根据习惯,命令行的格式是 wc.exe [para] <filename>,有三个选项可供选择,如何将不同数量的选择与相应的文件对应起来呢,最后想到的是用结构体(struct Node)来标注每一个file的各个状态(是否有-l选项、是否有-w选项、是否有-c选项、输入文件的名字、行数row、字符数characters、字数words),这样一来,节点Node里面包含了要处理的文件的所有信息,要处理某个选项就调用对应的写好的函数即可。
♦如何处理多文件呢?
根据习惯,命令行的格式是wc.exe [para] <filename> [para] <filename>,用链表将不同的file节点串起来,每个文件是独立的,因此可以将文件名和文件要执行的操作封装在结构体里面。
参考链接:
有关main函数的两个命令行参数argc、argv详细解释参见:
https://blog.csdn.net/theLostLamb/article/details/79304203
原本以为在把基础功能做好以后,还能把扩展功能做一做,后来发现自己还是太年轻了,一个基础功能就快要了我的小命(我滴中秋啊啊啊)。
四、程序设计过程
大致思路就是先实现统计行数、单词数、字符数各个模块的功能,封装在每一个函数里面。这个比较简单,使用简单的累加就可以实现。后来碰到命令行的解释,就将之前的全部推翻了,用上了结构体。先获取命令行的参数,用 strcat函数对字符串进行拼接成commandStr,这个过程在main函数里面直接实现,其次是对commandStr进行解析,将文件的名字以及对应的选项提取出来放在一个Node里面,每一个文件为一个单独的Node,每个Node用链表串起来。Node有了以后,就可以根据里面保存的信息对文件进行相应的操作了!
设计模块包括:
- init():对Node节点进行初始化
- analysis():对获取的命令行字符串进行解析
- counLine():统计行数
- countWords():统计单词个数
- countChars():统计字符数
五、代码说明
根据我的开发过程,逐步阐述我的代码:
struct Node {
//可供选择的三个选项
bool _l;
bool _c;
bool _w;
char inputFile[]; //作为输入的文件名
int row;
int words;
int character;
struct Node *next;//指向下一个结点的指针
};
void init(struct Node *node) {
node->_l = false;
node->_c = false;
node->_w = false;
//将inputfile变为空(全0)
memset(node->inputFile, , sizeof(node->inputFile));
node->row = ;
node->words = ;
node->character = ;
node->next = NULL;
}
以上代码段为节点的定义和初始化,用一个节点来存放一个文件的所有信息,为每个节点的信息赋默认初值,以便于后面对命令行解析以后更新其中的状态。
void analysis(struct Node *Head, char commandStr[]) {
init(Head);
struct Node *cur;
cur = Head;
// 对这个字符串进行遍历,依次分析
for (int i = ;; i++) {
char c = commandStr[i]; // c是当前遍历到哪个字符了
if (c == ) {
// 读到'\0'代表读到了字符串末尾
return;
}
else if (c == ' ') {
continue;
}
else if (c == '-') {
/*
如果读到了-
就说明这是一个选项
那么我应该解析它后面的那一个字符,判断是哪种选项,是l,w还是c
*/
i++; // 先让i往后移一位,代表i指向-后面的参数
c = commandStr[i]; // 现在将选项读取出来了
// 接下来就是判断是哪种操作
if (c == 'l') {
// 这里判断出了有统计行数这个选项
// 接下来应该是指定当前文件有这一操作
cur->_l = true;
continue;
}
else if (c == 'w') {
cur->_w = true;
continue;
}
else if (c == 'c') {
cur->_c = true;
continue;
}
else if (c == 'o') {
// 如果-后面是o,则表示要将结果保存在指定文件里面
// 根据规则,-o后面要紧跟一个输出的文件名
// -o res.txt
i += ;
