TensorBoard 简介及使用流程【转】
转自:https://blog.csdn.net/gsww404/article/details/78605784
仅供学习参考,转载地址:http://blog.csdn.net/mzpmzk/article/details/77914941
一、TensorBoard 简介及使用流程
1、TensoBoard 简介
TensorBoard 和 TensorFLow 程序跑在不同的进程中,TensorBoard 会自动读取最新的 TensorFlow 日志文件,并呈现当前 TensorFLow 程序运行的最新状态。
2、TensorBoard 使用流程
- 添加记录节点:
tf.summary.scalar/image/histogram()等- 汇总记录节点:
merged = tf.summary.merge_all()- 运行汇总节点:
summary = sess.run(merged),得到汇总结果- 日志书写器实例化:
summary_writer = tf.summary.FileWriter(logdir, graph=sess.graph),实例化的同时传入 graph 将当前计算图写入日志- 调用日志书写器实例对象
summary_writer的add_summary(summary, global_step=i)方法将所有汇总日志写入文件- 调用日志书写器实例对象
summary_writer的close()方法写入内存,否则它每隔120s写入一次
二、TensorFlow 可视化分类
1、计算图的可视化:add_graph()
...create a graph...
# Launch the graph in a session.
sess = tf.Session()
# Create a summary writer, add the 'graph' to the event file.
writer = tf.summary.FileWriter(logdir, sess.graph)
writer.close() # 关闭时写入内存,否则它每隔120s写入一次- 1
- 2
- 3
- 4
- 5
- 6
2、监控指标的可视化:add_summary()
I、SCALAR
tf.summary.scalar(name, tensor, collections=None, family=None)
可视化训练过程中随着迭代次数准确率(val acc)、损失值(train/test loss)、学习率(learning rate)、每一层的权重和偏置的统计量(mean、std、max/min)等的变化曲线
输入参数:
- name:此操作节点的名字,TensorBoard 中绘制的图形的纵轴也将使用此名字
- tensor: 需要监控的变量 A real numeric Tensor containing a single value.
输出:
- A scalar Tensor of type string. Which contains a Summary protobuf.
II、IMAGE
tf.summary.image(name, tensor, max_outputs=3, collections=None, family=None)
可视化
当前轮训练使用的训练/测试图片或者 feature maps输入参数:
- name:此操作节点的名字,TensorBoard 中绘制的图形的纵轴也将使用此名字
- tensor: A r A 4-D uint8 or float32 Tensor of shape
[batch_size, height, width, channels]where channels is 1, 3, or 4- max_outputs:Max number of batch elements to generate images for
输出:
- A scalar Tensor of type string. Which contains a Summary protobuf.
III、HISTOGRAM
tf.summary.histogram(name, values, collections=None, family=None)
可视化张量的取值分布
输入参数:
- name:此操作节点的名字,TensorBoard 中绘制的图形的纵轴也将使用此名字
- tensor: A real numeric Tensor. Any shape. Values to use to build the histogram
输出:
- A scalar Tensor of type string. Which contains a Summary protobuf.
