缓冲区(buffer)与缓存(cache)
下面介绍缓冲区的知识。
一、什么是缓冲区
缓冲区(buffer),它是内存空间的一部分。也就是说,在内存空间中预留了一定的存储空间,这些存储空间用来缓冲输入或输出的数据,这部分预留的空间就叫做缓冲区,显然缓冲区是具有一定大小的。
缓冲区根据其对应的是输入设备还是输出设备,分为输入缓冲区和输出缓冲区。
二、为什么要引入缓冲区
我们为什么要引入缓冲区呢?
高速设备与低速设备的不匹配,势必会让高速设备花时间等待低速设备,我们可以在这两者之间设立一个缓冲区。
缓冲区的作用:
1.可以解除两者的制约关系,数据可以直接送往缓冲区,高速设备不用再等待低速设备,提高了计算机的效率。例如:我们使用打印机打印文档,由于打印机的打印速度相对较慢,我们先把文档输出到打印机相应的缓冲区,打印机再自行逐步打印,这时我们的CPU可以处理别的事情。
2.可以减少数据的读写次数,如果每次数据只传输一点数据,就需要传送很多次,这样会浪费很多时间,因为开始读写与终止读写所需要的时间很长,如果将数据送往缓冲区,待缓冲区满后再进行传送会大大减少读写次数,这样就可以节省很多时间。例如:我们想将数据写入到磁盘中,不是立马将数据写到磁盘中,而是先输入缓冲区中,当缓冲区满了以后,再将数据写入到磁盘中,这样就可以减少磁盘的读写次数,不然磁盘很容易坏掉。
简单来说,缓冲区就是一块内存区,它用在输入输出设备和CPU之间,用来存储数据。它使得低速的输入输出设备和高速的CPU能够协调工作,避免低速的输入输出设备占用CPU,解放出CPU,使其能够高效率工作。
三、缓冲区的类型
缓冲区 分为三种类型:全缓冲、行缓冲和不带缓冲。
1、全缓冲
在这种情况下,当填满标准I/O缓存后才进行实际I/O操作。全缓冲的典型代表是对磁盘文件的读写。
2、行缓冲
在这种情况下,当在输入和输出中遇到换行符时,执行真正的I/O操作。这时,我们输入的字符先存放在缓冲区,等按下回车键换行时才进行实际的I/O操作。典型代表是键盘输入数据。
3、不带缓冲
也就是不进行缓冲,标准出错情况stderr是典型代表,这使得出错信息可以直接尽快地显示出来。
四、缓冲区的刷新
下列情况会引发缓冲区的刷新:
- 缓冲区满时;
- 关闭文件。
可见,缓冲区满或关闭文件时都会刷新缓冲区,进行真正的I/O操作。