char path[] = "";
for (int j = ;; j++) {
char ch = commandStr[i++];
if (ch == ' ') {
break;
}
path[j] = ch;
}
// 把原来的result.txt擦出掉
memset(outputFile, , sizeof(outputFile));
// 把新的文件名放进去
strcpy(outputFile, path);
}
else {
printf("after - must a para");
exit(-);
}
}
else {
// 如果既不是0,又不是-, 也不是空格
// 那么就认为它是文件名字的开头
char path[] = "";
// 遍历每一个字符,存放在path里面
for (int j = ;; j++) {
char ch = commandStr[i++];
if (ch == ' ') {
break;
}
path[j] = ch;
}
// 将path复制到当前文件的输入文件中
strcpy(cur->inputFile, path);
// 这一步结束以后
// 我已经得到了当前的文件名和这个文件要执行哪些操作
// 因此这个文件统计完毕,进行下一个文件的统计
// wc.exe -l -w -c file1.c -l -w file2.c -o res.txt
if (commandStr[i] != ) {
if (commandStr[i + ] != 'o') {
// 如果字符串还没有结束,就new一个新的结点
// 并让当前节点指向新的节点
struct Node *node;
node = (struct Node *)malloc(sizeof(struct Node));
init(node);
cur->next = node;
cur = node;
}
i--;
}
}
}
}
以上代码段是对命令行进行解释,是整个项目最核心的代码部分,对传进来的commandStr参数的每个字符一个一个进行遍历,如果遍历到‘\0’这个字符时,代表解析完毕,如果读到‘ ’空格继续解析,如果读到‘-’这个字符,判断下一个字符是‘l’、‘c’、‘w’中的哪一个选项,则对应给结构体中的响应变量做上标记,如若之后是‘o’字符,则后面要紧跟一个指定的输出文件,若后面没有指定文件,或指定文件不在当前文件下,就会报错“write file failure”,btw,如果没有“-o”选项,就默认输出到result.txt。如果遍历到的 字符既不是‘\0’,也不是‘ ’,也不是‘-’,就说明遍历到文件名了,将文件名保存下来,并将默认的输出文件更改成保存下来的文件名。继续往后遍历,还未碰到‘\0’字符表明还有其他文件,则创建新的节点,继续以上同样的操作。
void countLine(struct Node *node) {
// 将当前正在处理的文件节点传进来,进行统计字符
// 如果没有读到文件末尾
// 就一直执行
while (!feof(rp)) {
// 读取文件中的一个字符
if (fgetc(rp) == '\n') {
node->row++;
}
}
node->row++;
rewind(rp);
fprintf(wp, "%s,row:%d\n", node->inputFile, node->row);
}
以上代码段是对文本的行数进行统计,并将统计到的数据输出在指定文件。
void countWords(struct Node *node) {
// 统计单词个数
char c;
int flag = ;
while (!feof(rp)) {
c = fgetc(rp);
if (flag == ) {
if (c != ' ') {
node->words++;
flag = ;
}
}
else if (c == ' ' || c == '\n') {
flag = ;
}
}
rewind(rp);
fprintf(wp, "%s,words:%d\n", node->inputFile, node->words);
}
以上代码段是对文本的单词个数进行统计,并将统计到的数据输出在指定文件。
void countChars(struct Node *node) {
while (!feof(rp)) {
if (fgetc(rp)) {
node->character++;
}
}
node->character--;
rewind(rp);
fprintf(wp, "%s,character:%d\n", node->inputFile, node->character);
}
以上代码段是对文本的字符数进行统计,并将统计到的数据输出在指定文件。