IV、MERGE_ALL
tf.summary.merge_all(key=tf.GraphKeys.SUMMARIES)
- Merges all summaries collected in the default graph
- 因为程序中定义的写日志操作比较多,一一调用非常麻烦,所以TensoorFlow 提供了此函数来整理所有的日志生成操作,eg:
merged = tf.summary.merge_all ()- 此操作不会立即执行,所以,需要明确的运行这个操作(
summary = sess.run(merged))来得到汇总结果- 最后调用日志书写器实例对象的
add_summary(summary, global_step=i)方法将所有汇总日志写入文件
3、多个事件(event)的可视化:add_event()
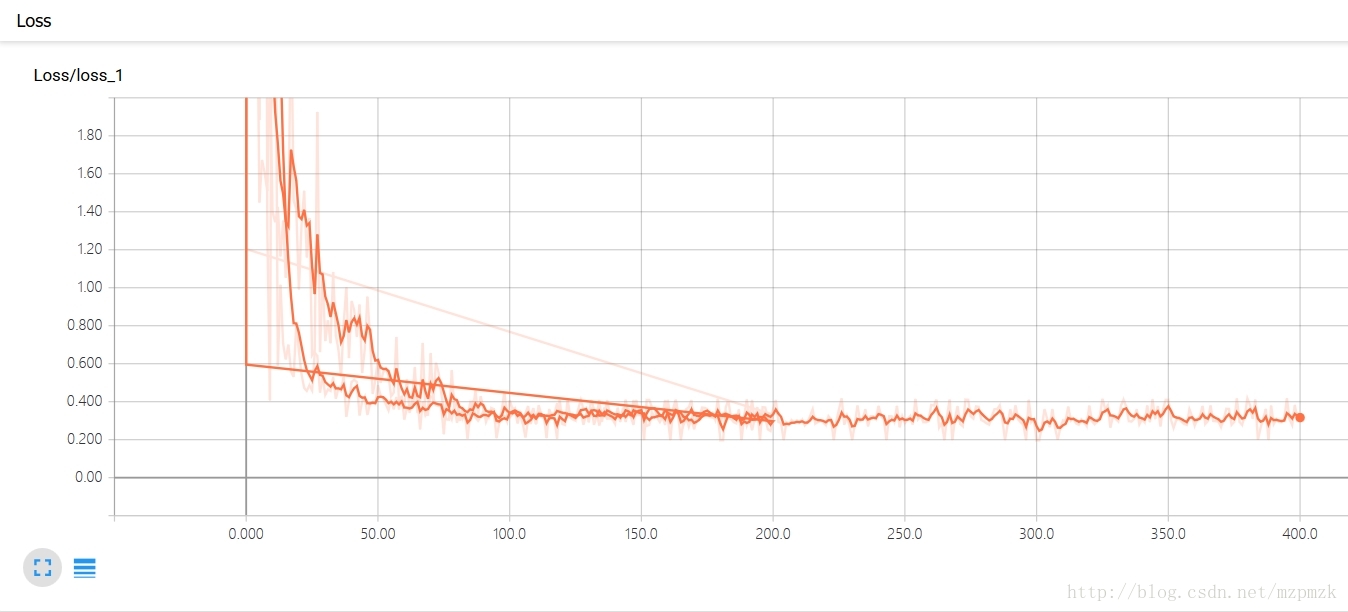
- 如果 logdir 目录的子目录中包含另一次运行时的数据(多个 event),那么 TensorBoard 会展示所有运行的数据(主要是scalar),这样可以用于比较不同参数下模型的效果,调节模型的参数,让其达到最好的效果!
- 上面那条线是迭代200次的loss曲线图,下面那条是迭代400次的曲线图,程序见最后。
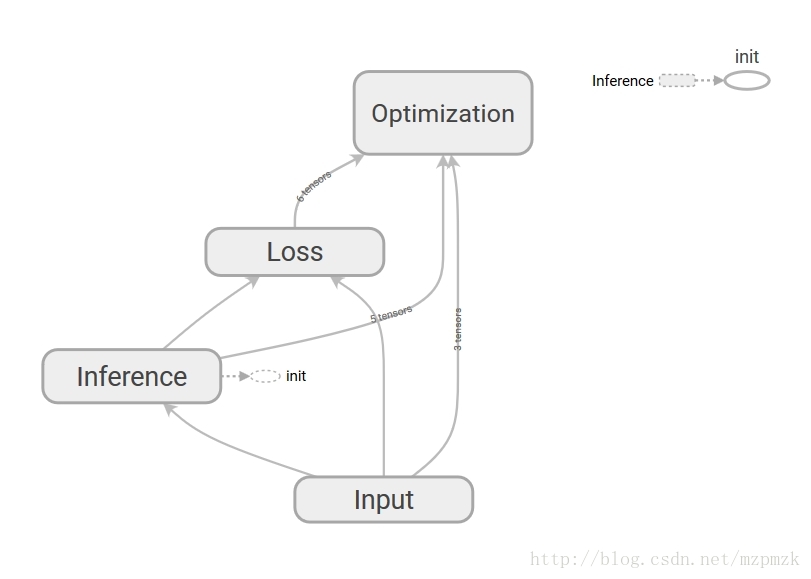
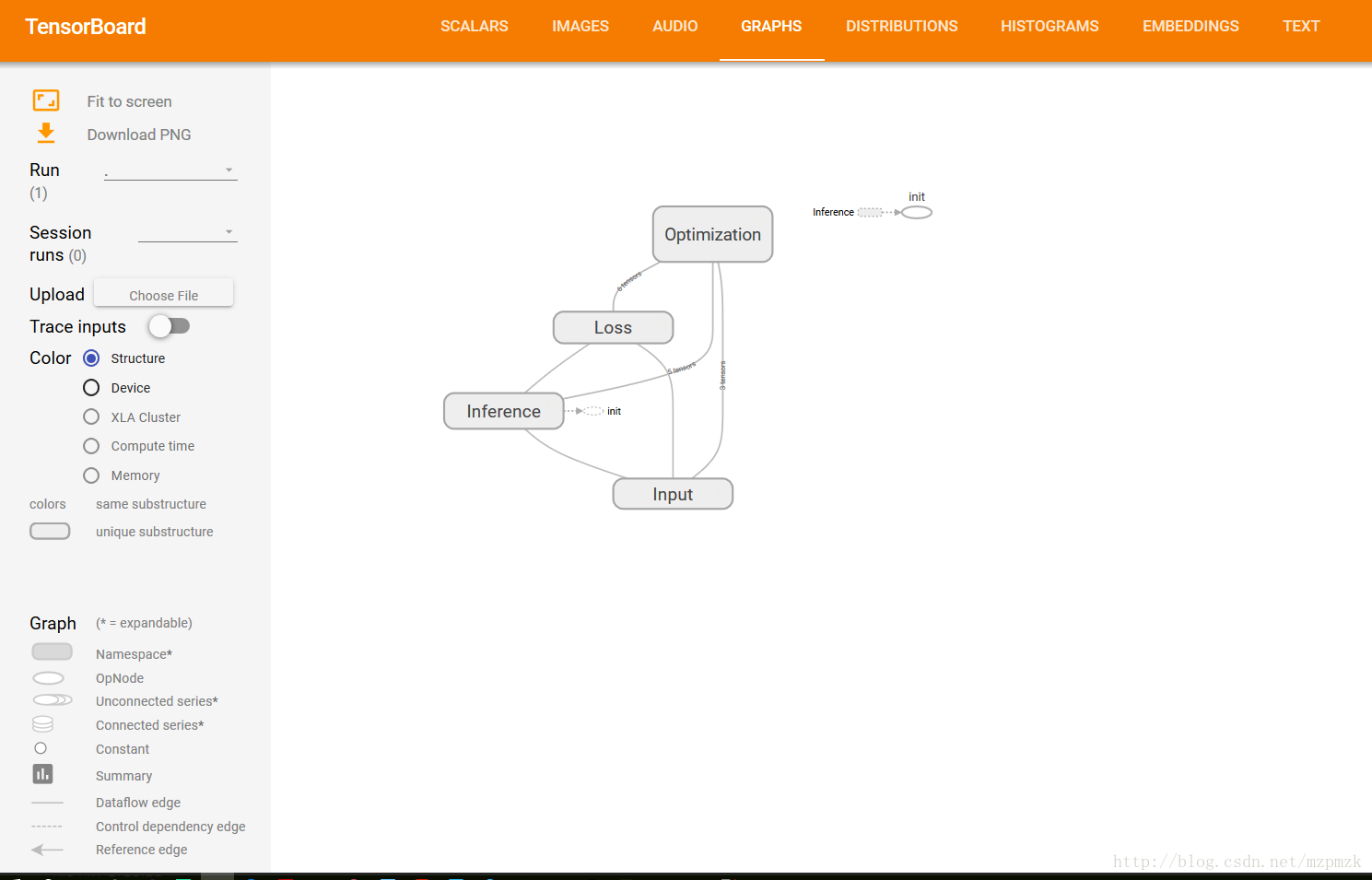
三、通过命名空间美化计算图
- 使用命名空间使可视化效果图更有层次性,使得神经网络的整体结构不会被过多的细节所淹没
- 同一个命名空间下的所有节点会被缩略成一个节点,只有顶层命名空间中的节点才会被显示在 TensorBoard 可视化效果图上
- 可通过
tf.name_scope()或者tf.variable_scope()来实现,具体见最后的程序。
四、将所有日志写入到文件:tf.summary.FileWriter()
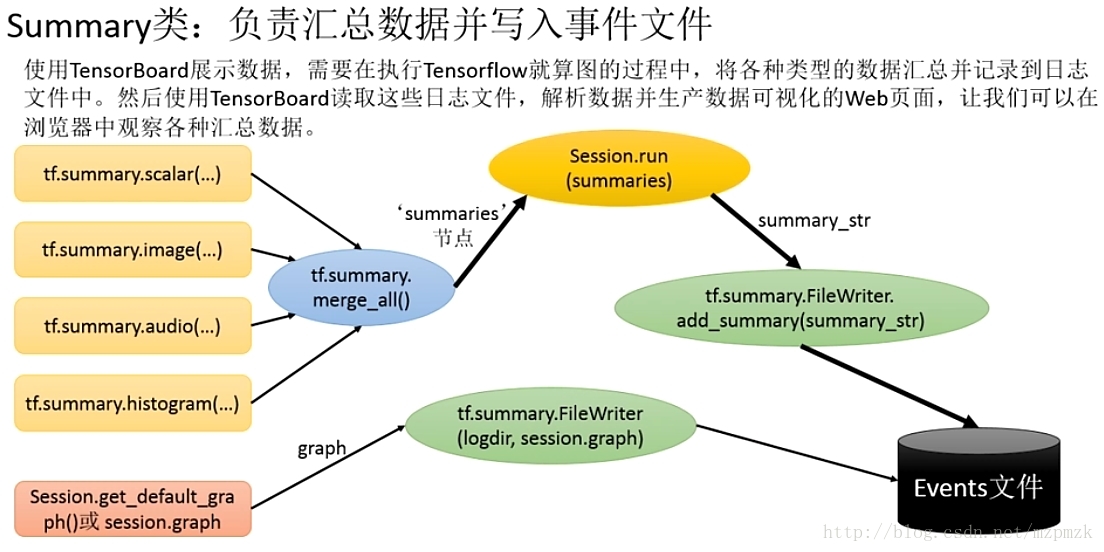
tf.summary.FileWriter(logdir, graph=None, flush_secs=120, max_queue=10)
- 负责将事件日志(graph、scalar/image/histogram、event)写入到指定的文件中
初始化参数:
- logdir:事件写入的目录
- graph:如果在初始化的时候传入
sess,graph的话,相当于调用add_graph()方法,用于计算图的可视化- flush_sec:How often, in seconds, to flush the
added summaries and eventsto disk.- max_queue:Maximum number of
summaries or eventspending to be written to disk before one of the ‘add’ calls block.其它常用方法:
