flume用场景及架构原理

Flume是什么

1.flume可以将采集到的数据存储到HDFS上,也可以放在Hbase上。
2.flume就是一个中间插件,他的作用就是屏蔽数据源和数据存储系统的差异。可以在不同的数据源采集数据,因为数据源是多样化的。
数据源的多样化和数据存储系统的多样化,flume作为一个中间插件把数据源和存储系统实现多对多的关系。
Flume的优点

Flume OG与NG区别

Flume NG基本架构
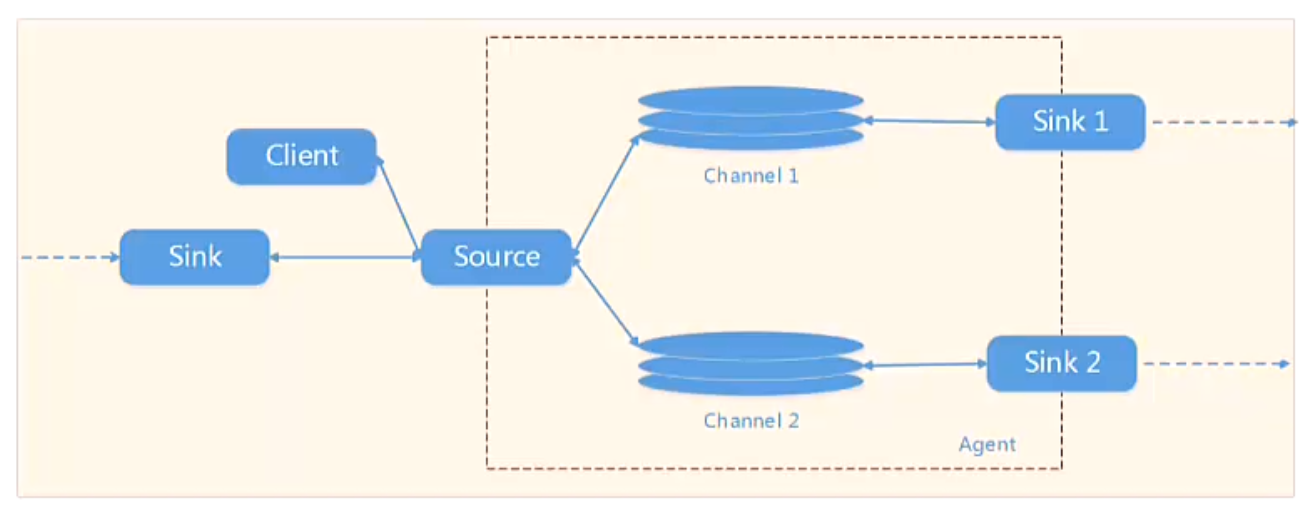
1.Agent由Source 、 channel sink组成。
2.Source是用来获取数据,可以从文本文件中和系统日志中和HTTP中获取数据。Source 获取数据传给后面的Agent
3.channel 在source sink之间作为数据的缓存,sink的数据不能及时传输出去,可以讲数据缓存的内存或者磁盘上面,数据缓存在内存和磁盘中是不同的,在内存中断电了数据就丢失,磁盘的就不会。
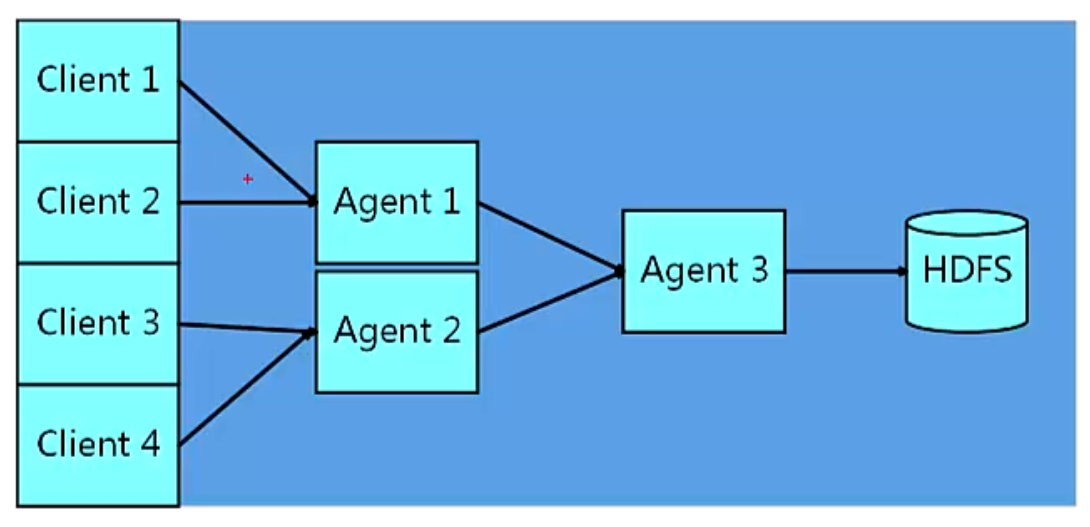
1.Agent3也是可以去掉的,不过在这里起到缓冲的过程。比如说Agent3前面的agent个数非常多,没有经过Agent3的汇总,将会有大量的小文件直接写到HDFS上,非常不利于存储,
因为我们知道HDFS适合存储大文件而不适合大量的小文件。
2.当然如果数据量不大的话就不需要Agent3这样的多级Agent了,根据实际情况来选择适合的方式。
Flume NG核心概念

