Flink Native Kubernetes实战
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
回顾Flink Kubernetes
Flink Kubernetes与Flink Native Kubernetes是不同的概览,先回顾一下Flink Kubernetes:
- 如下图,从1.2版本到目前最新的1.10,Flink官方都给出了Kubernetes上部署和运行Flink的方案:
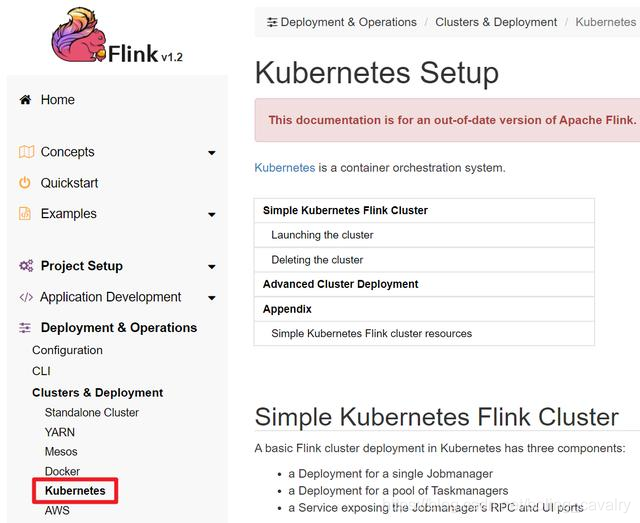
- 在kubernetes上有两种方式运行flink:session cluster和job cluster,其中session cluster是一套服务可以提交多个任务,而job cluster则是一套服务只对应一个任务;
- 下图是典型的session cluster部署操作,可见关键是准备好service、deployment等资源的yaml文件,再用kubectl命令创建:

关于Flink Native Kubernetes
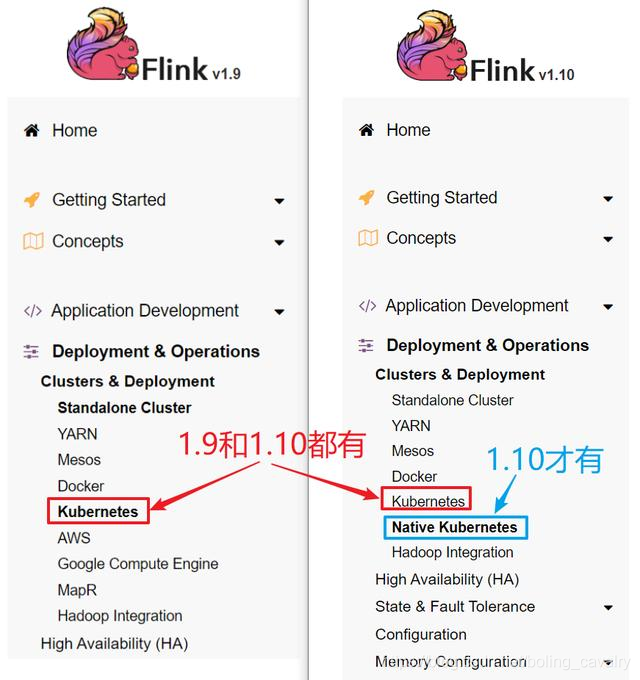
- 先对比官方的1.9和1.10版本文档,如下图和红框和蓝框所示,可见Flink Native Kubernetes是1.10版本才有的新功能:
- 看看Native Kubernetes是如何运行的,如下图,创建session cluster的命令来自Flink安装包:

- 更有趣的是,提交任务的命令也来自Flink安装包,就是我们平时提交任务用到flink run命令,如下图:

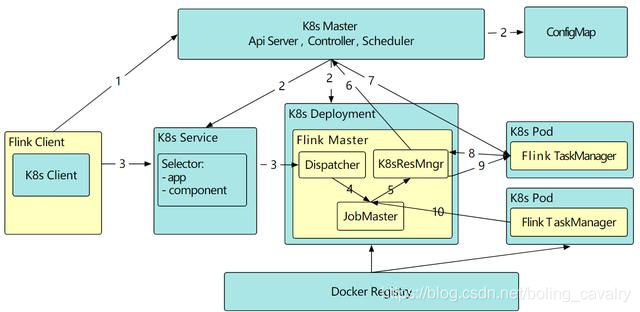
- 结合官方给出的提交和部署流程图就更清晰了:kubernetes上部署了Flink Master,由Flink Client来提交session cluster和job的请求:
Flink Kubernetes和Flink Native Kubernetes的区别
至此,可以小结Flink Kubernetes和Flink Native Kubernetes的区别:
- Flink Kubernetes自1.2版本首次出现,Flink Native Kubernetes自1.10版本首次出现;
- Flink Kubernetes是把JobManager和TaskManager等进程放入容器,在kubernetes管理和运行,这和我们把java应用做成docker镜像再在kubernetes运行是一个道理,都是用kubectl在kubernetes上操作;