add_event(event):Adds an event to the event fileadd_graph(graph, global_step=None):Adds a Graph to the event file,Most users pass a graph in the constructor insteadadd_summary(summary, global_step=None):Adds a Summary protocol buffer to the event file,一定注意要传入 global_stepclose():Flushes the event file to disk and close the fileflush():Flushes the event file to diskadd_meta_graph(meta_graph_def,global_step=None)add_run_metadata(run_metadata, tag, global_step=None)
五、启动 TensorBoard 展示所有日志图表
1. 通过 Windows 下的 cmd 启动
- 运行你的程序,在指定目录下(
logs)生成event文件 - 在
logs所在目录,按住shift键,点击右键选择在此处打开cmd - 在
cmd中,输入以下命令启动tensorboard --logdir=logs,注意:logs的目录并不需要加引号, logs 中有多个event 时,会生成scalar 的对比图,但 graph 只会展示最新的结果 - 把下面生成的网址(
http://DESKTOP-S2Q1MOS:6006 # 每个人的可能不一样) copy 到浏览器中打开即可

2. 通过 Ubuntu下的 bash 启动
- 运行你的程序(
python my_program.py),在指定目录下(logs)生成event文件 - 在
bash中,输入以下命令启动tensorboard,注意:logs的目录并不需要加引号,端口号必须是事先在路由器中配置好的
--logdir=logs --port=8888 - 把下面生成的网址(
http://ubuntu16:8888 # 把ubuntu16 换成服务器的外部ip地址即可) copy 到本地浏览器中打开即可

六、使用 TF 实现一元线性回归(并使用 TensorBoard 可视化)
- 多个event的
loss对比图以及网络结构图(graph)已经在上面展示了,这里就不重复了。- 最下面展示了网络的训练过程以及最终拟合效果图
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# 准备训练数据,假设其分布大致符合 y = 1.2x + 0.0
n_train_samples = 200
X_train = np.linspace(-5, 5, n_train_samples)
