Hadoop分布式集群部署(单namenode节点)
Hadoop分布式集群部署
系统系统环境:
OS: CentOS 6.8
内存:2G
CPU:1核
Software:jdk-8u151-linux-x64.rpm
hadoop-2.7.4.tar.gz
hadoop下载地址:
sudo wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.7.4/hadoop-2.7.4.tar.gz
主机列表信息:
|
主机名 |
IP 地址 |
安装软件 |
Hadoop role |
Node role |
|
hadoop-01 |
192.168.153.128 |
Jdk,hadoop |
NameNode |
namenode |
|
hadoop-02 |
192.168.153.129 |
Jdk,hadoop |
DataNode |
datenode |
|
hadoop-03 |
192.168.153.130 |
Jdk,hadoop |
DataNode |
datenode |
基础配置:
1.Hosts文件设置(三台主机的host文件需要保持一致)
[root@hadoop- ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
:: localhost localhost.localdomain localhost6 localhost6.localdomain6
#######################################
192.168.153.128 hadoop-
192.168.153.129 hadoop-
192.168.153.130 hadoop-
2.创建hadoop账户,使用该账户运行hadoop服务(三台主机都创建hadoop用户),创建hadoop用户,设置拥有sudo权限
[root@hadoop-01 ~]# useradd hadoop && echo hadoop | passwd --stdin hadoop
Changing password for user hadoop.
passwd: all authentication tokens updated successfully.
[root@hadoop-01 ~]# echo "hadoop ALL=(ALL) NOPASSWD:ALL" >> /etc/sudoers
3.生成SSH免秘钥认证文件(在三台主机都执行)
[root@hadoop-01 ~]# su - hadoop
[hadoop@hadoop-01 ~]$ ssh-keygen -t rsa
4.SSH密钥认证文件分发.
1.>将hadoop-01的公钥信息复制到另外两台机器上面
[hadoop@hadoop-01 ~]$ ssh-copy-id 192.168.153.128
[hadoop@hadoop-01 ~]$ ssh-copy-id 192.168.153.129
[hadoop@hadoop-01 ~]$ ssh-copy-id 192.168.153.130
测试ssh免密码登录
[hadoop@hadoop-01 ~]$ ssh 192.168.153.128
Last login: Wed Nov 15 22:37:10 2017 from hadoop-01
[hadoop@hadoop-02 ~]$ exit
logout
Connection to 192.168.153.128 closed.
[hadoop@hadoop-01 ~]$ ssh 192.168.153.129
Last login: Wed Nov 15 22:37:10 2017 from hadoop-01
[hadoop@hadoop-02 ~]$ exit
logout
Connection to 192.168.153.129 closed.
[hadoop@hadoop-01 ~]$ ssh 192.168.153.130
Last login: Thu Nov 16 07:46:35 2017 from hadoop-01
[hadoop@hadoop-03 ~]$ exit
logout
Connection to 192.168.153.130 closed.
2.>分发hadoop@hadoop-02的公钥到其他两台主机.
hadoop@hadoop-02 ~]$ ssh-copy-id 192.168.153.128
[hadoop@hadoop-02 ~]$ ssh-copy-id 192.168.153.129
[hadoop@hadoop-02 ~]$ ssh-copy-id 192.168.153.130
测试hadoop@hadoop-02 ssh免密码登录其他三台主机,包括自己本身的登录.
[hadoop@hadoop-02 ~]$ ssh 192.168.153.128
Last login: Sat Oct 28 19:37:16 2017 from hadoop-01
[hadoop@hadoop-01 ~]$ exit
logout
Connection to 192.168.153.128 closed.
[hadoop@hadoop-02 ~]$ ssh 192.168.153.129
Last login: Wed Nov 15 21:26:12 2017 from hadoop-01
[hadoop@hadoop-02 ~]$ exit
logout
Connection to 192.168.153.129 closed.
[hadoop@hadoop-02 ~]$ ssh 192.168.153.130
Last login: Thu Nov 16 06:35:35 2017 from hadoop-01
[hadoop@hadoop-03 ~]$
[hadoop@hadoop-03 ~]$ exit
logout
Connection to 192.168.153.130 closed.
3.>分发hadoop@hadoop-03的公钥到其他两台主机.