大家要仔细理解缓冲区刷新的意思,刷新字面上的意思是用刷子刷,把原来旧的东西变新了,这里就是改变的意思,例如像缓冲区溢出的时候,多余出来的数据会直接将之前的数据覆盖,这样缓冲区里的数据就发生了改变。
比如在Linux下,操作命令行就属于常见的行缓冲模式 输入一行命令例如ls,命令ls就会进入到缓冲区内,不输入回车的话,什么也不会发生,当输入回车就会执行真正的IO操作
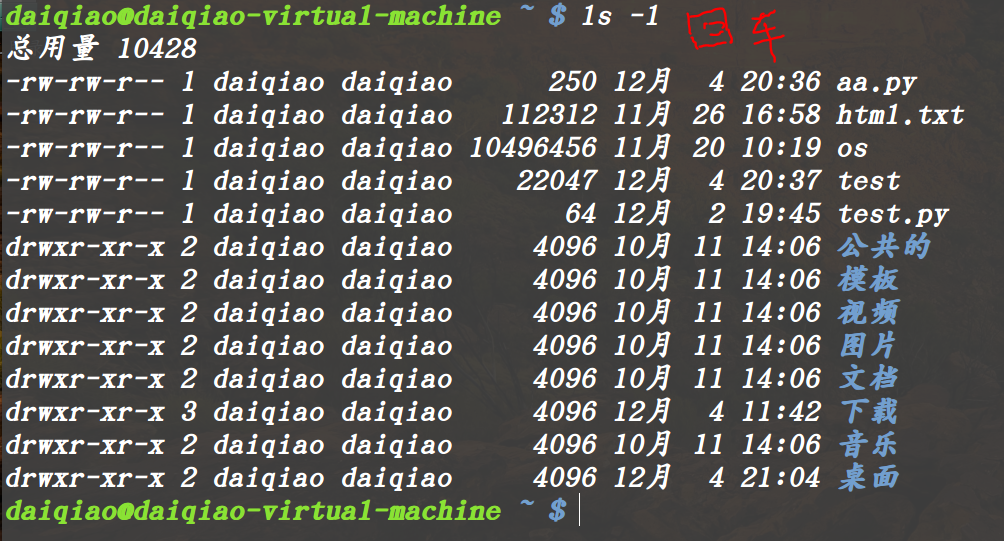
还有一种情况,并不需要输入回车。
例如在vim的正常模式下,输入dd可以直接删除某一行,并不需要输入回车。这种情况貌似就是直接把信号传送到内存中。
我个人的想法是:键盘把dd输入到缓冲区,然后vim直接就从缓冲区把数据读出来了,不需要人为的干预,当然这只是我个人的假想( ╯□╰ )。
关于缓冲区的大小:
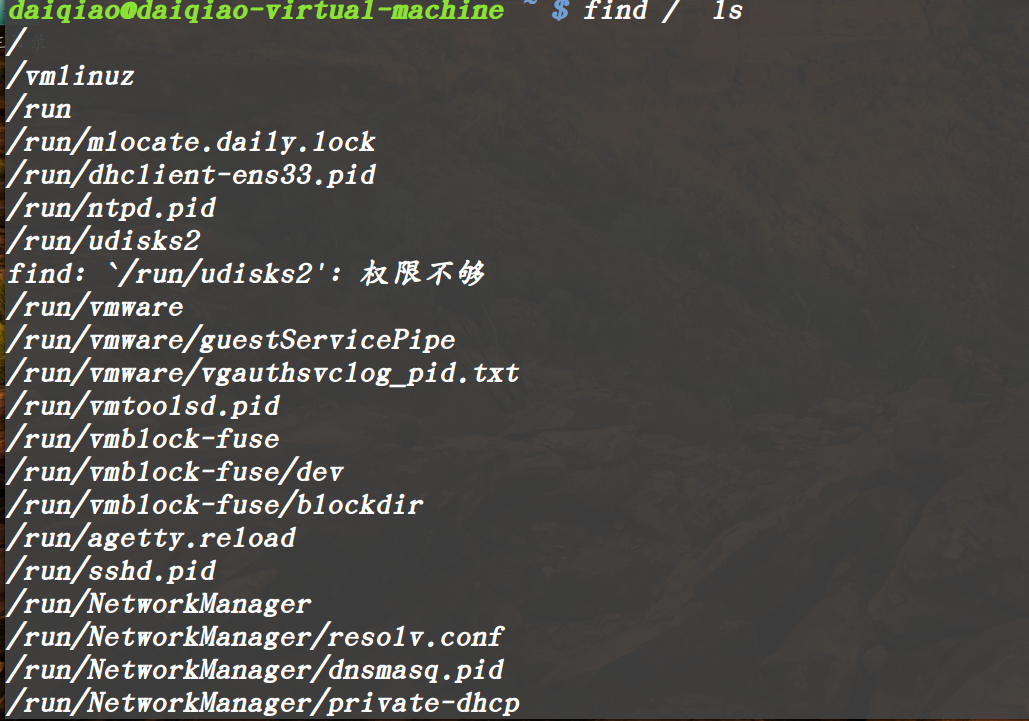
在这种情况下,输出的信息特别多,我们可以通过滑动条来进行上下移动。这种情况属于缓冲区比较大的情况。
在真正的linux终端下:
执行find / ls 命令的话。
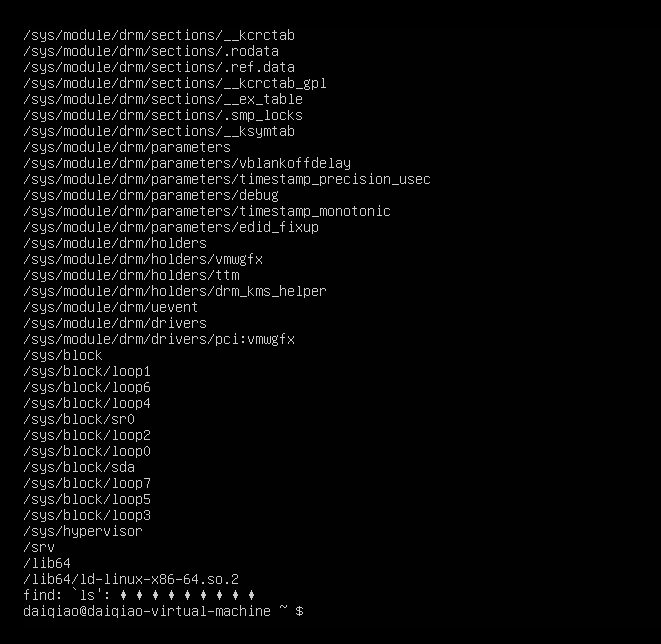
只能显示最后几行,因为在linux终端的缓冲区很小,出现了缓冲区溢出的现象,缓冲区里的数据被直接覆盖了。
为此linux提供了管道符 | 与less,more组合,可以一页一页的查看。
缓存(cache)
cache是一个非常大的概念。
一、
CPU的Cache,它中文名称是高速缓冲存储器,读写速度很快,几乎与CPU一样。由于CPU的运算速度太快,内存的数据存取速度无法跟上CPU的速度,所以在cpu与内存间设置了cache为cpu的数据快取区。当计算机执行程序时,数据与地址管理部件会预测可能要用到的数据和指令,并将这些数据和指令预先从内存中读出送到Cache。一旦需要时,先检查Cache,若有就从Cache中读取,若无再访问内存,现在的CPU还有一级cache,二级cache。简单来说,Cache就是用来解决CPU与内存之间速度不匹配的问题,避免内存与辅助内存频繁存取数据,这样就提高了系统的执行效率。
二、
磁盘也有cache,硬盘的cache作用就类似于CPU的cache,它解决了总线接口的高速需求和读写硬盘的矛盾以及对某些扇区的反复读取。
