python+selenium:浏览器webdriver操作(1)--基本对象定位
1.简单对象的定位-----自动化测试的核心
对象的定位应该是自动化测试的核心,要想操作一个对象,首先应该识别这个对象。一个对象就是一个人一样,他会有各种的特征(属性),如比我们可以通过一个人的身份证号,姓名,或者他住在哪个街道、楼层、门牌找到这个人。那么一个对象也有类似的属性,我们可以通过这个属性找到这对象。
2.webdriver提供了一系列的对象定位方法,常用的有以下几种
- · id
- · name
- · class name
- · link text
- · partial link text
- · tag name
- · xpath
- · css selector
3.以百度输入框的属性信息为例,则可以通过以下一系列方式捕获输入框
#coding=utf-8 from selenium import webdriver
import time browser = webdriver.Firefox() browser.get("http://www.baidu.com")
time.sleep(2) #########百度输入框的定位方式########## #通过id方式定位
browser.find_element_by_id("kw").send_keys("selenium") #通过name方式定位
browser.find_element_by_name("wd").send_keys("selenium") #通过tag name方式定位
browser.find_element_by_tag_name("input").send_keys("selenium") #通过class name 方式定位
browser.find_element_by_class_name("s_ipt").send_keys("selenium") #通过CSS方式定位
browser.find_element_by_css_selector("#kw").send_keys("selenium") #通过xphan方式定位
browser.find_element_by_xpath("//input[@id='kw']").send_keys("selenium") ############################################ browser.find_element_by_id("su").click()
time.sleep(3)
browser.quit()
4.分别介绍
百度输入框的属性如下图(鼠标放在输入框---右键---检查)
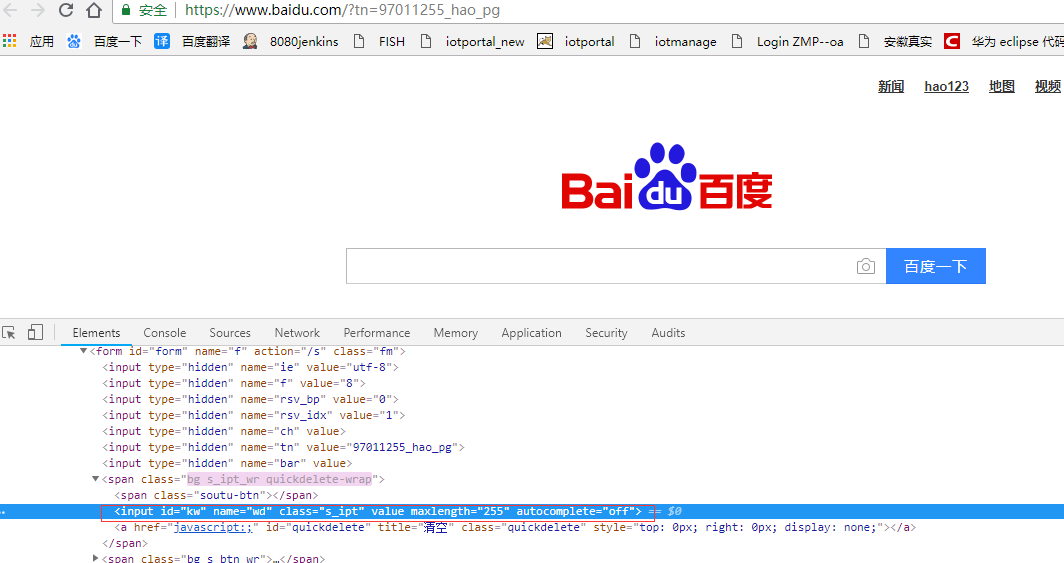
(1)id/name
从上图可以看到有id,name属性,则可以通过函数获取:
id=”kw”
通过find_element_by_id("kw") 函数就是捕获到百度输入框
name=”wd”
通过find_element_by_name("wd")函数同样也可以捕获百度输入框
(2)class name/tag name
从上图可以看到不止有id,name属性,还有class(s_ipt)、tag name(标签名--input)属性
class="s_ipt"
通过find_element_by_class_name("s_ipt")函数捕获百度输入框。
<input>
input 就是标签的名字,可以通过find_element_by_tag_name("input") 函数来定位。
(3)link text/partial link text
有时候不是一个输入框也不是一个按钮,而是一个文字链接,我们可以通过link
例如百度主页右上角的贴吧链接,可以通过link方式获取
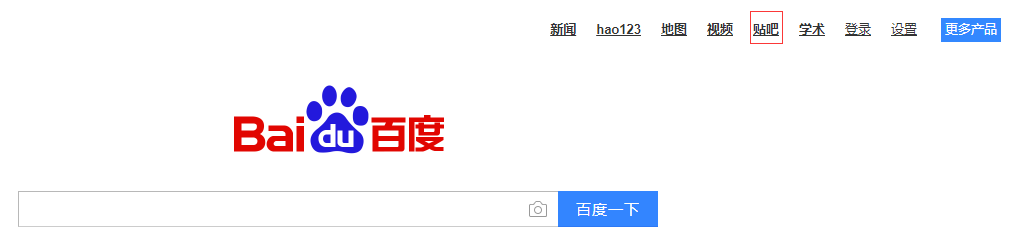
link text
通过find_element_by_link_test("贴 吧").click()函数来定位
partial link text:部分链接定位,只用了"贴"字,一样能找到"贴 吧"链接
