MySQL中的排序
在编写SQL 语句时常常会用到 order by 进行排序,那么排序过程是什么样的?为什么有些排序执行比较快,有些排序执行很慢?又该如何去优化?
索引排序
索引排序指的是在通过索引查询时就完成了排序,从而不需要再单独进行排序,效率高。索引排序是通过联合索引实现的。因为联合索引是从最左边的列开始起按大小顺序进行排序,如下图。
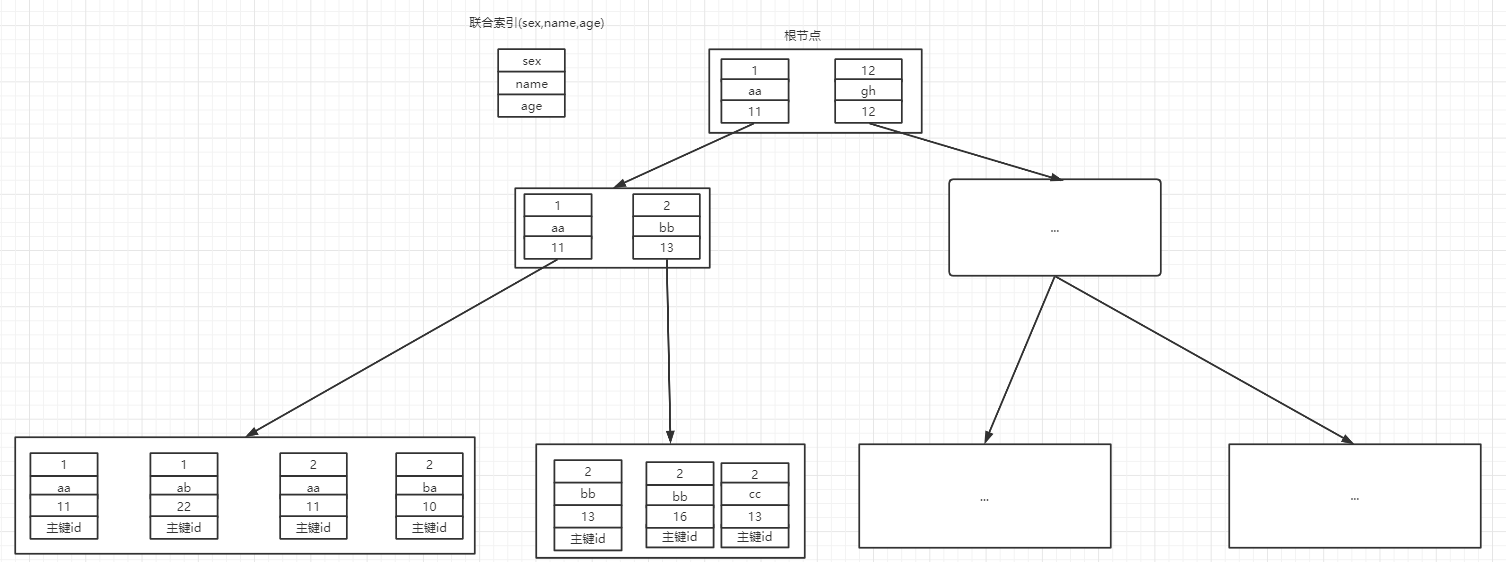
比如现在查询条件是 where sex=1 order by name,那么查询过程就是会找到满足 sex=1 的记录,而符合这条的所有记录一定是按照 name 排序的,所以也不需要额外进行排序。而如果是 where sex >1 order by name,那么根据 sex>1 得到的记录 sex 值并不是固定值,所以得到的记录是按照 sex,其次才是 name 进行排列的。也就没有实现索引排列。
额外排序
额外排序可以分别两种方式来看待。
按执行位置划分
1、Sort_Buffer
MySQL 为每个线程各维护了一块内存区域 sort_buffer ,用于进行排序。sort_buffer 的大小可以通过 sort_buffer_size 来设置。如果用于排序的记录字段总长度小于 sort_buffer_size 便使用 sort_buffer 排序;如果超过则使用 sort_buffer + 临时文件进行排序。
2、Sort_Buffer + 临时文件
MySQL 会使用临时文件搭配 Sort_Buffer 进行排序。主要是使用归并算法来得出最终排序后的结果。临时表会存储主要数据(如果),sort_buffer 存储 rowid(表示行记录的位置标识,主键存在就是主键,不存在会自动创建一个6字节的唯一标识)和用于排序的数据。
临时文件种类:
临时表种类由参数 tmp_table_size 与临时表大小决定,如果内存临时表大小超过 tmp_table_size ,那么就会转成磁盘临时表。因为磁盘临时表在磁盘上,所以使用内存临时表的效率是大于磁盘临时表的。
1、内存临时表
2、磁盘临时表 磁盘临时表默认使用的是 InnoDB,如果想要切换执行引擎,可以修改参数 internal_tmp_disk_storage_engine。
按执行方式划分
执行方式是由 max_length_for_sort_data 参数与用于排序的单条记录字段长度决定的,如果用于排序的单条记录字段长度 <= max_length_for_sort_data ,就使用全字段排序;反之则使用 rowid 排序。