- Flink Native Kubernetes是在Flink安装包中有个工具,此工具可以向kubernetes的Api Server发送请求,例如创建Flink Master,并且可以和Flink Master通讯,用于提交任务,我们只要用好Flink安装包中的工具即可,无需在kubernetes上执行kubectl操作;
Flink Native Kubernetes在Flink-1.10版本中的不足之处
- Flink Native Kubernetes只是Beta版,属于实验性质(官方原话:still experimental),请勿用于生产环境!
- 只支持session cluster模式(一个常驻session执行多个任务),还不支持Job clusters模式(一个任务对应一个session)
尽管还没有进入Release阶段,但这种操作模式对不熟悉kubernetes的开发者来说还是很友好的,接下来通过实战来体验吧;
官方要求
为了体验Native Kubernetes,flink官方提出了下列前提条件:
- kubernetes版本不低于1.9
- kubernetes环境的DNS是正常的
- KubeConfig文件,并且这个文件是有权对pod和service资源做增删改查的(kubectl命令有权对pod和service做操作,也是因为它使用了对应的KubeConfig文件),这个文件一般在kubernetes环境上,全路径:~/.kube/config
- pod执行时候的身份是service account,这个service account已经通过RBAC赋予了pod的增加和删除权限;
前面两点需要您自己保证已达到要求,第三和第四点现在先不必关心,后面有详细的步骤来完成;
实战环境信息
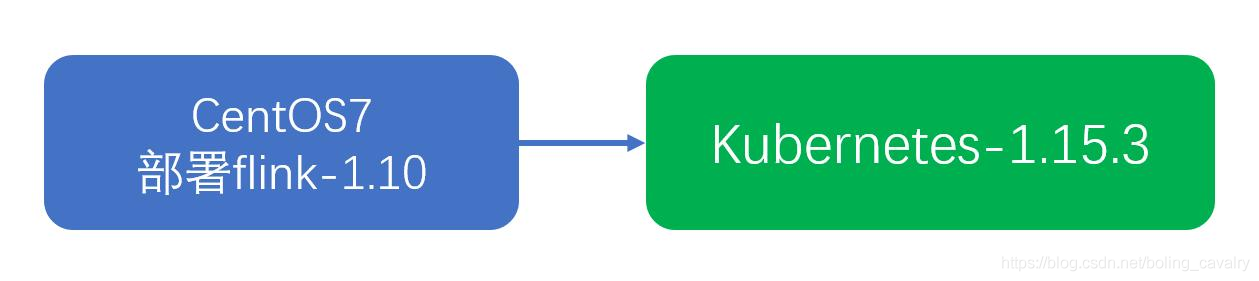
本次实战的环境如下图所示,一套kubernetes环境(版本是1.15.3),另外还有一台CentOS7电脑,上面已部署了flink-1.10(这里的部署是说把安装包解压,不启动任何服务):
准备完毕,开始实战了~
实战内容简介
本次实战是在kubernetes环境创建一个session cluster,然后提交任务到这个sessionc cluster运行,与官方教程不同的是本次实战使用自定义namespace和service account,毕竟生产环境一般是不允许使用default作为namespace和service account的;
实战
- 在CetnOS7电脑上操作时使用的是root账号;