三、
浏览器缓存(Browser Caching)是为了节约网络的资源加速浏览,浏览器在用户磁盘上对最近请求过的文档进行存储,当访问者再次请求这个页面时,浏览器就可以从本地磁盘显示文档,这样就可以加速页面的阅览,并且可以减少服务器的压力。这个过程与下载非常类似,不过下载是用户的主动过程,并且下载的数据一般是长时间保存,游览器的缓存的数据只是短时间保存,可以人为的清空
四、
同样cache也有大小,例如现在市面上购买的CPU的cache越大,级数越多,CPU的访问速度越快。cache在很多方面都有应用,就不一一列举了。
缓存(cache)与缓冲(buffer)的主要区别
Buffer的核心作用是用来缓冲,缓和冲击。比如你每秒要写100次硬盘,对系统冲击很大,浪费了大量时间在忙着处理开始写和结束写这两件事嘛。用个buffer暂存起来,变成每10秒写一次硬盘,对系统的冲击就很小,写入效率高了,日子过得爽了。极大缓和了冲击。
Cache的核心作用是加快取用的速度。比如你一个很复杂的计算做完了,下次还要用结果,就把结果放手边一个好拿的地方存着,下次不用再算了。加快了数据取用的速度。
简单来说就是buffer偏重于写,而cache偏重于读。
缓冲区(buffer)与缓存(cache)的更多相关文章
- 缓冲区(buffer)与缓存(cache) 缓冲:缓解冲击,缓存:临时存储
缓存与缓冲区 简要概述 缓存(cache):故名思意就是临时存储一下数据的存储器,其他设备可能等下还用的到数据.缓存区可以用来做缓冲区 缓冲区(Buffer):故名意思就是解决设备之间速度不匹配的问题 ...
- 缓冲区Buffer和缓存区Cache的区别
1.buffer 将数据写入到内存里,这个数据的内存空间在Linux系统里一般被称为缓冲区(buffer),例如:写入到内存buffer缓冲区,即写缓冲. 为了提高写操作性能,数据在写入最终介质或下一 ...
- 缓冲 buffer 和缓存 cache 的区别
缓存(cache)是在读取硬盘中的数据时,把最常用的数据保存在内存的缓存区中,再次读取该数据时,就不去硬盘中读取了,而在缓存中读取. 缓冲(buffer)是在向硬盘写入数据时,先把数据放入缓冲区,然后 ...
