第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块,然后将网页数据通过lxml下的etree转化为treedata的形式
urllib库中使用xpath表达式
etree.HTML()将获取到的html字符串,转换成树形结构,也就是xpath表达式可以获取的格式
#!/usr/bin/env python
# -*- coding:utf8 -*-
import urllib.request
from lxml import etree #导入html树形结构转换模块 wye = urllib.request.urlopen('http://sh.qihoo.com/pc/home').read().decode("utf-8",'ignore')
zhuanh = etree.HTML(wye) #将获取到的html字符串,转换成树形结构,也就是xpath表达式可以获取的格式
print(zhuanh)
hqq = zhuanh.xpath('/html/head/title/text()') #通过xpath表达式获取标题 #注意,xpath表达式获取到数据,有时候是列表,有时候不是列表所以要做如下处理
if str(type(hqq)) == "<class 'list'>": #判断获取到的是否是列表
print(hqq)
else:
xh_hqq = [i for i in hqq] #如果不是列表,循环数据组合成列表
print(xh_hqq) #返回 :['【今日爆点】你的专属资讯平台']
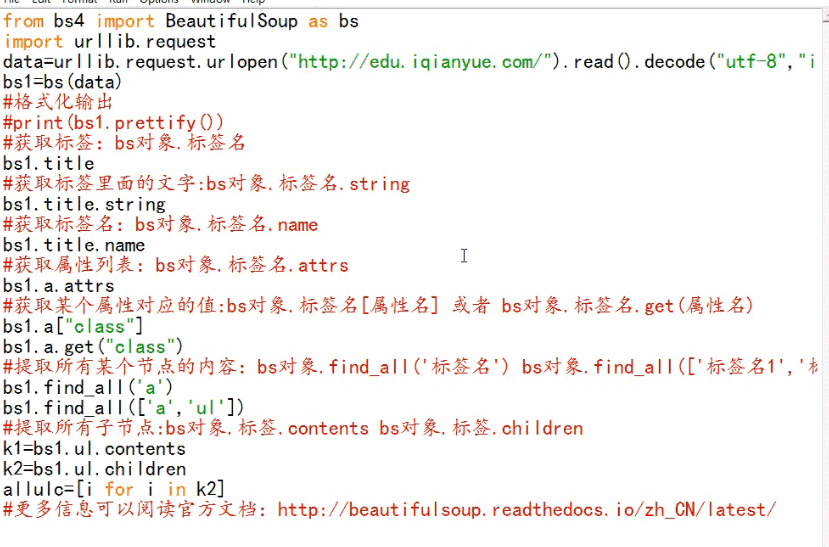
BeautifulSoup基础
BeautifulSoup是获取thml元素的模块
BeautifulSoup-3.2.1版本
第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础的更多相关文章
- 十五 web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块,然后将网页数据通过lxml下的etree转化为treedata的形式 urllib库中使用xpath表 ...
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
- 第三百二十六节,web爬虫,scrapy模块,解决重复ur——自动递归url
第三百二十六节,web爬虫,scrapy模块,解决重复url——自动递归url 一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过 ...
- 第三百八十六节,Django+Xadmin打造上线标准的在线教育平台—HTML母版继承
第三百八十六节,Django+Xadmin打造上线标准的在线教育平台—HTML母版继承 母板-子板-母板继承 母板继承就是访问的页面继承一个母板,将访问页面的内容引入到母板里指定的地方,组合成一个新页 ...
- 第三百七十六节,Django+Xadmin打造上线标准的在线教育平台—创建用户操作app,在models.py文件生成5张表,用户咨询表、课程评论表、用户收藏表、用户消息表、用户学习表
第三百七十六节,Django+Xadmin打造上线标准的在线教育平台—创建用户操作app,在models.py文件生成5张表,用户咨询表.课程评论表.用户收藏表.用户消息表.用户学习表 创建名称为ap ...
- 第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点 1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
- 第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解 封装模块 #!/usr/bin/env python # -*- coding: utf- ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百二十七节,web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
第三百二十七节,web爬虫讲解2—urllib库爬虫 利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode(& ...
随机推荐
- Java 虚拟机:互斥同步、锁优化及synchronized和volatile
互斥同步 互斥同步(Mutual Exclusion & Synchronization)是常见的一种并发正确性保证手段.同步是指子啊多个线程并发访问共享数据时,保证共享数据在同一时刻只能被一 ...
- MySQL 数据库新用户授权
--- 新建数据库用户授权 --远程的 GRANT ALL PRIVILEGES ON `testdb`.* TO 'username'@'%' IDENTIFIED BY 'pwd2017'; -- ...
- Burpsuite如何抓取使用了SSL或TLS传输的 IOS App流量
之前一篇文章介绍了Burpsuite如何抓取使用了SSL或TLS传输的Android App流量,那么IOS中APP如何抓取HTTPS流量呢, 套路基本上与android相同,唯一不同的是将证书导入i ...
- 读取本地已有的.db数据库
public class MyDB extends SQLiteOpenHelper { // 数据库的缺省路径 private static String DB_PATH ; private sta ...
- 【Linux技术】磁盘的物理组织,深入理解文件系统
磁盘即是硬盘,由许多块盘片(盘面)组成,每个盘片的上下两面都涂有磁粉,磁化后可以存储信息数据.每个盘片的上下两面都安装有磁头,磁头被安装在梳状的可以做直线运动的小车上以便寻道,每个盘面被格式化成有若干 ...
- SpringBoot整合SpringKafka实现消费者史上最简代码实现
该项目是使用的技术:SpringBoot + SpringKafka + Maven 先看pom.xml文件中引入的依赖: <?xml version="1.0" enco ...
- docker 错误:Error response from daemon: cannot stop container: connect: connection refused": unknown
docker 错误:Error response from daemon: cannot stop container: 795e4102b2de: Cannot kill container 795 ...
- nohup 后台启动程序,并输出到指定日志
1.启动程序并输入到指定日志 nohup python manage.py runserver 0.0.0.0:9090 > /data/zyj/xadstat/xadstat.log 2&am ...
- repo常用指令
下载 repo 的地址: http://android.git.kernel.org/repo ,可以用 wget http://android.git.kernel.org/repo 或者 curl ...
- uboot——之初体验
官方下载地址:ftp://ftp.denx.de/pub/u-boot/ uboot的终极奥义就是启动内核. 但是,现在,我们先做最基本的,去官网下载一个支持自己板子的uboot,然后解压缩,打补丁. ...