1、全字段排序
全字段排序就是将查询的所有字段全部加载进来进行排序。
优点:查询快,执行过程简单
缺点:需要的空间大。
例子(不考虑临时文件):select city,name,age from t where city='杭州' order by name limit 1000 ; city 有索引
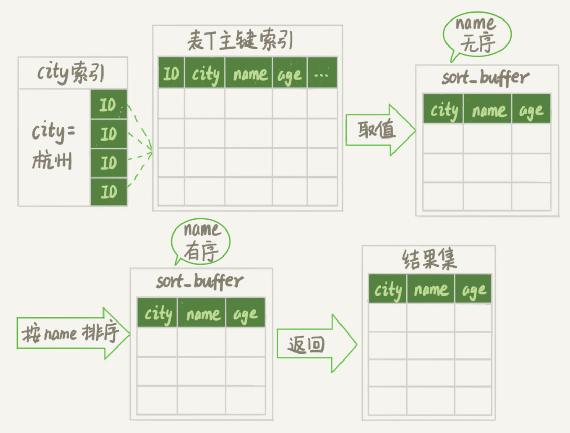
1、初始化 sort_buffer,确定放入两个字段,即 name 和 id;
2、从索引 city 找到第一个满足 city='杭州’条件的主键 id,也就是图中的 ID_X;
3、到主键 id 索引取出整行,取 name、id 这两个字段,存入 sort_buffer 中;
4、从索引 city 取下一个记录的主键 id;
5、重复步骤 3、4 直到不满足 city='杭州’条件为止,也就是图中的 ID_Y;
6、对 sort_buffer 中的数据按照字段 name 进行排序;
7、遍历排序结果,取前 1000 行,并按照 id 的值回到原表中取出 city、name 和 age 三个字段返回给客户端。
2、rowid 排序
rowid 表示位置信息,如果整张表有主键那么 rowid 就是主键,如果没有主键就会自动创建一个 6 字节的唯一标识。所以 rowid 排序就表示只加载用于排序的字段以及 rowid ,然后进行排序,然后根据排序好的 rowid 去表中回表查询所要的结果。
缺点:会产生更多次数的回表查询,查询可能会慢一些。
优点:所需的空间更小。
例子(不考虑临时文件):select city,name,age from t where city='杭州' order by name limit 1000 ; city 有索引
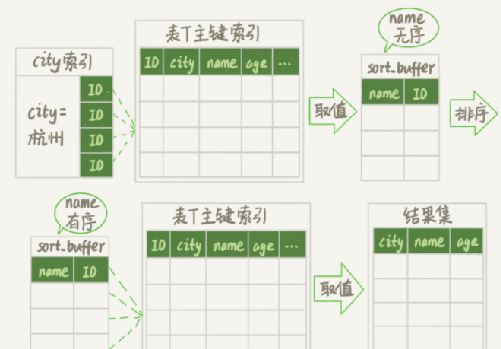
1、初始化 sort_buffer,确定放入两个字段,即 name 和 id;
2、从索引 city 找到第一个满足 city='杭州’条件的主键 id,也就是图中的 ID_X;
3、到主键 id 索引取出整行,取 name、id 这两个字段,存入 sort_buffer 中;
4、从索引 city 取下一个记录的主键 id;
5、重复步骤 3、4 直到不满足 city='杭州’条件为止,也就是图中的 ID_Y;