- POCO库——Foundation组件之缓存Cache
缓存Cache:内部提供多种缓存Cache机制,并对不同机制的管理缓存策略不同实现: ValidArgs.h :ValidArgs有效键参数类,模板参数实现,_key:键,_isValid:是否有效, ...
- 缓存Cache
转载自 博客futan 这篇文章将全面介绍有关 缓存 ( 互动百科 | 维基百科 )cache以及利用PHP写缓存caching的技术. 什么是缓存Cache? 为什么人们要使用它? 缓存 Cach ...
- Java-NIO(二):缓冲区(Buffer)的数据存取
缓冲区(Buffer): 一个用于特定基本数据类行的容器.有java.nio包定义的,所有缓冲区都是抽象类Buffer的子类. Java NIO中的Buffer主要用于与NIO通道进行交互,数据是从通 ...
- NIO(一)——缓冲区Buffer
NIO(一)--Buffer NIO简介 NIO即New IO,是用来代替标准IO的,提供了与标准IO完全不同传输方式. 核心: ...
- Java NIO4:缓冲区Buffer(续)
一.什么是缓冲区 一个缓冲区对象是固定数量的数据的容器,其作用是一个存储器,或者分段运输区,在这里数据可被存储并在之后用于检索.缓冲区像前篇文章讨论的那样被写满和释放,对于每个非布尔原始数据 ...
- InnoDB存储引擎--Innodb Buffer Pool(缓存池)
InnoDB存储引擎--Innodb Buffer Pool(缓存池) Innodb Buffer Pool的概念 InnoDB的Buffer Pool主要用于缓存用户表和索引数据的数据页面.它是一块 ...
随机推荐
- day-7 一个简单的决策树归纳算法(ID3)python编程实现
本文介绍如何利用决策树/判定树(decision tree)中决策树归纳算法(ID3)解决机器学习中的回归问题.文中介绍基于有监督的学习方式,如何利用年龄.收入.身份.收入.信用等级等特征值来判定用户 ...
- Linux的rsync 配置,用于服务器之间远程传大量的数据
[教程主题]:rsync [课程录制]: 创E [主要内容] [1] rsync介绍 Rsync(Remote Synchronize) 是一个远程资料同步工具,可通过LAN/WAN快速同步多台主机, ...
- 图数据库orientDB(1-1)SQL基本操作
SQL基本操作 1.新增VerTex CREATE VERTEX V SET name="user01",sex="M",age="25"; ...
- GIT入门笔记(19)GIT 小结
1.add和commit为什么Git添加文件需要add,commit一共两步呢?因为commit可以一次提交很多文件,所以你可以多次add不同的文件,比如:$ git add file1.txt$ g ...
- Swing使用JavaFXweb组件
概述 swing中内嵌入web组件的 需要使用一些其他的jar包 ,但是如果使用javafx的组件,那么也比较的方便,性能也比较高. 代码 webview 在javafx 中是作为 scene出现的所 ...
- Dictionary导致CPU暴涨
中午吃完饭回来,刚想眯一会,突然发现公司预警群报警,某台机器CPU100%,连续三次报警,心里咯噔一下,我新开发的程序就在这上面,是不是我的程序导致的?立马远程,oh my god,果然是. 二话不说 ...
- [洛谷P3383][模板]线性筛素数-欧拉筛法
Description 如题,给定一个范围N,你需要处理M个某数字是否为质数的询问(每个数字均在范围1-N内) Input&Output Input 第一行包含两个正整数N.M,分别表示查询的 ...
- 如何在pycharm中使用配置好的virtualenv环境
1.手动建立: 第一步 建立虚拟环境 Windows cmd: pip install virtualenv 创建虚拟环境目录 env 激活虚拟环境 C:\Python27\Scripts\env\S ...
- vue中简单的小插曲
我们现在来学习一下vue中一些简单的小东西: 首先我们必须要引入vue.js文件哦! 1.有关文本框里的checkbox js代码: new Vue({ el:"#app", da ...
- Thinkphp框架下封装文件下载函数
第一步:开启php_fileinfo.dll 方法:打开php.ini,将874行的;extension=php_fileinfo.dll前面的分号注释去掉即可: 第二步:控制层封装文件下载函数 fu ...