Hadoop3.1.1源码Client详解 : 入队前数据写入
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览
紧接着上一篇: Hadoop3.1.1源码Client详解 : 写入准备-RPC调用与流的建立
先给出数据写入时的3个主要载体

载体1是我们实际要写入HDFS的数据,一般是字节数组
载体2是一个字节数组,这个字节数组位于校验和计算类FSOutputSummer的对象中
载体3是客户端和DataNode通信的重要载体,来自载体2的数据(3中的实际数据)被加上消息头和来自载体2的校验和,打成一个Packet,并且Packet被写满或
Block被写满后被压入守护线程DataStreamer的消息队列dataQueue中。
接着我们来阐述各个载体间的关系,以及分析整个数据流
首先是载体1和载体2间的关系
我们要知道,当我们调用Hadoop客户端的FSDataOutputStream的write方法的时候,是不一定会真正的写出数据的。
因为Hadoop输出流的设计采用了修饰模式,各个流都是对另一个流的包装(功能添加)。
FSDataOutputStream包装了PositionCache,PositionCache包装了FSOutputSummer(其实包装的是DFSOutputStream,DFSOutputStream继承FSOutputSummer)
因为PositionCache的功能比较鸡肋,主要是统计数据流,简化起见,之后我们省略他。
整体的调用关系:为了分析方便 打上颜色

调用FSDataOutputStream.write(byte[] b),也就是我们平常写入数据流的方法,会通过各种修饰关系兜兜转转调用到上图红色的函数(write)上,中间过程的函数省略
我们来看一下红色函数write干了什么。
红色函数实际上是把我们实际输入的数据,分段地输入到write1方法中,而且根据write1方法返回的值,了解到write1方法实际上写入了多少数据