[hadoop@hadoop-03 ~]$ ssh-copy-id 192.168.153.128
[hadoop@hadoop-03 ~]$ ssh-copy-id 192.168.153.129
[hadoop@hadoop-03 ~]$ ssh-copy-id 192.168.153.130
测试hadoop@hadoop-03的免秘钥分发.
[hadoop@hadoop-03 ~]$ ssh 192.168.153.128
Last login: Sat Oct 28 19:43:39 2017 from hadoop-02
[hadoop@hadoop-01 ~]$ exit
logout
Connection to 192.168.153.128 closed.
[hadoop@hadoop-03 ~]$ ssh 192.168.153.129
Last login: Wed Nov 15 21:32:31 2017 from hadoop-02
[hadoop@hadoop-02 ~]$ exit
logout
Connection to 192.168.153.129 closed.
[hadoop@hadoop-03 ~]$ ssh 192.168.153.130
Last login: Thu Nov 16 06:41:53 2017 from hadoop-02
[hadoop@hadoop-03 ~]$ exit
logout
Connection to 192.168.153.130 closed.
[hadoop@hadoop-03 ~]$
这样三台机器都可以互相免密钥访问, ssh-copy-id会以追加的方式进行密钥的分发.
在root@hadoop-01上面上传下载软件,然后使用scp分发到02、03节点,速度更快.
5.安装jdk(三台主机jdk安装)
[root@hadoop-01 ~]# rpm -ivh jdk-8u151-linux-x64.rpm
Preparing... ########################################### [100%]
1:jdk1.8 ########################################### [100%]
[root@hadoop-01 ~]# export JAVA_HOME=/usr/java/jdk1.8.0_151/
[root@hadoop-01 ~]# export PATH=$JAVA_HOME/bin:$PATH
[root@hadoop-01 ~]# java -version
java version "1.8.0_151"
Java(TM) SE Runtime Environment (build 1.8.0_151-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)
6、安装hadoop:
[hadoop@hadoop-01~]$ wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.7.4/hadoop-2.7.4-src.tar.gz
[hadoop@hadoop-01 ~]$ sudo tar zxvf hadoop-2.7.4.tar.gz -C /home/hadoop/ && cd /home/hadoop
[hadoop@hadoop-01 ~]$ sudo mv hadoop-2.7.4/ hadoop
[hadoop@hadoop-01 ~]$ sudo chown -R hadoop:hadoop hadoop/
#将hadoop的二进制目录添加到PATH变量,并设置HADOOP_HOME环境变量
[hadoop@hadoop-01 ~]$ export HADOOP_HOME=/home/hadoop/hadoop/
[hadoop@hadoop-01 ~]$ export PATH=$HADOOP_HOME/bin:$PATH
二.配置文件修改
修改hadoop的配置文件.
配置文件位置:/home/hadoop/hadoop/etc/hadoop
1.修改hadoop-env.sh配置文件,指定JAVA_HOME为JAVA的安装路径
export JAVA_HOME=${JAVA_HOME}
修改为:
export JAVA_HOME=/usr/java/jdk1.8.0_151/
2. 修改yarn-env.sh文件.
指定yran框架的java运行环境,该文件是yarn框架运行环境的配置文件,需要修改JAVA_HOME的位置
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
修改为:
export JAVA_HOME=/usr/java/jdk1.8.0_151/
3. 修改slaves文件.
指定DataNode数据存储服务器,将所有的DataNode的机器的主机名写入到此文件中,如下:
[hadoop@hadoop-01 hadoop]$ cat slaves
hadoop-02
hadoop-03
4.修改core-site.xml文件.在<configuration>……</configuration>中添加如下:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-01:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
5. 修改hdfs-site.xml配置文件,在<configuration>……</configuration>中添加如下:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-:</value>
<description># 通过web界面来查看HDFS状态 </description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value></value>
<description># 每个Block有2个备份</description>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
6. 修改mapred-site.xml
指定Hadoop的MapReduce运行在YARN环境
[hadoop@hadoop- hadoop]$ cp mapred-site.xml.template mapred-site.xml
[hadoop@hadoop- hadoop]$ vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-:</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-:</value>
</property>
</configuration>
7.> 修改yarn-site.xml
#该文件为yarn架构的相关配置
<configuration>
<!-- Site specific YARN configuration properties --> <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop-:</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop-:</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop-:</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop-:</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop-:</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value></value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value></value>
</property>
</configuration>
三.节点分发
复制hadoop到其他节点
[hadoop@hadoop-01 ~]$ scp -r /home/hadoop/hadoop/ 192.168.153.129:/home/hadoop/
[hadoop@hadoop-01 ~]$ scp -r /home/hadoop/hadoop/ 192.168.153.130:/home/hadoop/
四、初始化及服务启停.
