并行网络爬虫(C++实现)
step1 使用socket编程技术,利用http协议,抽取网页中的url,实现简单的爬虫。
socket
int socket (int domain, int type, int protocol)
功能描述:初始化创建socket对象。
socket返回值:成功返回非负数的socket描述符;失败返回-1。socket描述符是一个指向内部数据结构的指针,它指向描述符表入口。
step2 使用bloomfilter,对爬到的url进行去重,避免重复爬取相同页面。
step3 使用libevent的事件驱动设计模式,基于kqueue的io多路复用,加快爬虫速度。
笔者使用Mac OS,采用kqueue(os free based)实现io多路复用。LInux下可使用epoll 。
文件描述符(file descriptor,fd)
每一个进程都在进程控制块(PCB)中有一份文件描述符表,而文件描述符就是这个表的索引。这张表中有一项是指向file结构体,file结构体是内核中用来描述文件属性的结构体。
Mac下安装libevent包,以及Xcode编译配置
1 在官网 http://libevent.org 下载最新稳定版压缩安装包
2 解压并执行如下命令
sudo ./configure
sudo make
sudo make install
将安装在 /user/local/ 下,include下是头文件,lib下是动态链接库之类的,bin下也有一些相关文件。
用Xcode编译含libevent的程序,头文件路径和库的查找路径如下配置

此外,我将lib下的库都加了进来。
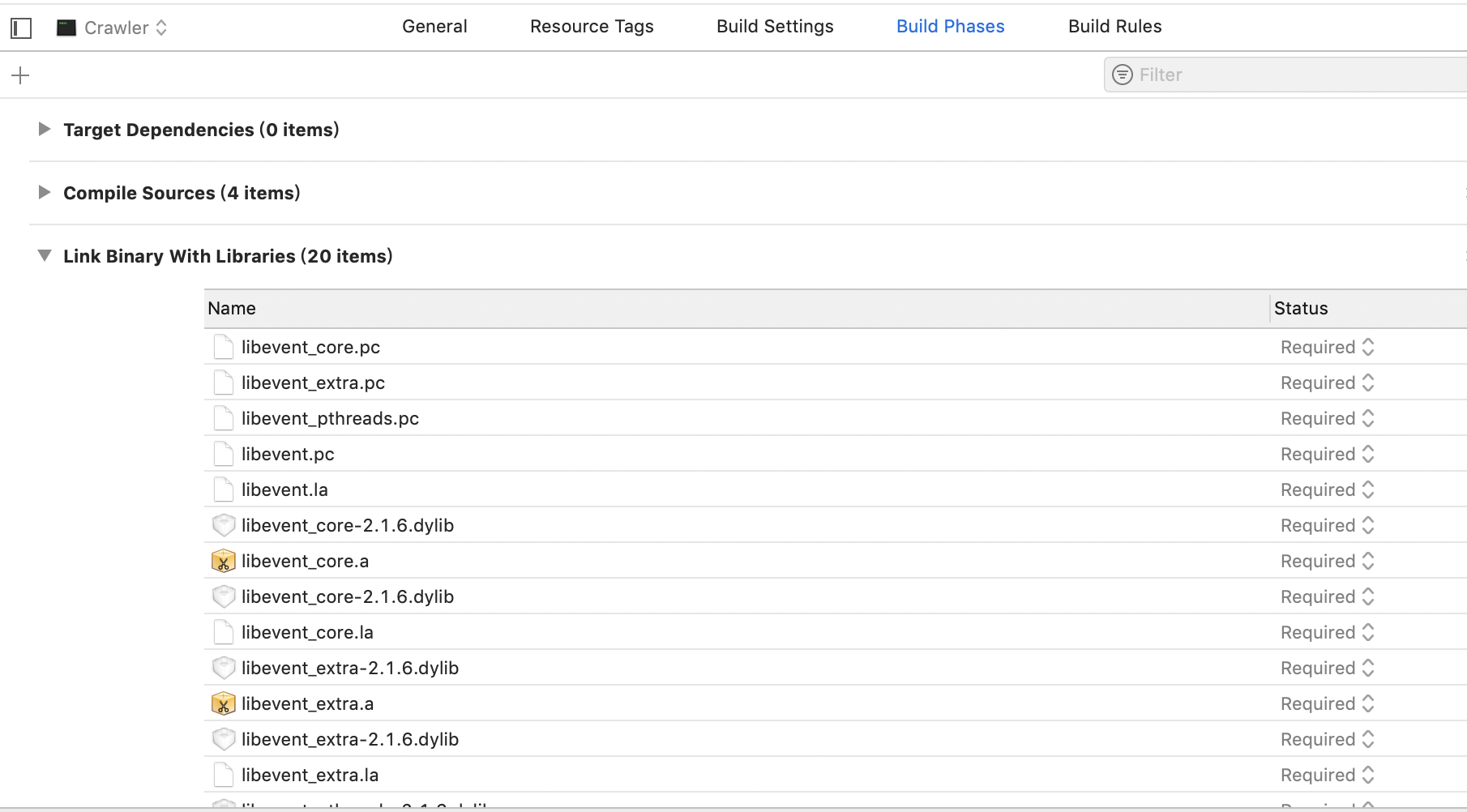
编译成功!