6、对 sort_buffer 中的数据按照字段 name 进行排序;
7、遍历排序结果,取前 1000 行,并按照 id 的值回到原表中取出 city、name 和 age 三个字段返回给客户端。
执行案例分析
rand() 执行
select word from words order by rand() limit 3; 表数据有10000行 SQL是从20000行记录中随机获取3条记录返回。
分析: 这里查询的字段只有一个,所以使用全字段查询。 加上记录数过多,但是单条记录的字段长度不长,所以会使用 sort_buffer + 内存临时表。所以总结来看这条语句会使用 全字段查询 + sort_buffer + 内存临时表 来排序。
执行过程:
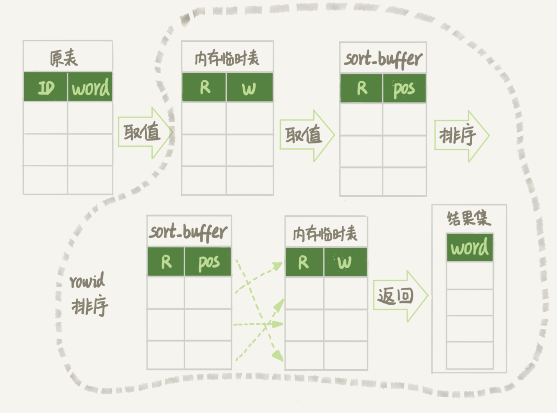
1、从缓冲池依次读取记录,每次读取后都调用 rand() 函数生成一个 0-1 的数存入内存临时表,W 是 word 值,R 是 rand() 生成的随机数。到这扫描了 10000 行。
2、初始化 sort_buffer,从内存临时表中将 rowid(这张表自动生成的) 以及 排序数据 R 存入 sort_buffer。到这因为要遍历内存临时表所以又扫描了 10000 行。
3、在 sort_buffer 中根据 R 排好序,然后选择前三个记录的 rowid 逐条去内存临时表中查到 word 值返回。到这因为取了三个数据去内存临时表去查找所以又扫描了 3 行。总共 20003 行。
rand() 优化
通过上面的例子可以看出当要从表中随机获取几条记录使用 rand() 函数是非常消耗资源的,同时触发了 Using temporary 和 Using filesort。并且进行了 20003 行记录的扫描,非常消耗资源。所以我们可以自己去计算一个随机值,避免使用 rand() 函数。
查询随机的一条记录:
1、取得整个表的行数,并记为 C。
2、取得 Y = floor(C * rand())。floor 函数在这里的作用,就是取整数部分。
3、再用 limit Y,1 取得一行。
select count(*) into @C from t;
set @Y = floor(@C * rand());
set @sql = concat("select * from t limit ", @Y, ",1");
