假期学习【十一】Python切词,以及从百度爬取词典
今天主要对从CSDN爬取的标题利用jieba(结巴)进行分词,但在分词过程中发现,如大数据被分成了大/数据,云计算被分隔成了云/计算。
后来又从百度百科---》信息领域爬取了相关词语作为词典,预计今天晚上完成切词任务。
其中分割代码如下:
import jieba
import io #对句子进行分词
def cut():
f=open("E://luntan.txt","r+",encoding="utf-8")
for line in f:
seg_list=jieba.cut(line)
#print(' '.join(seg_list))
for i in seg_list:
print(i)
write(i+" ")
#write(' '.join(seg_list)) #分词后写入
def write(contents):
f=open("E://luntan_cut.txt","a+",encoding="utf-8")
f.write(contents)
print("写入成功!")
f.close() #创建停用词
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords # 对句子进行去除停用词
def seg_sentence(sentence):
sentence_seged = jieba.cut(sentence.strip())
stopwords = stopwordslist('E://stop.txt') # 这里加载停用词的路径
outstr = ''
for word in sentence_seged:
if word not in stopwords:
if word != '\t':
outstr += word
outstr += " "
return outstr #循环去除
def cut_all():
inputs = open('E://luntan_cut.txt', 'r', encoding='utf-8')
outputs = open('E//luntan_stop', 'w')
for line in inputs:
line_seg = seg_sentence(line) # 这里的返回值是字符串
outputs.write(line_seg + '\n')
outputs.close()
inputs.close() if __name__=="__main__":
cut()
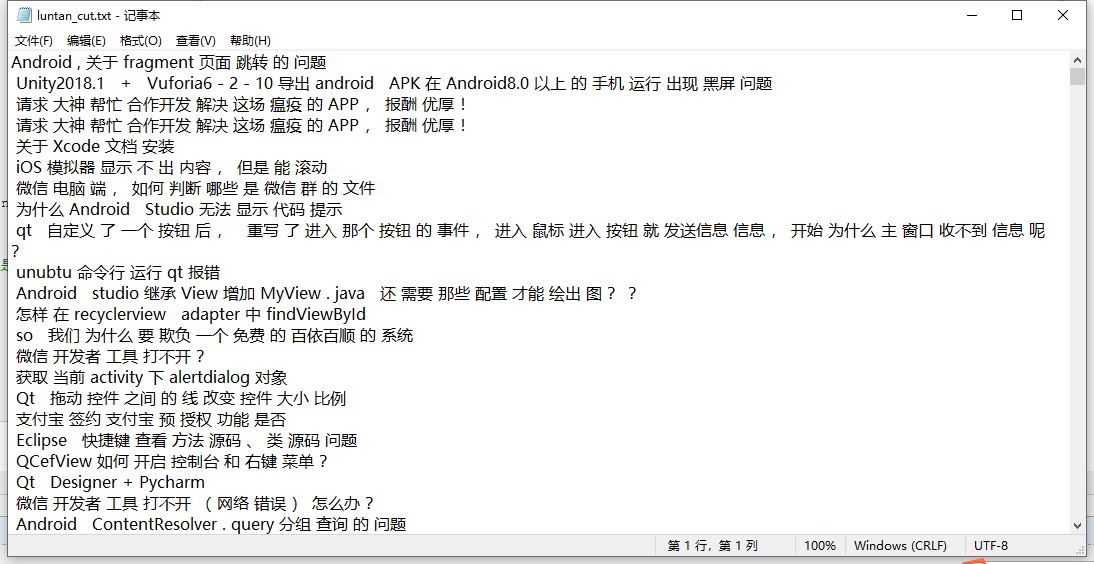
分割后的文本
从百度爬取词典要把百度页面 地址:https://baike.baidu.com/wikitag/taglist?tagId=76607
该页拉到最下,并存为本地mhtml格式,在浏览器打开然后右击查看源代码,源代码保存为txt格式文件,
代码如下:
import io
import re patton=re.compile(r'title=".*"')
def read():
f=open("E://mhtml.txt","r+",encoding="utf-8")
for line in f:
line=line.rstrip("\n")
m=patton.findall(line)
#print(line)
if len(m)!=0:
print(m)
write(str(m).lstrip("['title=\"").rstrip("\"']")+"\r") def write(contents):
f=open("E://xinxi.txt","a+",encoding="utf-8")
f.write(contents)
print("写入成功!")