Y_train = 1.2*X_train + np.random.uniform(-1.0, 1.0, n_train_samples) # 加一点随机扰动
# 准备验证数据,用于验证模型的好坏
n_test_samples = 50
X_test = np.linspace(-5, 5, n_test_samples)
Y_test = 1.2*X_test
# 参数学习算法相关变量设置
learning_rate = 0.01
batch_size = 20
summary_dir = 'logs'
print('~~~~~~~~~~开始设计计算图~~~~~~~~')
# 使用 placeholder 将训练数据/验证数据送入网络进行训练/验证
# shape=None 表示形状由送入的张量的形状来确定
with tf.name_scope('Input'):
X = tf.placeholder(dtype=tf.float32, shape=None, name='X')
Y = tf.placeholder(dtype=tf.float32, shape=None, name='Y')
# 决策函数(参数初始化)
with tf.name_scope('Inference'):
W = tf.Variable(initial_value=tf.truncated_normal(shape=[1]), name='weight')
b = tf.Variable(initial_value=tf.truncated_normal(shape=[1]), name='bias')
Y_pred = tf.multiply(X, W) + b
# 损失函数(MSE)
with tf.name_scope('Loss'):
loss = tf.reduce_mean(tf.square(Y_pred - Y), name='loss')
tf.summary.scalar('loss', loss)
# 参数学习算法(Mini-batch SGD)
with tf.name_scope('Optimization'):
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
# 初始化所有变量
init = tf.global_variables_initializer()
# 汇总记录节点
merge = tf.summary.merge_all()
# 开启会话,进行训练
with tf.Session() as sess:
sess.run(init)
summary_writer = tf.summary.FileWriter(logdir=summary_dir, graph=sess.graph)
for i in range(201):
j = np.random.randint(0, 10) # 总共200训练数据,分十份[0, 9]