prepare stmt from @sql;
execute stmt;
DEALLOCATE prepare stmt;
如果查询多条,只要将第二步执行多次,然后依次执行就可以了。
使用这样的方式就可以避免 MySQL 去使用临时表以及 filesort 排序,提高执行效率。
优化队列排序算法
在 5.6 中对 rand() 排序进行一些优化,在某些情况下,会使用优化队列排序算法。
例如有一个 20000 行记录的表,执行 select word from words order by rand() limit 3;
因为这条语句只取三条记录,对这剩余的 19993 行进行排序比较浪费CPU资源且耗时。所以使用优化队列排序算法。因为查询的字段只有一个,且查询的行数很多,所以还是使用 全字段查询 + sort_buffer + 内存临时表 。
过程:先读取前三行记录并为其分别通过 rand() 函数为其设置一个0-1的随机数,取这三条记录的 rowid、随机数组成一个堆,然后依次设置随机数并与当前堆中的随机数比较。如果这个随机数比堆中某个记录的随机数小,就替换,然后移除,如果没有小的就直接移除,取下一个。最后根据堆中的 rowid 去临时表中读取对应的 word 值返回。
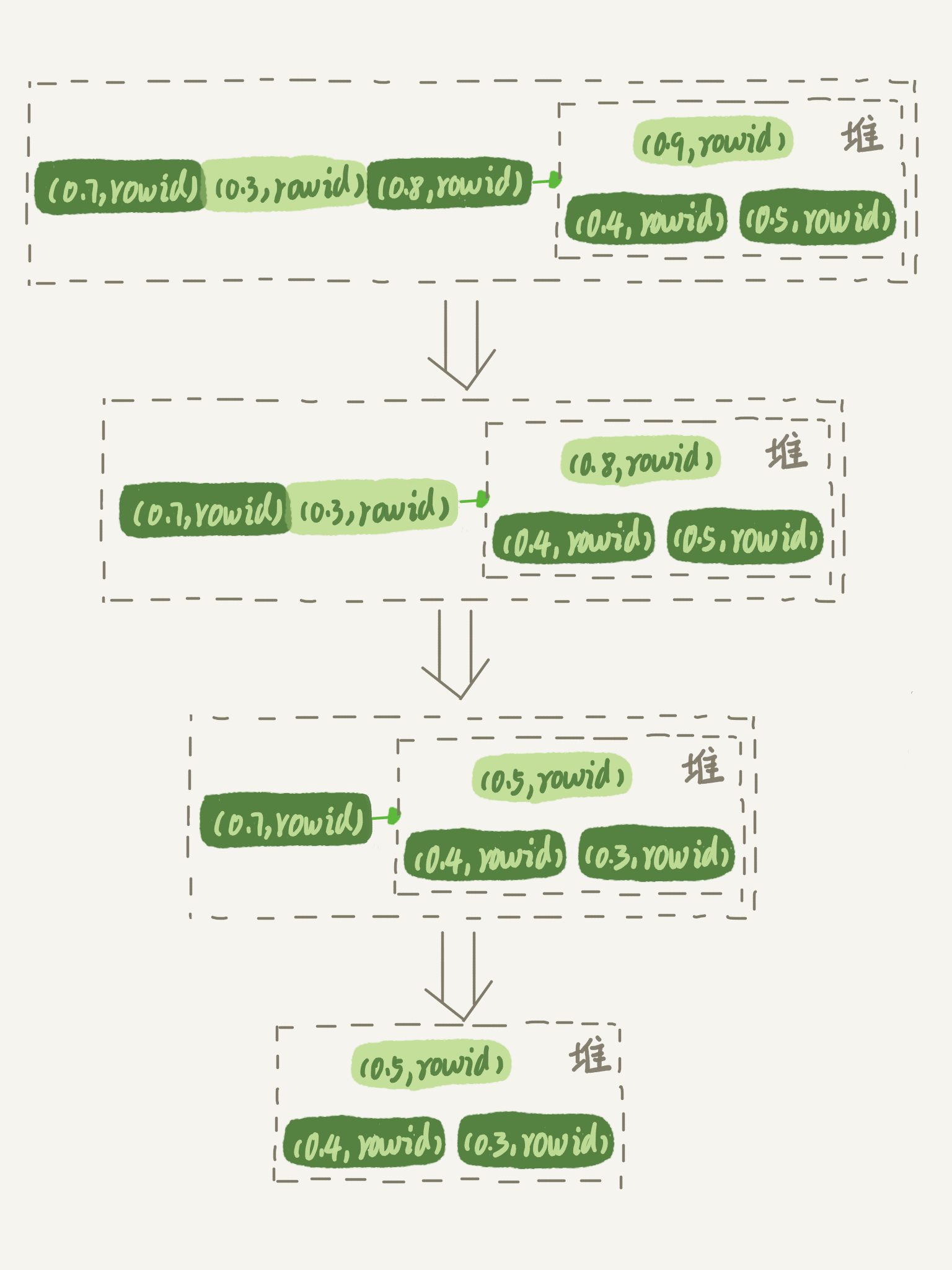
失效场景:因为要拿指定的记录数的排序数据以及rowid去挨个比较,所以如果需要返回的记录数过多,导致所有的字段长度超过了设置的 sort_buffer_size ,那么此算法就会失效。
索引排序案例
问题:有 (city,name) 联合索引,select * from t where city in (“杭州”," 苏州 ") order by name limit 100; 这个 SQL 语句是否需要排序?有什么方案可以避免排序?
答案:需要排序。因为city 的条件有两个,总体上来看就是以 city优先进行排序的。可以优化成下面三步:
1、执行 select * from t where city=“杭州” order by name limit 100; 这个语句是不需要排序的,客户端用一个长度为 100 的内存数组 A 保存结果。
2、执行 select * from t where city=“苏州” order by name limit 100; 用相同的方法,假设结果被存进了内存数组 B。