Flume NG核心概念--Event

Flume NG核心概念--Client

Flume NG核心概念--Agent

Flume NG核心概念--Source
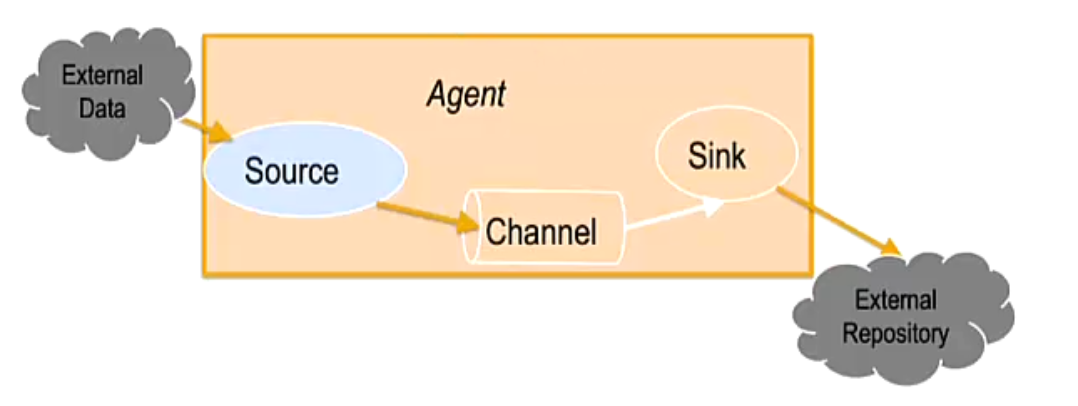

Flume NG核心概念--channel和 sink
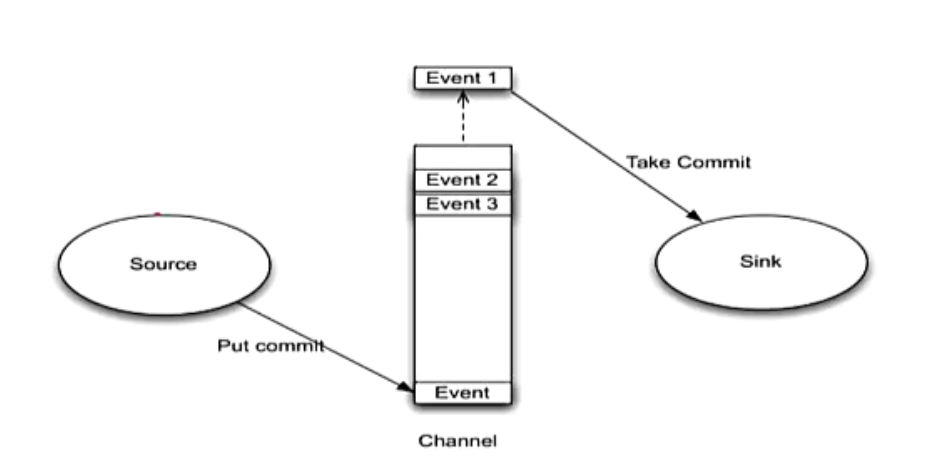
Flume NG核心概念--channel