X_batch = X_train[batch_size*j: batch_size*(j+1)]
Y_batch = Y_train[batch_size*j: batch_size*(j+1)]
_, summary, train_loss, W_pred, b_pred = sess.run([optimizer, merge, loss, W, b], feed_dict={X: X_batch, Y: Y_batch})
test_loss = sess.run(loss, feed_dict={X: X_test, Y: Y_test})
# 将所有日志写入文件
summary_writer.add_summary(summary, global_step=i)
print('step:{}, losses:{}, test_loss:{}, w_pred:{}, b_pred:{}'.format(i, train_loss, test_loss, W_pred[0], b_pred[0]))
if i == 200:
# plot the results
plt.plot(X_train, Y_train, 'bo', label='Train data')
plt.plot(X_test, Y_test, 'gx', label='Test data')
plt.plot(X_train, X_train * W_pred + b_pred, 'r', label='Predicted data')
plt.legend()
plt.show()
summary_writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90

TensorBoard 简介及使用流程【转】的更多相关文章
- Android系统Recovery工作原理之使用update.zip升级过程分析(九)---updater-script脚本语法简介以及执行流程【转】
本文转载自:http://blog.csdn.net/mu0206mu/article/details/7465603 Android系统Recovery工作原理之使用update.zip ...
- 【转】 Android的NDK开发(1)————Android JNI简介与调用流程
原文网址:http://blog.csdn.net/conowen/article/details/7521340 ****************************************** ...
- Android系统Recovery工作原理之使用update.zip升级过程---updater-script脚本语法简介以及执行流程(转)
目前update-script脚本格式是edify,其与amend有何区别,暂不讨论,我们只分析其中主要的语法,以及脚本的流程控制. 一.update-script脚本语法简介: 我们顺着所生成的脚本 ...