3、现在 A 和 B 是两个有序数组,然后你可以用归并排序的思想,得到 name 最小的前 100 值,就是我们需要的结果了。
如果将 " limit 100" 改成 " limit 10000,100 "。可以优化成下面三步:
1、select id,name from t where city="杭州" order by name limit 10100;
2、select id,name from t where city="苏州" order by name limit 10100。
3、用归并排序的方法取得按 name 顺序第 10001~10100 的 name、id 的值,然后拿着这 100 个 id 到数据库中去查出所有记录。
优化总结
优化总体上就是围绕了 “尽量不使用额外排序,避免使用临时表”。
1、尽量使用索引完成排序,如果该查询语句执行的频率比较高,可以为其创建一个联合索引。而如果使用的频率很低,那么就不需要去创建,因为索引的维护需要成本。
2、如果需要额外去排序,那么可以适当调整 sort_buffer_size(sort_buffer) 和 tmp_table_size(内存临时表) ,使排序只在内存中执行。
3、如果 sort_buffer 空间设置足够大,也可以适当调整 max_length_for_sort_data 的值,使用全字段排序。
MySQL中的排序的更多相关文章
- 【转】Mysql中的排序规则utf8_unicode_ci、utf8_general_ci的区别总结
Mysql中utf8_general_ci与utf8_unicode_ci有什么区别呢?在编程语言中,通常用unicode对中文字符做处理,防止出现乱码,那么在MySQL里,为什么大家都使用utf8_ ...
- Mysql中的排序规则utf8_unicode_ci、utf8_general_ci的区别总结
Mysql中utf8_general_ci与utf8_unicode_ci有什么区别呢?在编程语言中,通常用unicode对中文字符做处理,防止出现乱码,那么在MySQL里,为什么大家都使用utf8_ ...
- Mysql中的排序规则utf8_unicode_ci、utf8_general_ci总结
Mysql中utf8_general_ci与utf8_unicode_ci有什么区别呢?在编程语言中,通常用unicode对中文字符做处理,防止出现乱码,那么在MySQL里,为什么大家都使用utf8_ ...