int main(int argc, char *argv[]) {
// 命令刚开始是在argv数组里面的
// 可以将命令拼接成一个字符串
// 把这个字符串传到一个解析函数里面解析一下
// 将解析的对应结果放在结构体里面
char commandStr[] = "";
for (int i = ; i < argc; i++) {
strcat(commandStr, argv[i]);
strcat(commandStr, " ");
}
// 将拼接好的字符串传到分析函数里面进行分析
// 分析函数需要接受命令字符串作为参数
// 另外还需要接受一个头结点
struct Node Head;
analysis(&Head, commandStr);
// 接下来要做的是打开文件
if ((wp = fopen(outputFile, "w+")) == NULL) {
printf("write file failure");
exit(-);
}
struct Node *cur;
cur = &Head;
while (cur != NULL) {
if ((rp = fopen(cur->inputFile, "r")) == NULL) {
printf("read file failure");
exit(-);
}
if (cur->_l) {
countLine(cur);
}
if (cur->_w) {
countWords(cur);
}
if (cur->_c) {
countChars(cur);
}
cur = cur->next;
}
system(“pause”);
return ;
}
以上代码段是整个代码的入口main函数,先获取命令行参数commandStr,创建一个当前节点cur,再调用analysis()函数对传进去的命令行commandStr进行解析,用节点进行标注,通过标注的信息打开对应的文件,根据不同的选项进行不同的统计操作,最后将数据输出到指定文件中。
以上是对各个代码段的解释说明,完整的代码链接:
https://gitee.com/yuliu10/WordCount
六、测试设计过程
在此次的项目中,我写了一个批处理文件对饿哦的项目进行测试,这样可以确保每个功能函数能够正常运行。众所周知,测试的高风险点包括代码中包含分支判定及循环的位置,因此,在测试中采用的覆盖方法覆盖到了所有程序代码语句,用以应对高风险点。以下是代码展示:
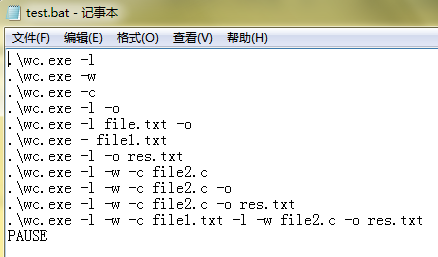
测试后的结果截图如下:
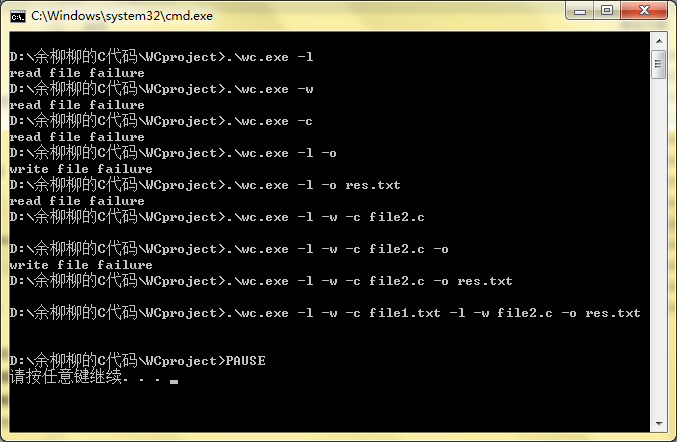
文件输出后的结果:

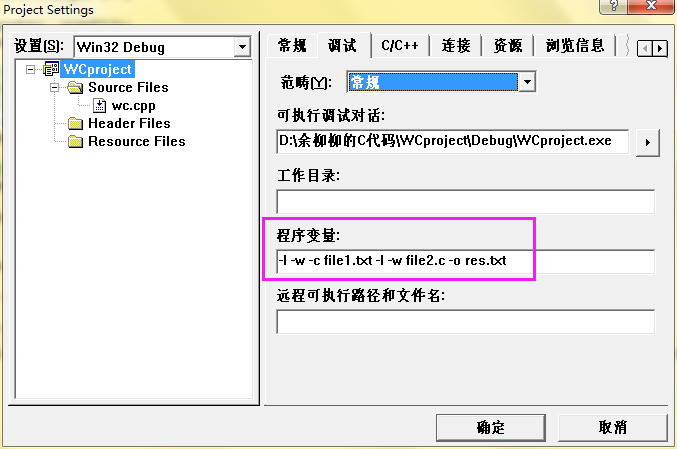
这里注明一下:我是用VC++6.0进行调试的,因为这个祖传的编译器太老了,在运行的之后不能从控制台输入参数。若要进行调试,具体在vc6.0中按如下步骤: 工程->设置->调试->程序变量,在此输入参数:
七、参考文献链接
有关博客的使用和排版,范飞龙老师的这篇博客:http://www.cnblogs.com/math/p/se-tools-001.html
邹欣老师在《构建之法》中设计的第一项个人作业:http://www.cnblogs.com/xinz/p/7426280.html
有关main函数的两个命令行参数argc、argv详细解释参见:https://blog.csdn.net/theLostLamb/article/details/79304203
如何在VC++6.0环境中运行带参main函数:https://blog.csdn.net/weiqiang_huang/article/details/17124255
WordCount项目基本功能的更多相关文章
- [ASP.NET MVC] 使用CLK.AspNet.Identity提供依权限显示选单项目的功能
[ASP.NET MVC] 使用CLK.AspNet.Identity提供依权限显示选单项目的功能 CLK.AspNet.Identity CLK.AspNet.Identity是一个基于ASP.NE ...
- JS实现项目查找功能
又是好久没有更新文章了,技术差,人又懒是重罪啊!! 在工作中每天都要查找目前正在接手的项目,而如果项目一多起来怎么办呢? 最近主管突然说要找一下以前的项目改一点BUG,然后我就找了半天才找到对应的文件 ...
- 做项目单个功能的时候要理解需求和sql语句。
做项目单个功能的时候要理解需求和sql语句.最好直接按照给出来的sql语句或者存储过程来写,避免有极其细微的差别所造成的不同. 做宜春国税二期的时候有个功能叫夜间开票情况,钻取明细时由于没理解sql语 ...
