第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
Scrapy框架安装
1、首先,终端执行命令升级pip: python -m pip install --upgrade pip
2、安装,wheel(建议网络安装) pip install wheel
3、安装,lxml(建议下载安装)
4、安装,Twisted(建议下载安装)
5、安装,Scrapy(建议网络安装) pip install Scrapy
测试Scrapy是否安装成功
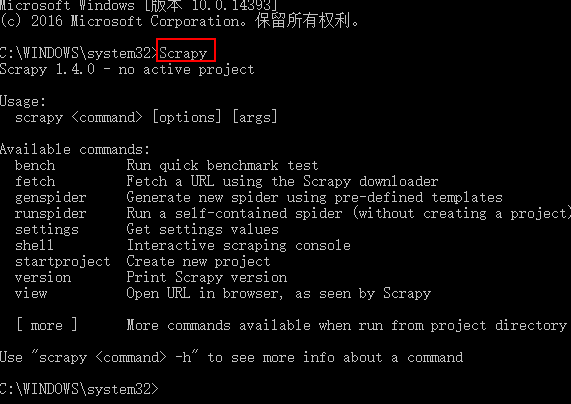
Scrapy框架指令
scrapy -h 查看帮助信息
Available commands:
bench Run quick benchmark test (scrapy bench 硬件测试指令,可以测试当前服务器每分钟最多能爬多少个页面)
fetch Fetch a URL using the Scrapy downloader (scrapy fetch http://www.iqiyi.com/ 获取一个网页html源码)
genspider Generate new spider using pre-defined templates ()
runspider Run a self-contained spider (without creating a project) ()
settings Get settings values ()
shell Interactive scraping console ()
startproject Create new project (cd 进入要创建项目的目录,scrapy startproject 项目名称 ,创建scrapy项目)
version Print Scrapy version ()
view Open URL in browser, as seen by Scrapy ()
创建项目以及项目说明
scrapy startproject adc 创建项目
项目说明
目录结构如下:
├── firstCrawler
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
scrapy.cfg: 项目的配置文件tems.py: 项目中的item文件,用来定义解析对象对应的属性或字段。pipelines.py: 负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库)settings.py: 项目的设置文件.- spiders:实现自定义爬虫的目录
- middlewares.py:Spider中间件是在引擎及Spider之间的特定钩子(specific
hook),处理spider的输入(response)和输出(items及requests)。
其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。

项目指令
项目指令是需要cd进入项目目录执行的指令
scrapy -h 项目指令帮助
Available commands:
bench Run quick benchmark test
check Check spider contracts
crawl Run a spider
edit Edit spider
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
list List available spiders
parse Parse URL (using its spider) and print the results
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version (scrapy version 查看scrapy版本信息)
view Open URL in browser, as seen by Scrapy (scrapy view http://www.zhimaruanjian.com/ 下载一个网页并打开)
创建爬虫文件
创建爬虫文件是根据scrapy的母版来创建爬虫文件的
scrapy genspider -l 查看scrapy创建爬虫文件可用的母版
Available templates:母版说明
basic 创建基础爬虫文件
crawl 创建自动爬虫文件
csvfeed 创建爬取csv数据爬虫文件
xmlfeed 创建爬取xml数据爬虫文件
创建一个基础母版爬虫,其他同理
scrapy genspider -t 母版名称 爬虫文件名称 要爬取的域名 创建一个基础母版爬虫,其他同理
如:scrapy genspider -t basic pach baidu.com
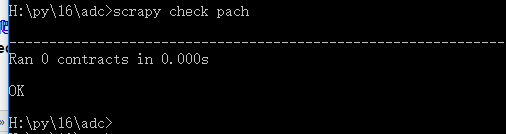
scrapy check 爬虫文件名称 测试一个爬虫文件是否合规
如:scrapy check pach
scrapy crawl 爬虫名称 执行爬虫文件,显示日志 【重点】
scrapy crawl 爬虫名称 --nolog 执行爬虫文件,不显示日志【重点】
第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令的更多相关文章
- 第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门 我的搜素简单实现原理我们可以用js来实现,首先用js获取到 ...