通过find_element_by_link_test("贴").click()函数来定位
(4)xpath
XPath是一种在XML文档中定位元素的语言。因为HTML可以看做XML的一种实现,所以selenium用户可是使用这种强大语言在web应用中定位元素。
XPath扩展了上面id和name定位方式,提供了很多种可能性,如以下应用:
xpath:attributer (属性)
driver.find_element_by_xpath("//input[@id='kw']").send_keys("selenium")
#input标签下id =kw的元素
xpath:idRelative (id相关性)
driver.find_element_by_xpath("//div[@id='fm']/form/span/input").send_keys("selenium")
#在/form/span/input 层级标签下有个div标签的id=fm的元素
driver.find_element_by_xpath("//tr[@id='check']/td[2]").click()
# id为'check' 的tr ,定位他里面的第2个td
xpath:position (位置)
driver.find_element_by_xpath("//input").send_keys("selenium")
driver.find_element_by_xpath("//tr[7]/td[2]").click()
#第7个tr 里面的第2个td
xpath: href (水平参考)
driver.find_element_by_xpath("//a[contains(text(),'网页')]").click()
#在a标签下有个文本(text)包含(contains)'网页' 的元素
xpath:link
driver.find_element_by_xpath("//a[@href='http://www.baidu.com/']").click()
#有个叫a的标签,他有个链接href='http://www.baidu.com/ 的元素
(5)css
CSS(Cascading Style Sheets)是一种语言,它被用来描述HTML和XML文档的表现。CSS使用选择器来为页面元素绑定属性。这些选择器可以被selenium用作另外的定位策略。
CSS的比较灵活可以选择控件的任意属性
取id属性:
如属性信息为:<input id="kw" class="s_ipt" type="text" maxlength="100" name="wd" autocomplete="off">
通过find_element_by_css_selector("#kw")函数来定位
取name属性:
如属性信息为:<a href="http://news.baidu.com" name="tj_news">新 闻</a>
通过find_element_by_css_selector("a[name=\"tj_news\"]").click()函数来定位
取title属性:
如属性信息为:<a onclick="queryTab(this);" mon="col=502&pn=0" title="web" href="http://www.baidu.com/">网页</a>
通过find_element_by_css_selector("a[title=\"web\"]").click()函数来定位
python+selenium:浏览器webdriver操作(1)--基本对象定位的更多相关文章
- Python实现浏览器自动化操作
Python实现浏览器自动化操作 (2012-08-02 17:35:43) 转载▼ 最近在研究网站自动登录的问题,涉及到需要实现浏览器自动化操作,网上有不少介绍,例如使用pamie,但是只是 ...
- [转载]Python实现浏览器自动化操作
原文地址:Python实现浏览器自动化操作作者:rayment 最近在研究网站自动登录的问题,涉及到需要实现浏览器自动化操作,网上有不少介绍,例如使用pamie,但是只是支持IE,而且项目也较久没 ...