- hadoop-eclipse插件编译及windows下运行wordcount项目
参考文章:http://www.360doc.com/content/16/0227/18/10529016_537828949.shtml, 配置修改:http://blog.csdn.net/lo ...
- OpenDaylight开发hello-world项目之功能实现
OpenDaylight开发hello-world项目之开发环境搭建 OpenDaylight开发hello-world项目之开发工具安装 OpenDaylight开发hello-world项目之代码 ...
- iOS开源项目MobileProject功能点介绍
一:MobileProject简介 MobileProject项目是一个以MVC模式搭建的开源功能集合,基于Objective-C上面进行编写,意在解决新项目对于常见功能模块的重复开发,MobileP ...
- 团队项目——特定功能NABC
我们要做的项目是截屏软件,目前决定做电脑端的应用 我觉得这个软件应该具有随意截屏的功能,就是可以用鼠标拖动线条,只要形成闭合图形就可以将线条内的图像截取出来: NABC模型: N(Need): 许多人 ...
- 软件工程:java实现wc项目基本功能
项目相关要求 项目地址:https://github.com/xiawork/wcwork 实现一个统计程序,它能正确统计程序文件中的字符数.单词数.行数,以及还具备其他扩展功能,并能够快速地处理多个 ...
- 用MVC5+EF6+WebApi 做一个小功能(四) 项目分层功能以及文件夹命名
在上一节,我们完成了一个项目搭建,我们看到的是一个项目的分层架子,那接下来每一层做什么以及需要引用哪些内容呢?在本节内容我们还逐步拆分每一层的功能,顺带添加package包 Trump.Domain ...
随机推荐
- 【极简版】SpringBoot+SpringData JPA 管理系统
前言 只有光头才能变强. 文本已收录至我的GitHub仓库,欢迎Star:https://github.com/ZhongFuCheng3y/3y 在上一篇中已经讲解了如何从零搭建一个SpringBo ...
- 给女朋友讲解什么是Optional【JDK 8特性】
前言 只有光头才能变强 前两天带女朋友去图书馆了,随手就给她来了一本<与孩子一起学编程>的书,于是今天就给女朋友讲解一下什么是Optional类. 至于她能不能看懂,那肯定是看不懂的.(学 ...
- Asp.Net Core 轻松学-多线程之Task(补充)
前言 在上一章 Asp.Net Core 轻松学-多线程之Task快速上手 文章中,介绍了使用Task的各种常用场景,但是感觉有部分内容还没有完善,在这里补充一下. 1. 任务的等待 在使用 ...
- 痞子衡嵌入式:超级好用的可视化PyQt GUI构建工具(Qt Designer)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是PyQt GUI构建工具Qt Designer. 痞子衡开博客至今已有好几年,一直以嵌入式开发相关主题的文章为主线,偶尔穿插一些其他技术 ...
- ParameterizedType理解笔记
首先分享这篇文章<ParameterizedType详解> https://blog.csdn.net/JustBeauty/article/details/81116144 Parame ...
- 学习web的第二天
之前因为技能大赛的原因,导致我这门课没有上.其实上学期是开Dreamweaver网页制作的课程的,所以老师讲的很快.我就利用课后时间去补漏,今天讲了HTML标签:1.标题标签<h1>~&l ...
- Powershell-查询当前文件目录层级结构
日常工作中我们往往有需要导出当前共享环境或磁盘文件目录层级结构等的需求,最早在目录少的情况下我们使用CMD下tree 命令可以很清晰的看到目录.文件层级结构,那么我们又如何通过powershell直观 ...
- 基于HTTP协议的几种实时数据获取技术
原文链接https://www.cnblogs.com/xrq730/p/9280404.html,作者博客园----五月的仓颉,转载请注明出处,谢谢 HTTP协议 HTTP协议大家都很熟悉了,开始本 ...
- 我的那些年(9)~我来团队了,Mvc兴起了
回到目录 我的那些年(9)~我来团队了,Mvc兴起了 在一次后出办事后直接去面试了 面试就是答卷子 六里桥一个好地址 搬回老家了 在老婆的建议下学驾照了 拿到大专毕业证了 买车了 愉一切可以愉的时间学 ...
- 秋招已过,各大厂的面试题分享一波 附C++实现
数据结构和算法是面试的一座大山,尤其去面试大厂更是必不可少!简单说明一下为啥喜欢考数据结构和算法,首先,算法有用也没用,如果是中小型企业的简单业务逻辑,可能用不到啥算法,但大厂一定会用到,都知道数据库 ...