- 第三百六十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)倒排索引
第三百六十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)倒排索引 倒排索引 倒排索引源于实际应用中需要根据属性的值来查找记录.这种索引表中的每一项都包 ...
- 第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中
第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中 1.爬虫文件 dispatcher.connect()信号分发器,第一个参数信 ...
- 第三百九十一节,Django+Xadmin打造上线标准的在线教育平台—404,403,500页面配置
第三百九十一节,Django+Xadmin打造上线标准的在线教育平台—404,403,500页面配置 路由映射在全局也就是根目录里的urls.py里配置404路由映射 注意:不是写在urlpatter ...
- 第三百八十一节,Django+Xadmin打造上线标准的在线教育平台—xadmin全局配置
第三百八十一节,Django+Xadmin打造上线标准的在线教育平台—xadmin全局配置 1.xadmin主题设置 要使用xadmin主题,需要在一个app下的adminx.py后台注册文件里,写一 ...
- 第三百二十一节,Django框架,发送邮件
第三百二十一节,Django框架,发送邮件 全局配置settings.py EMAIL_BACKEND = 'django.core.mail.backends.smtp.EmailBackend' ...
- 第三百三十七节,web爬虫讲解2—PhantomJS虚拟浏览器+selenium模块操作PhantomJS
第三百三十七节,web爬虫讲解2—PhantomJS虚拟浏览器+selenium模块操作PhantomJS PhantomJS虚拟浏览器 phantomjs 是一个基于js的webkit内核无头浏览器 ...
- 第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础 在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块 ...
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
随机推荐
- nginx 屏蔽恶意请求
https://www.xlongwei.com/detail/nginx-%E5%B1%8F%E8%94%BD%E6%81%B6%E6%84%8F%E8%AF%B7%E6%B1%82 nginx可以 ...
- angular中的表单数据自定义验证
之前说过了angular是如何给表单的数据进行基本的,常用的验证的:angular学习笔记(二十)-表单验证 但是在实际工作中,这些验证是远远不够的,很多时候我们需要自定义一些验证规则,以及一些异步, ...
- Vue.js使用-组件(上篇)
1.什么是组件 组件可以理解为定义的一个view模块,可重复使用. 2.组件使用 1)创建组件 var myComponent = Vue.extend({ template: ' this is a ...
- Eclipse报This version of the rendering library is more recent than your version of ADT ...
http://blog.csdn.net/zhao_3546/article/details/12968295 最近使用 Help --> Check for Updates 升级了Eclips ...
- java多线程20 : ReentrantLock中的方法 ,公平锁和非公平锁
公平锁与非公平锁 ReentrantLock有一个很大的特点,就是可以指定锁是公平锁还是非公平锁,公平锁表示线程获取锁的顺序是按照线程排队的顺序来分配的,而非公平锁就是一种获取锁的抢占机制,是随机获得 ...
- 自定义NSOperation下载图片
自定义NSOperation的话,只是需要将要下载图片的操作下载它的main方法里面,考虑到,图片下载完毕,需要回传到控制器里,这里可以采用block,也可以采用代理的方式实现,我采用的是代理的方式实 ...
- iOS 统计Xcode整个工程的代码行数
小技巧5-iOS 统计Xcode整个工程的代码行数 1.打开终端 2.cd 空格 将工程的文件夹拖到终端上,回车,此时进入到工程的路径 此时已经进入到工程文件夹下 3.运行指令 a. find . - ...
- Android 程序drawable资源保存到data目录
今天做了个小功能,就是把我们程序Drawable里面的图片保存到data目录下面,然后另外一个程序需要读取data目录里面保存的图片.涉及了data目录读写.这功能看上去挺简单,不过实际做的时候还是遇 ...
- 【Unity Shader】七、透明的Transparent Shader
学习资料: http://www.sikiedu.com/course/37/task/459/show# 本例的代码基于上一篇文章,添加透明效果.为了便于区分新增的部分,该部分使用和红色加粗字体. ...
- (转) Hadoop1.2.1安装
环境:ubuntu13 使用的用户为普通用户.如:用户ru jdk安装略 1.安装ssh (1) sudo apt-get install openssh-server (2)配置ssh面密码登录 $ ...