- MySQL中的排序(ORDER BY)
当使用 SELECT FROM 时,如果不排 序,数据一般将以它在底层表中出现的顺序显示.这可以是数据最初添加到表中的顺序.但是,如果数据后来进行过更新或删除,则此顺 序将会受到MySQL重用回收存储 ...
- Mysql中的排序规则utf8_unicode_ci、utf8_general_ci的区别
utf8_unicode_ci和utf8_general_ci对中.英文来说没有实质的差别.utf8_general_ci 校对速度快,但准确度稍差.utf8_unicode_ci 准确度高,但校对速 ...
- Mysql中的排序查询
进阶3:排序查询 语法: select 查询列表 from 表 [where 筛选条件]order by 排序列表 [asc 升序 | desc降序] 例子 查询员工信息,要求工资从高到低 SELEC ...
- MySQL中自定义排序
在开发时候,我们经常使用的是默认的排序规则,但在某些特殊情况下,通过指定顺序来进行排序 -- fileld自定义排序时,应该是非主键的,否则主键是无效 SELECT * FROM customer W ...
- Mysql中各种与字符编码集(character_set)有关的变量含义
mysql涉及到各种字符集,在此做一个总结. 字符集的设置是通过环境变量来设置的,环境变量和linux中的环境变量是一个意思.mysql的环境变量分为两种:session和global.session ...
- MySQL 中的临时表
在使用 explain 解析一个 sql 时,有时我们会发现在 extra 列上显示 using temporary ,这表示这条语句用到了临时表,那么临时表究竟是什么?它又会对 sql 的性能产生什 ...
随机推荐
- 团队作业第三次 —— UML设计
这个作业要求在哪里 https://edu.cnblogs.com/campus/fzzcxy/2018SE2/homework/11366 这个作业的目标 <团队一起设计UML图> 团队 ...
- Kubernetes Ingress-nginx使用
目录 简介 1. 部署Ingress-Controller 2. 使用Ingress规则 2.1 Ingress地址重写 2.2 配置HTTPS 2.3 黑白名单配置 2.4 匹配请求头 2.5 速率 ...
- spring-boot-starter
Spring Boot Starter 是在 SpringBoot 组件中被提出来的一种概念,stackoverflow 上面已经有人概括了这个 starter 是什么东西,想看完整的回答戳 这里. ...
- 利用Python特殊变量__dict__快速实现__repr__的一种方法
在<第8.15节 Python重写自定义类的__repr__方法>.<Python中repr(变量)和str(变量)的返回值有什么区别和联系>.<第8.13节 Pytho ...
- 第二十八章、containers容器类部件QStackedWidget堆叠窗口部件详解
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 一.概述 StackedWidget堆叠窗口部件为一系列窗口部件的堆叠,对应类为QStackedWi ...
- PyQt(Python+Qt)学习随笔:QListView的viewMode属性
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 QListView的viewMode属性用于控制QListView的视图模式,该属性类型为枚举类型Q ...
- JAVA课堂作业(2019.10.21)
1. 代码: package class20191021; class Grandparent { public Grandparent() { System.out.println("Gr ...
- uni-app中使用sass
uni-app在创建时,工程目录下会有个uni.scss文件,我们可以直接在里面定制化scss变量. 全局scss中的坑: 1.如果要引用全局外部scss文件,可以考虑在uni.scss这个系统全局s ...
- 【PY从0到1】第一节 安装与界面介绍
本系列是介绍如何用Python进行股票量化交易的课程. 课程内容以记录Python零基础学员从最简单的Python下载及安装开始,到最后能熟练运用Python进行量化交易的专业人员的成长历程.旨在打造 ...
- Android各版本迭代改动与适配集合
前言 今天分享的面试题是: Android在版本迭代中,总会进行很多改动,那么你熟知各版本都改动了什么内容?又要怎么适配呢? Android4.4 发布ART虚拟机,提供选项可以开启. HttpURL ...