- 在kubernetes的节点上,确保有权执行kubectl命令对pod和service进行增删改查,将文件~/.kube/config复制到CentOS7电脑的~/.kube/目录下;
- 在kubernetes的节点上,执行以下命令创建名为flink-session-cluster的namespace:
kubectl create namespace flink-session-cluster
- 执行以下命令创建名为flink的serviceaccount:
kubectl create serviceaccount flink -n flink-session-cluster
- 执行以下命令做serviceaccount和角色的绑定:
kubectl create clusterrolebinding flink-role-binding-flink \
--clusterrole=edit \
--serviceaccount=flink-session-cluster:flink
- SSH登录部署了flink的CentOS7电脑,在flink目录下执行以下命令,即可创建名为session001的session cluster,其中-Dkubernetes.namespace参数指定了namespace,另外还指定了一个TaskManager实例使用一个CPU资源、4G内存、内含6个slot:
./bin/kubernetes-session.sh \
-Dkubernetes.namespace=flink-session-cluster \
-Dkubernetes.jobmanager.service-account=flink \
-Dkubernetes.cluster-id=session001 \
-Dtaskmanager.memory.process.size=8192m \
-Dkubernetes.taskmanager.cpu=1 \
-Dtaskmanager.numberOfTaskSlots=4 \
-Dresourcemanager.taskmanager-timeout=3600000
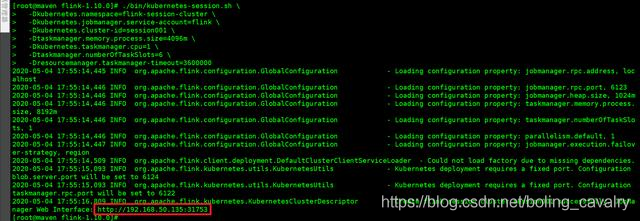
- 如下图,控制台提示创建成功,并且红框中提示了flink web UI的访问地址是http://192.168.50.135:31753:
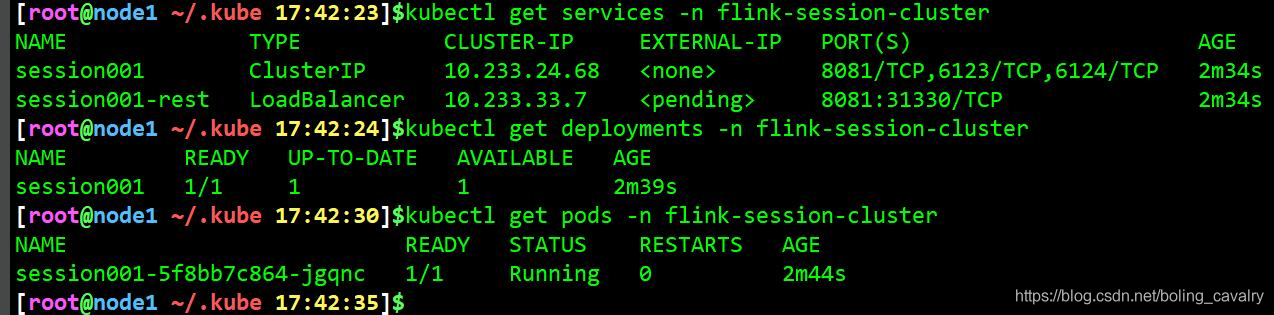
- 下载镜像和启动容器需要一定的时间,可以用kubectl get和kubectl describe命令观察对应的deployment和pod的状态:
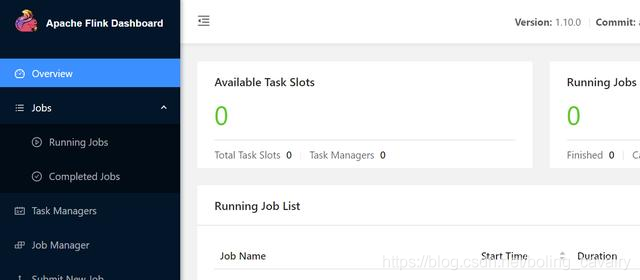
9. pod启动成功后访问flink web,如下图,此时还没有创建TaskManager,因此Slot为零:
10. 回到CentOS7电脑,在flink目录下执行以下命令,将官方自带的WindowJoin任务提交到session cluster:
./bin/flink run -d \
-e kubernetes-session \
-Dkubernetes.namespace=flink-session-cluster \
-Dkubernetes.cluster-id=session001 \
examples/streaming/WindowJoin.jar
- 控制台提示提交任务成功:

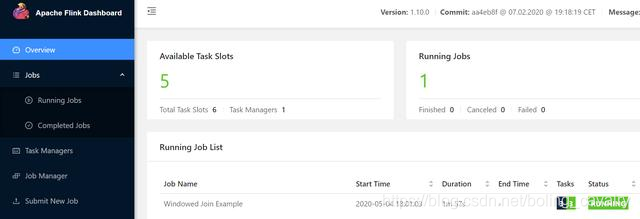
- 页面上也会同步显示增加了一个TaskManager,对应6个slot,已经用掉了一个:
- 再连续提交5次相同的任务,将此TaskManager的slot用光:
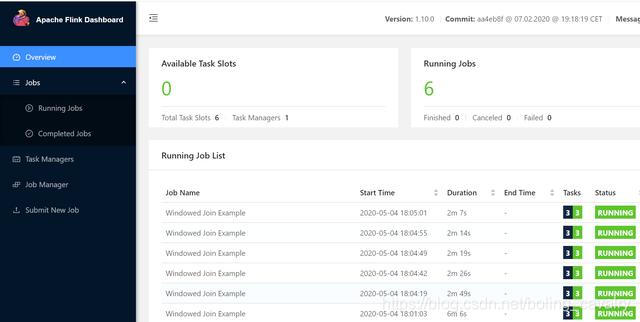
- 这时候再提交一次任务,按理来说应该增加一个TaskManager,可是页面如下图所示,TaskManager数量还是1,并没有增加,并且红框中显示新增的任务并没有正常运行起来:
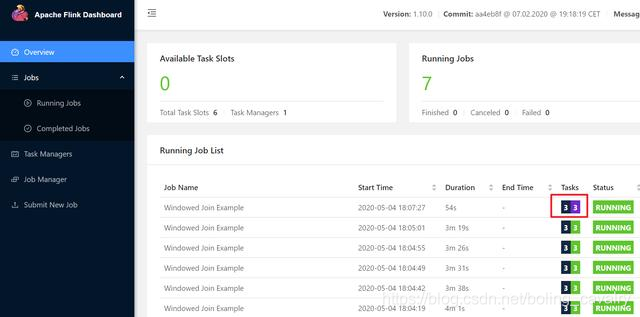
15. 在kubernetes环境查看pod情况,如下图红框所示,有个新建的pod状态是Pending,看来这就是第七个任务不能执行就是因为这个新建的pod无法正常工作导致的:

16. 再看看这个namespace的事件通知,如下图红框所示,名为session001-taskmanager-1-2的pod有一条通知信息:由于CPU资源不足导致pod创建失败:

17. 穷到没钱配置kubernetes环境,连一核CPU都凑不齐:

18. 一时半会儿也找不出多余的CPU资源,唯一能做的就是降低TaskManager的CPU要求,刚才配置的是一个TaskManager使用一核CPU,我打算降低一半,即0.5核,这样就够两个TaskManager用了;
19. 您可能会疑惑:怎么会有0.5个CPU这样的配置?这个和kubernetes的资源限制有关,kubernetes对pod的CPU限制粒度是千分之一个CPU,也是就是在kubernetes中,配置1000单位的CPU表示使用1核,我们配置0.5核,不过是配置了500单位而已(所以我还可以更穷....)