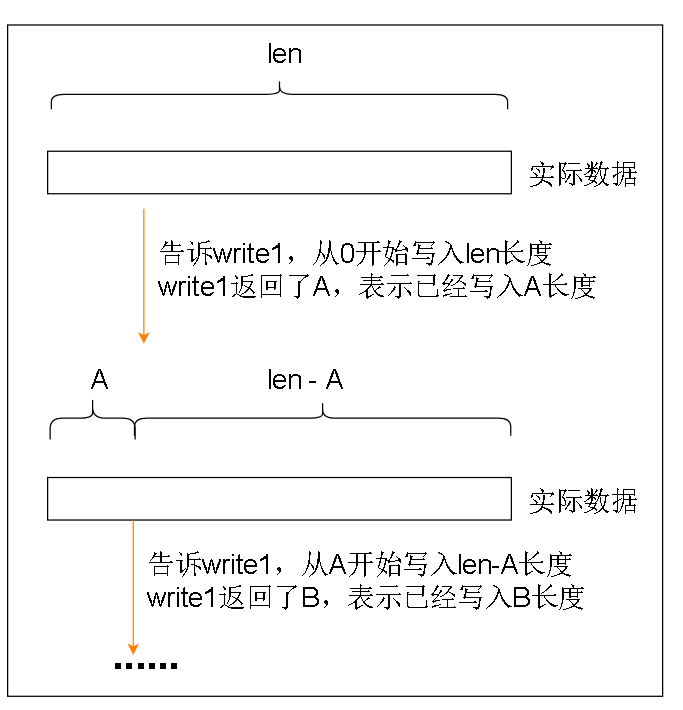
红色函数write实际上只是保证我们数据能分段写入绿色函数write1
在write1中我们遇到第一层缓冲,也就是载体2,buffer数组, buffer大小一般是每份校验和大小的9倍,每份校验和大小在客户端的 dfs.bytes-per-checksum 选 项中设置。
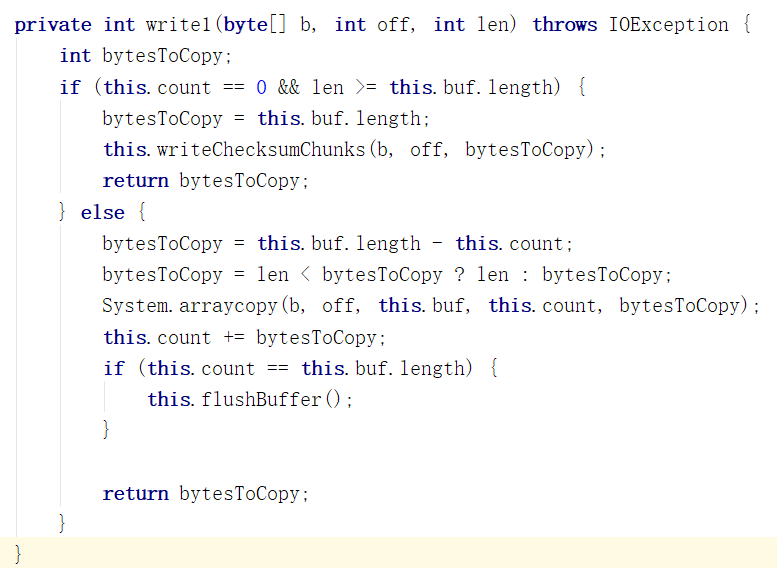
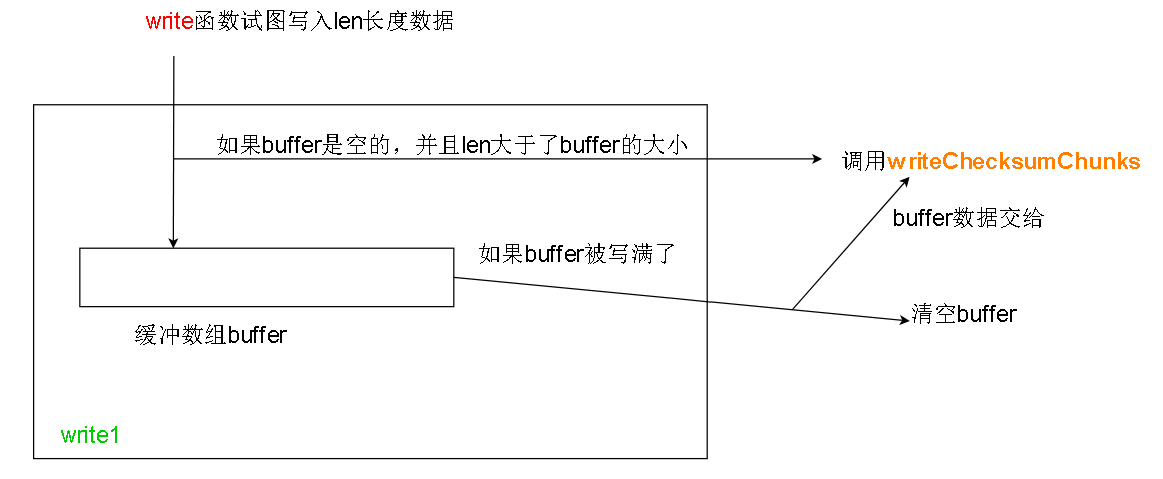
其中第二种情况的flushBuffer函数中包含了对橙色函数writeChecksumChunks函数的调用
这个函数应该拆成writeChecksum/Chunks , 因为这个函数负责计算校验和(checksum)并且调用writeChunk(紫色函数)来写入Chunk
绿框所在的for循环做的是把buffer传来的数据切成许多份(一般是9份),每份的大小是BytesPerCheckSum,BytesPerCheckSum的意思是在整个数据中
每隔多少字节就计算过一次校验和。
关于Chunk的含义和校验和种类稍后介绍
我们看橙色函数writeChecksumChunks,
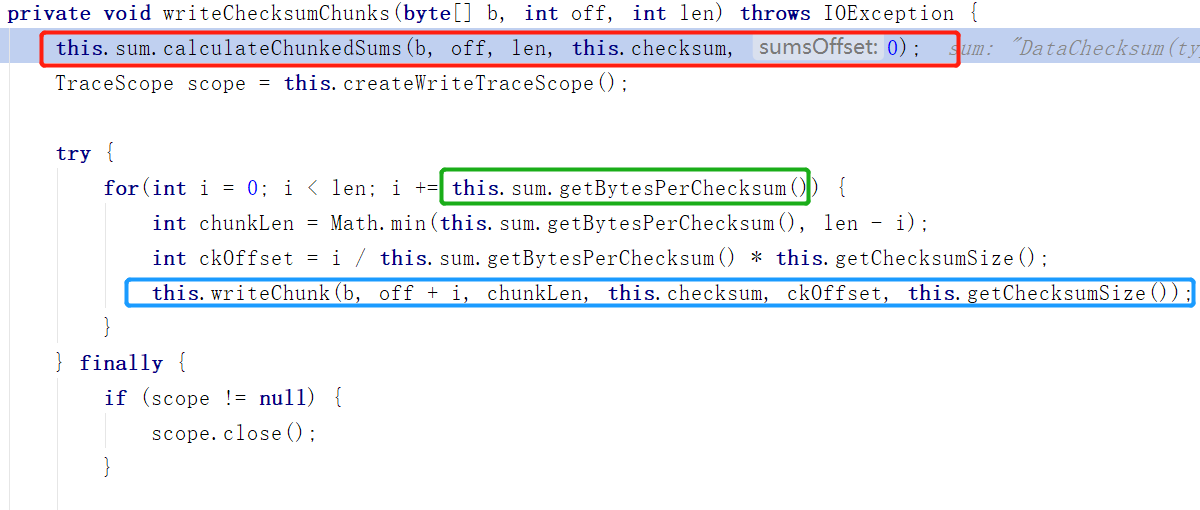
红框的地方是计算校验和
计算检验和的大体做法是:在写入数据的时候,把数据分成等大小的若干份(最后一份可能不是等大小的),然后对每份进行校验和计算,把算出来的结果
添加到数据头部或者尾部,下次取出数据的时候就可以根据校验和计算数据,是否出错。
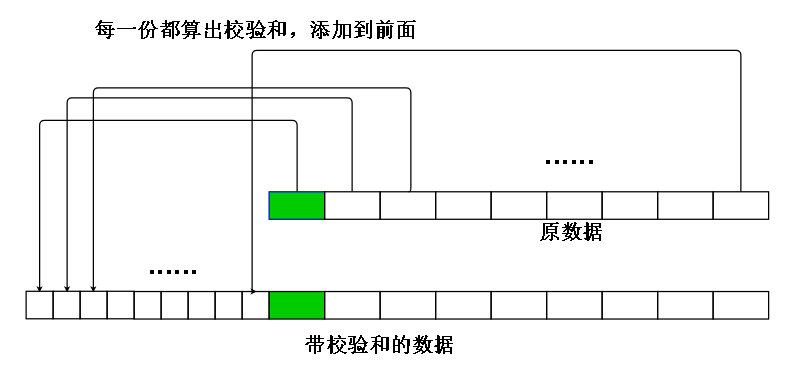
这里计算校验和的算法默认是CRC32
绿色空心框中的BytesPerChecksum就是每份数据的大小,也就是绿色长方形的大小,每个绿色长方形被叫做Chunk(BytesPerChecksum大小的一份数据)