- 信用评分卡(A卡/B卡/C卡)的模型简介及开发流程|干货
https://blog.csdn.net/varyall/article/details/81173326 如今在银行.消费金融公司等各种贷款业务机构,普遍使用信用评分,对客户实行打分制,以期对客户 ...
- Android的NDK开发(1)————Android JNI简介与调用流程
1.JNI简介 JNI全称为Java Native Interface(Java本地调用).从Java1.1开始,JNI成为java平台的一部分,它允许Java代码和其他语言写的代码(如C&C ...
- Spring 框架基础(06):Mvc架构模式简介,执行流程详解
本文源码:GitHub·点这里 || GitEE·点这里 一.SpringMvc框架简介 1.Mvc设计理念 MVC是一种软件设计典范,用一种业务逻辑.数据.界面显示分离的方法组织代码,将业务逻辑聚集 ...
- 【HTTP】一、HTTP协议简介及其工作流程
协议是指计算机通信网络中两台计算机之间进行通信所必须共同遵守的规定或规则,超文本传输协议(HTTP)是一种通信协议,它允许将超文本标记语言(HTML)文档从Web服务器传送到客户端的浏览器. (一 ...
- SpringMVC的简介和工作流程
一.简介 Spring MVC属于SpringFrameWork的后续产品,已经融合在Spring Web Flow里面.Spring 框架提供了构建 Web 应用程序的全功能 MVC 模块.Spri ...
- Tensorboard简介
Tensorflow官方推出了可视化工具Tensorboard,可以帮助我们实现以上功能,它可以将模型训练过程中的各种数据汇总起来存在自定义的路径与日志文件中,然后在指定的web端可视化地展现这些信息 ...
随机推荐
- 睡眠猴子——Alpha阶段项目总结
设想和目标 1. 我们的软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描述? 针对广大失眠人群,尤其是程序猿用户的失眠问题.定义的清楚.描述过. 2. 是否有充足的时间来做计划 ...
- 第二个spring冲刺第9天
其中一个队员在检查程序的BUG途中发现了几个重要的BUG比如答案乱码.程序闪退,弹出黑幕.于是我们决定先把这些问题解决再继续开发其他功能
- Daily Scrum - 11/30
Meeting Minutes 现在有以下一些问题需要解决: 1.保存用户背诵情况的文件输出出了一些问题. 2.UWP开发Debug不太方便啊.老刘说他来加一个Log模块. 3.用户数据的同步有点麻烦 ...
- [转帖] 常见的cmd命令
记录一下 后期用的到. ------------ 1. Echo :显示当前ECHO的状态:ECHO ON 或者ECHO OFF .2. ECHO ON :ECHO状态设为ON,将显示命令行(如每行前 ...
- PHP开发APP接口实现--基本篇
最近一段时间一直在做APP接口,总结一下APP接口开发以来的心得,与大家分享: 1. 客户端/服务器接口请求流程: 安卓/IOS客户端 –> PHP接口 –> 服务器端 –> ...
- Fantacy团队第一次站立会议
1.队名解释 首先队名Fantacy,并没有任何含义,想取幻想(Fantasy)之名,却并非幻想一词,因为我们组的基础并不好,幻想需要有了坚实的基础才能实现,没有基础等于空想.所以我们组的目的是,提升 ...
- 在delphi中我用DBGrid选择多条记录,如何一次把选择的多条记录删掉
procedure TForm1.btnDoSumClick(Sender: TObject);var i: Integer;begin if DBGrid1.SelectedRows.Count ...
- Java学习之String
一.String介绍(引用类型)1.java.lang.String字符串.用""括住的时字符串,都可以看做是实现此类的实例类String中也有许多简单方法 2.特点1).字符串不 ...
- pgm3
这部分主要讨论了一些概念性的东西.一个是常用的 local probabilistic models,一个是如何用 template-based representation. 这部分主要是一些概念, ...
- poj2828 Buy Tickets (线段树 插队问题)
Buy Tickets Time Limit: 4000MS Memory Limit: 65536K Total Submissions: 22097 Accepted: 10834 Des ...