1.在hadoop-01使用hadoop用户初始化NameNode.
[hadoop@hadoop-01 ~]$ /home/hadoop/hadoop/bin/hdfs namenode -format
17/10/28 22:54:33 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop-01/192.168.153.128
************************************************************/
[hadoop@hadoop-01 ~]$ echo $?
0
说明执行成功.
[root@localhost ~]# tree /home/hadoop/dfs
/home/hadoop/dfs
├── data
└── name
└── current
├── fsimage_0000000000000000000
├── fsimage_0000000000000000000.md5
├── seen_txid
└── VERSION
2.启停hadoop服务:
/home/hadoop/hadoop/sbin/start-dfs.sh
/home/hadoop/hadoop/sbin/stop-dfs.sh
启动服务:
[hadoop@hadoop-01 ~]$ /home/hadoop/hadoop/sbin/start-dfs.sh
Starting namenodes on [hadoop-01]
hadoop-01: starting namenode, logging to /home/hadoop/hadoop/logs/hadoop-hadoop-namenode-hadoop-01.out
hadoop-03: starting datanode, logging to /home/hadoop/hadoop/logs/hadoop-hadoop-datanode-hadoop-03.out
hadoop-02: starting datanode, logging to /home/hadoop/hadoop/logs/hadoop-hadoop-datanode-hadoop-02.out
Starting secondary namenodes [hadoop-01]
hadoop-01: starting secondarynamenode, logging to /home/hadoop/hadoop/logs/hadoop-hadoop-secondarynamenode-hadoop-01.out
3.查看服务状态.
namenode节点(hadoop-01)上面查看进程
[hadoop@hadoop-01 ~]$ps aux | grep --color namenode
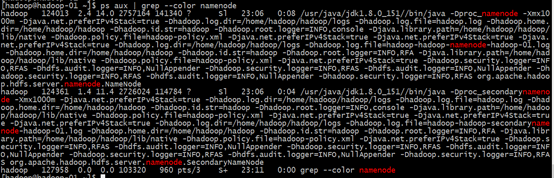
或者使用jps查看是否有namenode进程

#DataNode上面查看进程(在hadoop-02、hadoop-03)上查看
#ps aux | grep --color datanode


或者jps命令查看:

4.启动yarn分布式计算框架:
在 hadoop-01上启动ResourceManager
[hadoop@hadoop-01 ~]$ /home/hadoop/hadoop/sbin/start-yarn.sh starting yarn daemons
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop/logs/yarn-hadoop-resourcemanager-hadoop-01.out
hadoop-02: starting nodemanager, logging to /home/hadoop/hadoop/logs/yarn-hadoop-nodemanager-hadoop-02.out
hadoop-03: starting nodemanager, logging to /home/hadoop/hadoop/logs/yarn-hadoop-nodemanager-hadoop-03.out
[hadoop@hadoop-01 ~]$
#NameNode节点上查看进程

#DataNode节点上查看进程nodemanager进程.