蓝色空心框部分十分重要,框中方法writeChuck(紫色函数)被DFSOutputStream重写
下面是简单的说明,之后有详解

我们来看看图解,序号表示操作执行顺序
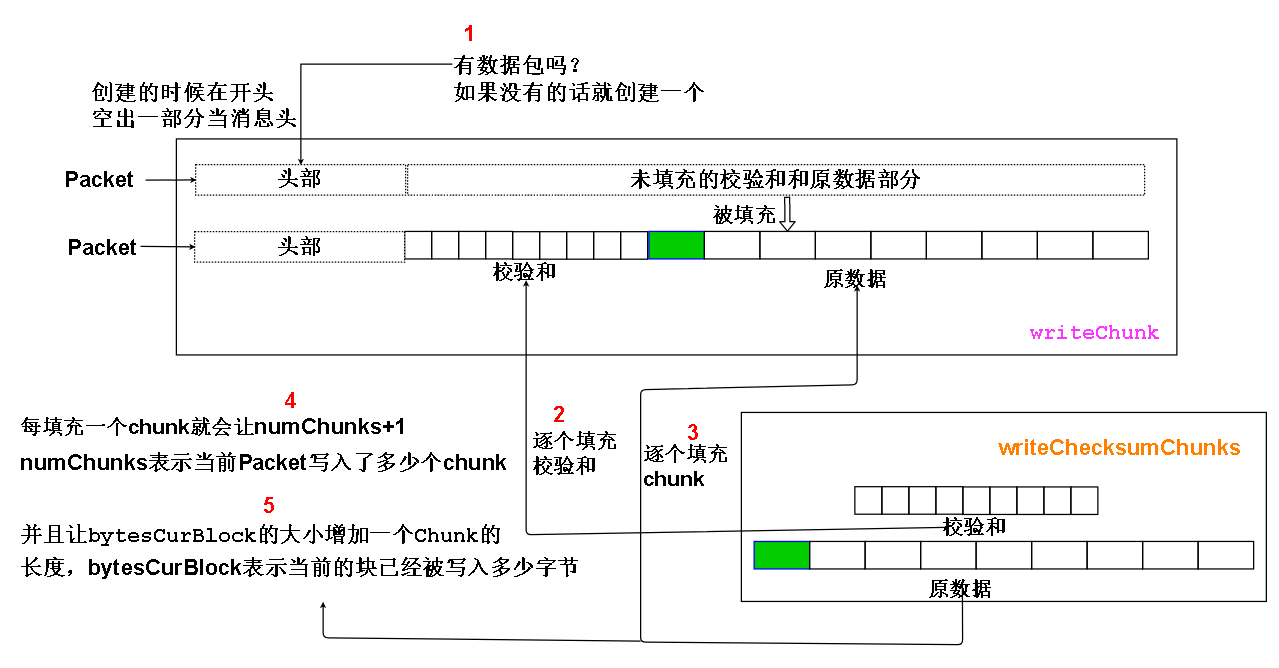
1.第一步其实还有一些检查操作,但主要操作还是创建包
2.第二步是逐块逐块地向Packet里填充校验和
3.第三部是逐块逐块地向Packet填充chunk,chunk是我们实际写入数据被分成等大小的那些块。
4.第四步是记录Packet写入了多少个chunk,当写入的数量超过限制的时候(默认是126,具体会根据bytesPerCheckSum和现在是否写入最后一个数据Packet
进行调整)就会触发M事件(M事件稍后解释)
5.第五步是增加DataStreamer记录的当前块已经写入的数据大小(字节为单位),如果已经写入块的数据等于块的大小,也会触发事件M
事件M:
事件M其实就是调用enqueueCurrentPacketFull函数

这个函数主要分3步,第一步是让当前的Packet入队并且将当前Packet设置为空,第二步是根据边界关系调整下一个Packet的大小,第三步是检查是否块已写满
第一步:
很明显,让Packet入队,并且将当前Packet的引用置空,以便下一次创建一个新的Packet
第二步:
边界调整,什么是边界调整呢?我们要写满一个块,要发送若干个Packet给DataNode,一般Packet的大小是相同的
但是如果Block大小不能被Packet整除的话,就需要调整最后一个Packet的大小,以便正好写满Block。

其实第二步是有两个分支的,上述分析的是第二个分支,第一个分支笔者暂时没有研究透,之后补充。
第三步:
检查是否已经写满一个Block了,如果是,就会把当前包里的数据清空,让这个包作为一个结束通知包,发送给DataNode,告知DataNode