磁盘channel 是通过预写日志的方式来实现,就是在数据写成功之前先写log,日志写成后我们就任务数据写成功了,如果日志写成功了,数据没写成功,重启之后我们可以通过这个日志来恢复数据
Flume NG核心概念--sink

flume用场景及架构原理的更多相关文章
- Flume应用场景及架构原理
Flume概念 Flume是一个分布式.可靠.和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力. ...
- Hive深入学习--应用场景及架构原理
Hive背景介绍 Hive最初是Facebook为了满足对海量社交网络数据的管理和机器学习的需求而产生和发展的.互联网现在进入了大数据时代,大数据是现在互联网的趋势,而hadoop就是大数据时代里的核 ...
- 深入学习Hive应用场景及架构原理
Hive背景介绍 Hive最初是Facebook为了满足对海量社交网络数据的管理和机器学习的需求而产生和发展的.互联网现在进入了大数据时代,大数据是现在互联网的趋势,而hadoop就是大数据时代里的核 ...
- NET/ASP.NET Routing路由(深入解析路由系统架构原理)(转载)
NET/ASP.NET Routing路由(深入解析路由系统架构原理) 阅读目录: 1.开篇介绍 2.ASP.NET Routing 路由对象模型的位置 3.ASP.NET Routing 路由对象模 ...
- 简单理解Hadoop架构原理
一.前奏 Hadoop是目前大数据领域最主流的一套技术体系,包含了多种技术. 包括HDFS(分布式文件系统),YARN(分布式资源调度系统),MapReduce(分布式计算系统),等等. 有些朋友可能 ...
- Elasticsearch架构原理
架构原理 本书作为 Elastic Stack 指南,关注于 Elasticsearch 在日志和数据分析场景的应用,并不打算对底层的 Lucene 原理或者 Java 编程做详细的介绍,但是 Ela ...
- zz《分布式服务架构 原理、设计与实战》综合
这书以分布式微服务系统为主线,讲解了微服务架构设计.分布式一致性.性能优化等内容,并介绍了与微服务系统紧密联系的日志系统.全局调用链.容器化等. 还是一样,每一章摘抄一些自己觉得有用的内容,归纳整理, ...
- 你懂RocketMQ 的架构原理吗?
前言 前面我们跟大家聊了聊什么是消息中间件,以及哪些场景使用哪些消息中间件更加合适. 我们了解到RocketMQ是java语言开发的,我们能更深入的阅读源码了解它的底层原理,而且它具有优秀的消息中间件 ...
- 大数据体系概览Spark、Spark核心原理、架构原理、Spark特点
大数据体系概览Spark.Spark核心原理.架构原理.Spark特点 大数据体系概览(Spark的地位) 什么是Spark? Spark整体架构 Spark的特点 Spark核心原理 Spark架构 ...
随机推荐
- 替换元素(replace,replace_if,replace_copy,replace_copy_if)
replace 审阅range中的每个元素,把old_value替换为new_value template <class ForwardIterator,class T> void rep ...
- django使用session报错:no such table: django_session
Django版本:1.11.15 使用session的代码:request.session['key'] = value 运行后报错:no such table: django_session 解决办 ...
- 利用Jmeter批量数据库插入数据
1. 启动Jmeter 2. 添加 DBC Connection Configuration 右键线程组->添加->配置元件->JDBC Connection Configu ...
- NET设计模式 第二部分 结构性模式(9):装饰模式(Decorator Pattern)
装饰模式(Decorator Pattern) ——.NET设计模式系列之十 Terrylee,2006年3月 概述 在软件系统中,有时候我们会使用继承来扩展对象的功能,但是由于继承为类型引入的静态特 ...
- 字节数组与String类型的转换
还是本着上篇文章的原则,只不过在Delphi中string有点特殊! 先了解一下Delphi中的string 1. string = AnsiString = 长字符串,理论上长度不受限制,但其实受限 ...
- 如何在Java中获取键盘输入值
程序开发过程中,需要从键盘获取输入值是常有的事,但Java它偏偏就没有像c语言给我们提供的scanf(),C++给我们提供的cin()获取键盘输入值的现成函数!Java没有提供这样的函数也不代表遇到这 ...
- 数据仓库专题(5)-如何构建主题域模型原则之站在巨人的肩上(二)NCR FS-LDM主题域模型划分
一.前言 分布式数据仓库模型的架构设计,受分布式技术的影响,很多有自己特色的地方,但是在概念模型和逻辑模型设计方面,还是有很多可以从传统数据仓库模型进行借鉴的地方.NCR FS-LDM数据模型是金融行 ...
- 4:WPF中查看PDF文件
引用连接:https://www.cnblogs.com/yang-fei/p/4885570.html 在Github上看到一个非常好的WPF中承载PDF文件的类库. https://github. ...
- ALGO-152_蓝桥杯_算法训练_8-2求完数
记: 掌握完数的概念 AC代码: #include <stdio.h> int main(void) { int i,j,sum; ; i <= ; i ++) { sum = ; ...
- 【java】之equals和==区别
Java中数据类型可以分为两类 1.基本数据类型(byte,short,char,int,float,double,long,boolean) 2.复合数据类型(类,String等) Δ在基本数据 ...