[hadoop@hadoop-02 ~]$ ps aux |grep --color nodemanager
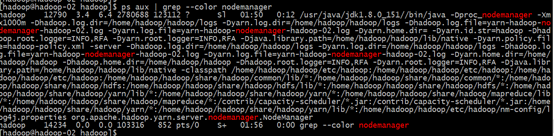
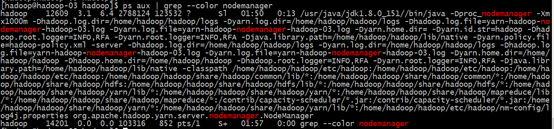
5.启动jobhistory服务,查看mapreduce状态
#在NameNode节点上
[hadoop@hadoop-01 ~]$ /home/hadoop/hadoop/sbin/mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /home/hadoop/hadoop/logs/mapred-hadoop-historyserver-hadoop-01.out
至此单节点namenode的集群环境部署完成,单节点的启停操作都是在nameserve(hadoop-01)端操作的
注:start-dfs.sh和start-yarn.sh这两个脚本可用start-all.sh代替
/home/hadoop/hadoop/sbin/stop-all.sh
/home/hadoop/hadoop/sbin/start-all.sh
启动:
[hadoop@hadoop-01 hadoop]$ /home/hadoop/hadoop/sbin/start-all.sh


[hadoop@hadoop-01 hadoop]$ /home/hadoop/hadoop/sbin/stop-all.sh
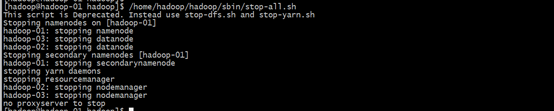
6.查看HDFS分布式文件系统状态
[hadoop@hadoop-01 ~]$ /home/hadoop/hadoop/bin/hdfs dfsadmin -report
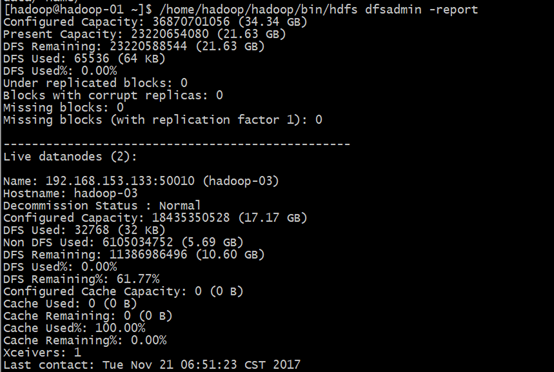
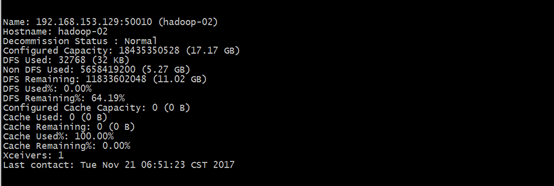
#查看文件块组成,一个文件由那些块组成
[hadoop@hadoop-01 ~]$ /home/hadoop/hadoop/bin/hdfs fsck / -files -blocks
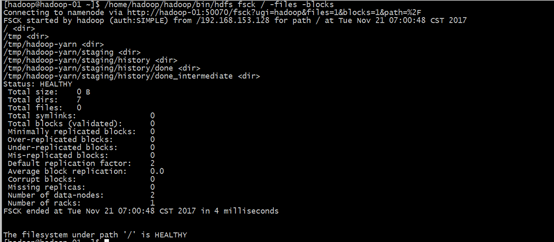
web页面查看hadoop集群状态
查看HDFS状态:http://192.168.153.128:50070
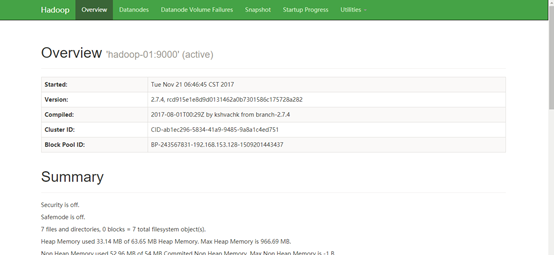
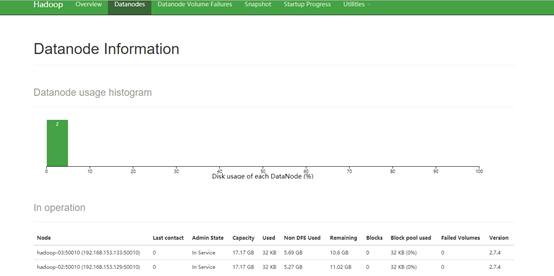
查看Hadoop集群状态: http://192.168.153.128:8088/cluster

登录web也成功,至此环境部署完成.
Hadoop分布式集群部署(单namenode节点)的更多相关文章
- Hadoop教程(五)Hadoop分布式集群部署安装
Hadoop教程(五)Hadoop分布式集群部署安装 1 Hadoop分布式集群部署安装 在hadoop2.0中通常由两个NameNode组成,一个处于active状态,还有一个处于standby状态 ...
- hadoop分布式集群部署①
Linux系统的安装和配置.(在VM虚拟机上) 一:安装虚拟机VMware Workstation 14 Pro 以上,虚拟机软件安装完成. 二:创建虚拟机. 三:安装CentOS系统 (1)上面步 ...