当前的Block已经写完了。
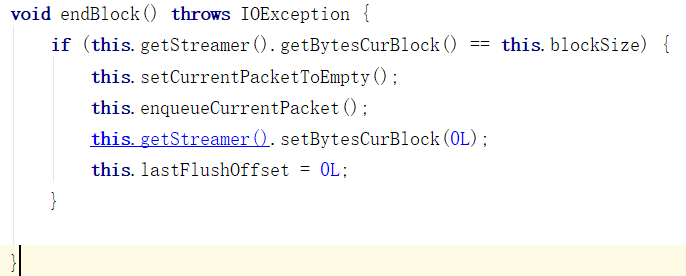

lastPacketInBlock正是来通知DataNode,当前包是Block最后一个包的,没有数据,各项大小都是0,以起到通知作用。
本文分析到此,入队以及之后的操作另外开文分析。
从本文的缓冲以及要写满一个Packet才发送数据我们可以得知 :
有时我们写入了数据,关闭客户端,发现并没有数据被写入HDFS,是因为写入的数据没有写满一个Packet,甚至是没有达到缓冲区大小所以没有被写到HDFS 中。
虽然这一定程度上违背了POSIX标准中对用户操作响应要及时的要求,但适合Hadoop面向大数据传输的特性。
而且如果只传一点数据就写入HDFS,NameNode会因为频繁的请求和大量的文件元数据(metaData)而崩溃宕机
DataNode也会因为频繁琐碎的文件传输请求而导致网络利用率低,甚至宕机。
Hadoop3.1.1源码Client详解 : 入队前数据写入的更多相关文章
- Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之DataStreamer(Packet发送) : 主干
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 在上一章(Hadoop3.1.1源码Client详解 : 写入准备-RPC调用与流的建立) 我们提到, ...
- Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之ResponseProcessor(ACK接收)
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 紧接着上一篇文章: Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之D ...