- python+selenium:浏览器webdriver操作(0)
1.浏览器最大化 启动的浏览器不是全屏的,这样不会影响脚本的执行,但是有时候会影响我们“观看”脚本的执行. #coding=utf-8 from selenium import webdriver i ...
- selenium 浏览器基础操作(Python)
想要开始测试,首先要清楚测试什么浏览器.如何为浏览器安装驱动,前面已经聊过. 其次要清楚如何打开浏览器,这一点,在前面的代码中,也体现过,但是并未深究.下面就来聊一聊对浏览器操作的那些事儿. from ...
- Python+Selenium(webdriver常用API)
总结了Python+selenium常用的一些方法函数,以后有新增再随时更新: 加载浏览器驱动: webdriver.Firefox() 打开页面:get() 关闭浏览器:quit() 最大化窗口: ...
- python selenium 基本常用操作
最近学习UI自动化,把一些常用的方法总结一下,方便自己以后查阅需要.因本人水平有限,有不对之处多多包涵!欢迎指正! 一.xpath模糊匹配定位元素 武林至尊,宝刀屠龙刀(xpath),倚天不出(css ...
- python selenium鼠标键盘操作(ActionChains)
用selenium做自动化,有时候会遇到需要模拟鼠标操作才能进行的情况,比如单击.双击.点击鼠标右键.拖拽等等.而selenium给我们提供了一个类来处理这类事件--ActionChains sele ...
- python selenium模拟滑动操作
selenium.webdriver提供了所有WebDriver的实现,目前支持FireFox.phantomjs.Chrome.Ie和Remote quit()方法会退出浏览器,而close()方法 ...
- Python+Selenium 自动化实现实例-获取测试对象的Css属性
#coding:utf-8 '''获取测试对象的css属性场景 当你的测试用例纠结细枝末节的时候,你就需要通过判断元素的css属性来验证你的操作是否达到了预期的效果.比如你可以通过判断页面上的标题字号 ...
随机推荐
- 权限问题 <customErrors> 标记的“mode”属性设置为“Off”
引用 权限问题 <customErrors> 标记的“mode”属性设置为“Off”. 权限问题标记的“mode”属性设置为“Off”.说明: 服务器上出现应用程序错误.此应用程序的当前自 ...
- LeetCode 852. 山脉数组的峰顶索引 (二分)
题目链接:https://leetcode-cn.com/problems/peak-index-in-a-mountain-array/ 我们把符合下列属性的数组 A 称作山脉: A.length ...
- js - 除法
取整数 1.丢弃小数部分,保留整数部分 js:parseInt(7/2) 2.向上取整,有小数就整数部分加1 js: Math.ceil(7/2) 3,四舍五入. js: Math.round(7/2 ...
- script标签引入脚本的引入位置与效果
用script标签引入脚本的引入位置大致有两种情况: 1,在head中引入: 2,在body末尾引入: 浏览器由上到下解析代码,正常情况下,先解析head中的代码,在解析body中的代码:放在head ...
- Tram POJ - 1847 spfa
#include<iostream> #include<algorithm> #include<queue> #include<cstdio> #inc ...
- Python调用百度地图API实现批量经纬度转换为实际省市地点(api调用,json解析,excel读取与写入)
1.获取秘钥 调用百度地图API实现得申请百度账号或者登陆百度账号,然后申请自己的ak秘钥.链接如下:http://lbsyun.baidu.com/apiconsole/key?applicatio ...
- 使用Java代码将一张图片生成为字符画
测试的图片: 输出的结果: 代码: package test; import java.awt.image.BufferedImage; import java.io.File; import jav ...
- pdo一次插入多条数据的2种实现方式
pdo一次插入多条数据的2种实现方式: **** 1.一个sql插入多个值,防注入处理放在获取到值的时候使用htmlspecialchars(addslashes($params )); try{ f ...
- api接口出现Provisional headers are shown,
问题分析:根据反馈可以知道,发起请求,但服务器未及时响应,原因可能是超时,或者被拦截
- shell脚本编程学习笔记(一)
一.脚本格式 vim shell.sh #!/bin/bash //声明脚本解释器,这个‘#’号不是注释,其余是注释 #Program: //程序内容说明 #History: //时间和作者 二.sh ...