- 大数据系列之Hadoop分布式集群部署
本节目的:搭建Hadoop分布式集群环境 环境准备 LZ用OS X系统 ,安装两台Linux虚拟机,Linux系统用的是CentOS6.5:Master Ip:10.211.55.3 ,Slave ...
- Hadoop实战:Hadoop分布式集群部署(一)
一.系统参数优化配置 1.1 系统内核参数优化配置 修改文件/etc/sysctl.conf,使用sysctl -p命令即时生效. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ...
- Hadoop分布式集群部署
环境准备 IP HOSTNAME SYSTEM 192.168.131.129 hadoop-master CentOS 7.6 192.168.131.135 hadoop-slave1 CentO ...
- Hadoop(HA)分布式集群部署
Hadoop(HA)分布式集群部署和单节点namenode部署其实一样,只是配置文件的不同罢了. 这篇就讲解hadoop双namenode的部署,实现高可用. 系统环境: OS: CentOS 6.8 ...
- 一脸懵逼学习Hadoop分布式集群HA模式部署(七台机器跑集群)
1)集群规划:主机名 IP 安装的软件 运行的进程master 192.168.199.130 jdk.hadoop ...
- 基于Hadoop分布式集群YARN模式下的TensorFlowOnSpark平台搭建
1. 介绍 在过去几年中,神经网络已经有了很壮观的进展,现在他们几乎已经是图像识别和自动翻译领域中最强者[1].为了从海量数据中获得洞察力,需要部署分布式深度学习.现有的DL框架通常需要为深度学习设置 ...
- 使用Docker在本地搭建Hadoop分布式集群
学习Hadoop集群环境搭建是Hadoop入门必经之路.搭建分布式集群通常有两个办法: 要么找多台机器来部署(常常找不到机器) 或者在本地开多个虚拟机(开销很大,对宿主机器性能要求高,光是安装多个虚拟 ...
随机推荐
- SVN文件加锁
原文:SVN与TortoiseSVN实战:文件加锁详解 加锁与解锁的操作对于项目中的二进制文件,如图片.声音.动态库等不可合并文件是非常有用的,可以让这些文件防止产生恼人的冲突,但TortoiseSV ...
- 安装VCSA6.5(vCenter Server Appliance 6.5)
相关文章:http://www.ctoclubs.com/?p=756 一.简介 VCSA(vCenter Server Appliance 6.5),相对于Windows版本的vCenter,VCS ...
- LeetCode: Binary Tree Level Order Traversal 解题报告
Binary Tree Level Order Traversal Given a binary tree, return the level order traversal of its nodes ...
- Windows系统盘瘦身指南
[本文出自天外归云的博客园] Windows系统的C盘空间越来越小,按以下四步进行清理,还你6个G: 1.开启腾讯管家之类的软件进行第一轮垃圾清理: 2.删除以下文件夹,"C:\Progra ...
- Android studio动态调试
Reference: http://cstsinghua.github.io/2016/06/13/Android%20studio%E5%8A%A8%E6%80%81%E8%B0%83%E8%AF ...
- java判断是移动端还是pc端
// \b 是单词边界(连着的两个(字母字符 与 非字母字符) 之间的逻辑上的间隔), // 字符串在编译时会被转码一次,所以是 "\\b" // \B 是单词内部逻辑间隔(连着的 ...
- java程序设计
IP地址计数器 原理:获取用户的IP地址,然后存入数据库,当再次访问时查询数据库是否存在该条数据,即可完成此程序 设计过程 创建一个连接数据库类:DB.java package com.count.O ...
- 出去html中的标签
C#写法 public static string StripHTML(string strHtml) { string strOutput = strHtml; Regex regex = new ...
- Java局部打印的问题
项目中遇到了做局部打印的情况,最开始用的bootstrap,可是实际显示的和打印的效果就不一样了,于是就只能换一种方式了. 打印是用的jqprint 这个插件,很简单好用的插件. 引入两个js就可以了 ...
- CentOS重置Mysql密码
1.首先确认服务器出于安全的状态,也就是没有人能够任意地连接MySQL数据库. 因为在重新设置MySQL的root密码的期间,MySQL数据库完全出于没有密码保护的 状态下,其他的用户也可以任意地登录 ...