- Hadoop3.1.1源码Client详解 : 写入准备-RPC调用与流的建立
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 关于RPC(Remote Procedure Call),如果没有概念,可以参考一下RMI(Remot ...
- Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览
一.设计原理 1.Hadoop架构: 流水线(PipeLine) 2.Hadoop架构: HDFS中数据块的状态及其切换过程,GS与BGS 3.Hadoop架构: 关于Recovery (Lease ...
- NopCommerce源码架构详解--初识高性能的开源商城系统cms
很多人都说通过阅读.学习大神们高质量的代码是提高自己技术能力最快的方式之一.我觉得通过阅读NopCommerce的源码,可以从中学习很多企业系统.软件开发的规范和一些新的技术.技巧,可以快速地提高我们 ...
- NopCommerce源码架构详解
NopCommerce源码架构详解--初识高性能的开源商城系统cms 很多人都说通过阅读.学习大神们高质量的代码是提高自己技术能力最快的方式之一.我觉得通过阅读NopCommerce的源码,可以从 ...
- Nop--NopCommerce源码架构详解专题目录
最近在研究外国优秀的ASP.NET mvc电子商务网站系统NopCommerce源码架构.这个系统无论是代码组织结构.思想及分层都值得我们学习.对于没有一定开发经验的人要完全搞懂这个源码还是有一定的难 ...
- linux 基础入门(8) 软件安装 rpm、yum与源码安装详解
8.软件 RPM包安装 8.1rpm安装 rpm[选项]软件包名称 主选项 -i 安装 -e卸载 -U升级 -q查找 辅助选项 -ⅴ显示过程 -h --hash 查询 -a-all查询所有安装的包 - ...
- linux源码Makefile详解
1.Makefile的作用 (1)决定编译哪些文件 (2)怎样编译这些文件 (3)怎样连接这些文件,最重要的是它们的顺序如何 2.Linux内核Makefile分类 ***************** ...
随机推荐
- JUC之CountDownLatch和CyclicBarrier的区别 (转)
CountDownLatch和CyclicBarrier的功能看起来很相似,不易区分,有一种谜之的神秘.本文将通过通俗的例子并结合代码讲解两者的使用方法和区别. CountDownLatch和Cycl ...
- Mesh R-CNN 论文翻译(实验部分)
本文为 Mesh R-CNN 论文翻译(原理部分)的后续.Mesh R-CNN 原论文. 4 实验 我们在ShapeNet上对网格预测分支进行基准测试,并与最先进的方法相比较.然后,我们在野生的有 ...
- vue 动态组件的传值
vue项目开发中会用到大量的父子组件传值,也会用到动态组件的传值,常规子组件获取父组件的传值时,第一次是获取不到的,这时候有两种解决方案 第一种: 父组件向子组件传的是一个json对象,ES6的方法O ...
- CSS 自适应导航菜单
文章目录 以前我写了一篇关于如何为自适应网页制作教程手机导航菜单,现在我又摸索出一种无需JS脚本的自适应导航菜单,它采用纯粹的语义化HTML5标签来完成.该菜单可以左对齐,居中或右对齐,也不像上一种方 ...
- JS高级---浅拷贝
浅拷贝 拷贝就是复制, 就相当于把一个对象中的所有的内容, 复制一份给另一个对象, 直接复制, 或者说, 就是把一个对象的地址给了另一个对象, 他们指向相同, 两个对象之间有共同的属性或者方法, ...
- 微信公众号h5页面alert去掉域名
h5页面内嵌到微信公众号提示信息alert的时候会显示域名,去掉域名显示重写alert方法: window.alert = function(name){ var iframe = document. ...
- 【Python】输入身份证号,输出出生日期
name = input("请输入你的名字:") id = input("请输入你的身份证号码:") year = id[6:10] month = id[10 ...
- TD - 系统异常 - 登录不上
问题描述:登录之后,页面停留在登录页面,没有任何错误提示 解决办法:重新安装插件
- [CF]Round513
A Phone Numbers 题意:定义"电话号码"为开头为'8',长度为11的字符串.给定一些字符,每个字符只能用一次,求可以拼出多少个电话号码(可以重复). 直接min(st ...
- CAN总线冲突裁决
当总线上的几个器件同时发送数据的时候,CAN总线必须决定哪个器件可以发送,而其他的器件必须等待.冲突裁决是CAN协议最重要的一个特性. 以下图为例.总线上有器件A,B,C,D.A,B,C同时发出SOF ...