20. 接下来的操作是先停掉当前的session cluster,再重新创建一个,创建的时候参数-Dkubernetes.taskmanager.cpu的值从1改为0.5
21. 在CentOS7电脑上执行以下命令,将session cluster停掉,释放所有资源:
echo 'stop' | \
./bin/kubernetes-session.sh \
-Dkubernetes.namespace=flink-session-cluster \
-Dkubernetes.cluster-id=session001 \
-Dexecution.attached=true
- 控制台提示操作成功:

- 稍等一分钟左右,再去查看pod,发现已经全部不见了:

- 在CentOS7电脑的flink目录下,执行以下命令,和之前相比,唯一变化就是-Dkubernetes.taskmanager.cpu参数的值:
./bin/kubernetes-session.sh \
-Dkubernetes.namespace=flink-session-cluster \
-Dkubernetes.jobmanager.service-account=flink \
-Dkubernetes.cluster-id=session001 \
-Dtaskmanager.memory.process.size=4096m \
-Dkubernetes.taskmanager.cpu=0.5 \
-Dtaskmanager.numberOfTaskSlots=6 \
-Dresourcemanager.taskmanager-timeout=3600000
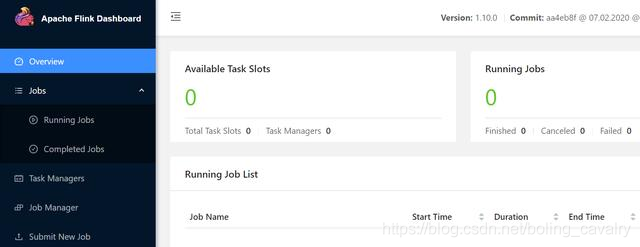
- 从控制台提示得到新的flink web UI端口值,再访问网页,发现启动成功了:
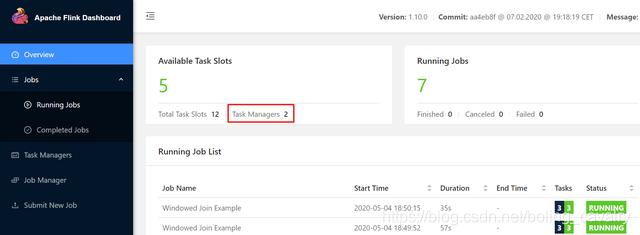
- 像之前那样提交任务,连续提交7个,这一次很顺利,在提交了第七个任务后,新的TaskManager创建成功,7个任务都成功执行了:
- 用kubectl describe pod命令查看TaskManager的pod,如下图红框所示,可见该pod的CPU用量是500单位,符合之前的推测:
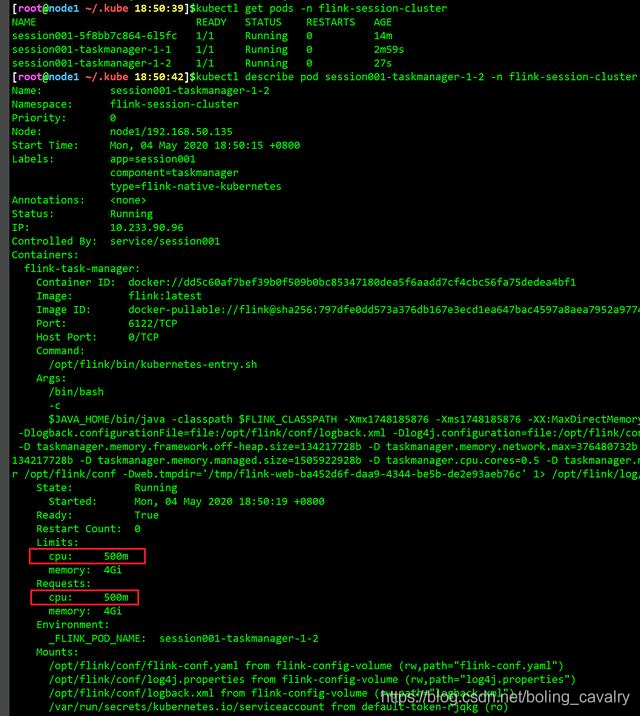
这里再提醒一下,降低CPU用量,意味着该pod中的进程获取的CPU执行时间被降低,会导致任务执行变慢,所以这种方法不可取,正确的思路是确保硬件资源能满足业务需求(像我这样穷到一核CPU都凑不齐的情况还是不多的....)