f.close() if __name__=="__main__":
read()
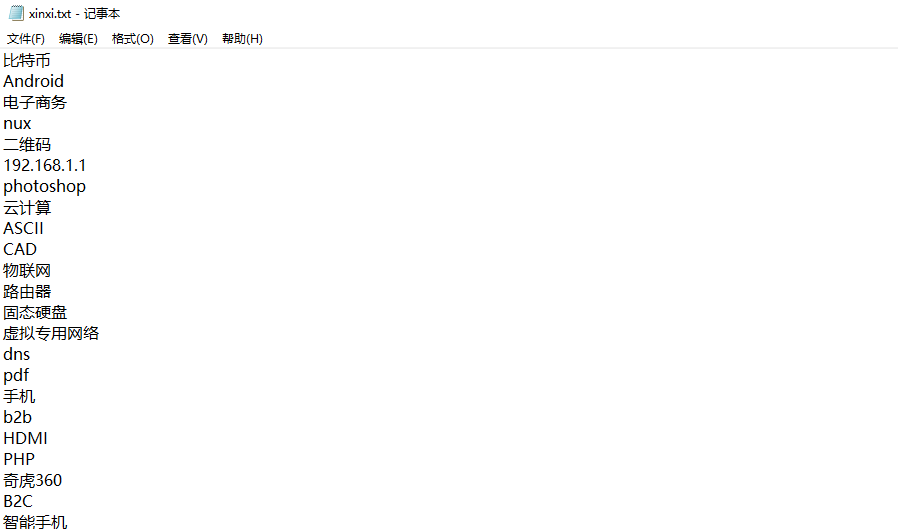
效果:
假期学习【十一】Python切词,以及从百度爬取词典的更多相关文章
- 【学习笔记】Python 3.6模拟输入并爬取百度前10页密切相关链接
[学习笔记]Python 3.6模拟输入并爬取百度前10页密切相关链接 问题描述 通过模拟网页,实现百度搜索关键词,然后获得网页中链接的文本,与准备的文本进行比较,如果有相似之处则代表相关链接. me ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- Python网络爬虫与如何爬取段子的项目实例
一.网络爬虫 Python爬虫开发工程师,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- Python爬虫:通过关键字爬取百度图片
使用工具:Python2.7 点我下载 scrapy框架 sublime text3 一.搭建python(Windows版本) 1.安装python2.7 ---然后在cmd当中输入python,界 ...
随机推荐
- typescript 点滴
1 extend的用法 const x = extend({ a: 'hello' }, { b: 42 }); 2只有在d.ts,你才可以使用 export as 这样子的语法.而且必须有name ...
- 10个用于C#.NET开发的基本调试工具
在调试软件时,工具非常重要.获取正确的工具,然后再调试时提起正确的信息.根据获取的正确的错误信息,可以找到问题的根源所在.找到问题根源所在,你就能够解决该错误了. 你将看到我认为最基本的解决在C# . ...
- Mysql无法启动、闪退
一.mysql下载完成后,运行bin目录下的mysql.exe,提示文件缺失 二.此报错为VC运行库不全或没有安装导致,百度搜索“微软常用运行库合集”进行下载安装即可解决 三.运行时闪退,无法 ...
- kali安装—来自重装3次,创建了8个虚拟机的老安装师
个人是有点生气的,但其实用好默认设置就很简单 我个人参考了好几个博客在这里附上链接: 1.其他人博客每步详细https://blog.csdn.net/chaootis1/article/detail ...
- Shiro -- (一)简介
简介: Apache Shiro 是一个强大易用的 Java 安全框架,提供了认证.授权.加密和会话管理等功能,对于任何一个应用程序,Shiro 都可以提供全面的安全管理服务.并且相对于其他安全框架, ...
- 手动发布本地jar包到Nexus私服
1.Nexus配置 1. 在Nexus私服上建立仓库,用于盛放jar包,如名叫3rd_part. 2. 注册用户Nuxus用户,如名叫dev,密码dev_123. 3. 给dev用户分配能访问3rd_ ...
- C#实现把String字符串转化为SQL语句中的In后接的参数
实现把String字符串转化为In后可用参数代码: public string StringToList(string aa) { string bb1 = "("; if (!s ...
- Docker Stack 学习笔记
该文为<深入浅出Docker>的学习笔记,感谢查看,如有错误,欢迎指正 一.简介 Docker Stack 是为了解决大规模场景下的多服务部署和管理,提供了期望状态,滚动升级,简单易用,扩 ...
- RedisDeskTopManager连接时提示:can't nonnect to redis-server
场景 在使用RedisDeskTopManager客户端可视化工具连接Redis服务端时提示: 注: 博客: https://blog.csdn.net/badao_liumang_qizhi关注公众 ...
- [Contract] Solidity 判断 mapping 值的存在
比如 mapping(address => uint) tester,只需要判断 mapping 是否为默认值 0, tester[msg.sender] == 0 "You can ...