socket编程——bind()函数
因为step3想用listen()来侦听一定端口的数据,故使用bind()将套接字和机器上的一定的端口关联起来是必须的步骤。而之前的step1的实现并不需要使用bind()函数。
#include <sys/types.h>
#include <sys/socket.h>
int bind(int sockfd, struct sockaddr *my_addr, int addrlen);
sockfd 是调用 socket 返回的文件描述符。my_addr 是指向数据结构 struct sockaddr 的指针,它保存你的地址(即端口和 IP 地址) 信息。 addrlen 设置为 sizeof(struct sockaddr)。
参考
http://www.cnblogs.com/kefeiGame/p/7246942.html
https://www.cnblogs.com/yuqiao/p/5786427.html
https://blog.csdn.net/liufang1991/article/details/51096258
并行网络爬虫(C++实现)的更多相关文章
- Atitit.数据检索与网络爬虫与数据采集的原理概论
Atitit.数据检索与网络爬虫与数据采集的原理概论 1. 信息检索1 1.1. <信息检索导论>((美)曼宁...)[简介_书评_在线阅读] - dangdang.html1 1.2. ...
- larbin是一种开源的网络爬虫/网络蜘
larbin是一种开源的网络爬虫/网络蜘蛛,由法国的年轻人 Sébastien Ailleret独立开发.larbin目的是能够跟踪页面的url进行扩展的抓取,最后为搜索引擎提供广泛的数据来源.Lar ...
- [原创]手把手教你写网络爬虫(5):PhantomJS实战
手把手教你写网络爬虫(5) 作者:拓海 摘要:从零开始写爬虫,初学者的速成指南! 封面: 大家好!从今天开始,我要与大家一起打造一个属于我们自己的分布式爬虫平台,同时也会对涉及到的技术进行详细介绍.大 ...
- 一个大数据方案:基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
网络爬虫架构在Nutch+Hadoop之上,是一个典型的分布式离线批量处理架构,有非常优异的吞吐量和抓取性能并提供了大量的配置定制选项.由于网络爬虫只负责网络资源的抓取,所以,需要一个分布式搜索引擎, ...
- 《精通python网络爬虫》笔记
<精通python网络爬虫>韦玮 著 目录结构 第一章 什么是网络爬虫 第二章 爬虫技能概览 第三章 爬虫实现原理与实现技术 第四章 Urllib库与URLError异常处理 第五章 正则 ...
- PID控制器的应用:控制网络爬虫抓取速度
一.初识PID控制器 冬天乡下人喜欢烤火取暖,常见的情形就是四人围着麻将桌,桌底放一盆碳火.有人觉得火不够大,那加点木炭吧,还不够,再加点.片刻之后,又觉得火太大,脚都快被烤熟了,那就取出一些木碳…… ...
- 【架构】基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
网络爬虫架构在Nutch+Hadoop之上,是一个典型的分布式离线批量处理架构,有非常优异的吞吐量和抓取性能并提供了大量的配置定制选项.由于网络爬虫只负责网络资源的抓取,所以,需要一个分布式搜索引擎, ...
- Python学习网络爬虫--转
原文地址:https://github.com/lining0806/PythonSpiderNotes Python学习网络爬虫主要分3个大的版块:抓取,分析,存储 另外,比较常用的爬虫框架Scra ...
- 用Python写网络爬虫 第二版
书籍介绍 书名:用 Python 写网络爬虫(第2版) 内容简介:本书包括网络爬虫的定义以及如何爬取网站,如何使用几种库从网页中抽取数据,如何通过缓存结果避免重复下载的问题,如何通过并行下载来加速数据 ...
随机推荐
- PHP中Notice: unserialize(): Error at offset of bytes in on line 的解决方法
使用unserialize函数将数据储存到数据库的时候遇到了这个报错,后来发现是将gb2312转换成utf-8格式之后,每个中文的字节数从2个增加到3个之后导致了反序列化的时候判断字符长度出现了问题, ...
- ThreadLoacl 小记
参考地址: https://www.cnblogs.com/dolphin0520/p/3920407.html ThreadLoacl 本地线程变量 为线程创建一个副本, 一个内部类ThreadLo ...
- Linux kafka 单机安装
Kafka地址(选择最新地址1.1.1) http://archive.apache.org/dist/kafka/
- Centos6 下安装Nginx+Mysql+PHP
安装nginx https://segmentfault.com/a/1190000007928556 添加源 $ wget http://nginx.org/packages/centos/6/no ...
- ABAP-折叠窗口
1.测试 2.代码 *&---------------------------------------------------------------------* *& Report ...
- ORM一对多查询对象
正向查询: 取人民日报出版社出版的所有书籍 方式一: pub_obj = Publish.objects.filter(name='人民日报')[0] ret = Book.objects.filte ...
- 使用ubuntu远程连接windows, Connect to a Windows PC from Ubuntu via Remote Desktop Connection
from: https://www.digitalcitizen.life/connecting-windows-remote-desktop-ubuntu NOTE: This tutorial w ...
- 如何让cxgrid自动调整列宽
1.选中cxgridview,在属性中找OptionsView--->ColumAutoWidth,把这个属性设为True; 2.在FDMemtable的open之后加上如下代码即可 [delp ...
- 一个Tparams小测试
var aParams: TParams; aPar: TParam; I:Integer; begin aParams := TParams.Create(nil); aPar := aParams ...
- How to Pronounce Numbers 11 – 19
How to Pronounce Numbers 11 – 19 Share Tweet Share Tagged With: Numbers Numbers are something you’ll ...