清理资源
如果已完成Flink Native Kubernetes体验,想彻底清理掉前面的所有资源,请按照以下步骤操作:
- 在web页面点击Cancel Job停止正在运行的任务,如下图红框:

- 在CentOS7电脑上停止session cluster:
echo 'stop' | \
./bin/kubernetes-session.sh \
-Dkubernetes.namespace=flink-session-cluster \
-Dkubernetes.cluster-id=session001 \
-Dexecution.attached=true
- 在kubernetes节点清理service、clusterrolebinding、serviceaccount、namespace:
kubectl delete service session001 -n flink-session-cluster
kubectl delete clusterrolebinding flink-role-binding-flink
kubectl delete serviceaccount flink -n flink-session-cluster
kubectl delete namespace flink-session-cluster
- 所有cluster session相关的ConfigMap、Service、Deployment、Pod等资源,都通过kubernetes的ownerReferences配置与service关联,因此一旦service被删除,其他资源被被自动清理掉,无需处理;
至此,Flink Native Kubernetes相关的实战就完成了,如果您也在关注这个技术,希望本文能给您一些参考
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
Flink Native Kubernetes实战的更多相关文章
- Kubernetes实战总结 - 阿里云ECS自建K8S集群
一.概述 详情参考阿里云说明:https://help.aliyun.com/document_detail/98886.html?spm=a2c4g.11186623.6.1078.323b1c9b ...
- Flink的sink实战之一:初探
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink的sink实战之二:kafka
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink的sink实战之三:cassandra3
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink的sink实战之四:自定义
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink处理函数实战之一:深入了解ProcessFunction的状态(Flink-1.10)
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink处理函数实战之二:ProcessFunction类
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink处理函数实战之三:KeyedProcessFunction类
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink处理函数实战之四:窗口处理
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
随机推荐
- day20 Pyhton学习 面向对象-成员
一.类的成员 class 类名: # 方法 def __init__(self, 参数1, 参数2....): # 属性变量 self.属性1 = 参数1 self.属性2 = 参数2 .... # ...
- 0基础如何更快速入门Linux系统?学完Linux有哪些就业方向?
Linux系统是使用Linux内核及开源自由软件组成的一套操作系统,是一种类UNIX系统,其内核在1991年10月5日由林纳斯·托瓦兹首次发布. 它的主要特性:Linux文件一切皆文件.完全开源免费. ...
- 纯CSS+HTML自定义checkbox效果[转]
<!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <m ...
- 第十五章 nginx七层负载均衡
一.Nginx负载均衡 1.为什么做负载均衡 当我们的Web服务器直接面向用户,往往要承载大量并发请求,单台服务器难以负荷,我使用多台Web服务器组成集群,前端使用Nginx负载均衡,将请求分散的打到 ...
- MySql中varchar(10)和varchar(100)的区别
背景 许多使用MySQL的同学都会使用到varchar这个数据类型.初学者刚开始学习varchar时,一定记得varchar是个变长的类型这个知识点,所以很多初学者在设计表时,就会把varchar(X ...
- spring-boot-route(二十二)实现邮件发送功能
在项目开发中,除了需要短信验证外,有时候为了节省 短信费也会使用邮件发送.在Spring项目中发送邮件需要封装复杂的消息体,不太方便.而在Spring Boot项目中发送邮件就太简单了,下面一起来看看 ...
- codevs1298, hdu1392 (凸包模板)
题意: 求凸包周长. 总结: 测试模板. 代码: #include <iostream> #include <cstdio> #include <cstring> ...
- node的function函数和路由代码的小例子
1.node事件循环 事件: const events=require("events"); emt=new events.EventEmitter(); function eve ...
- H5页面字体设置
H5页面不支持 MicrosoftYaHei(微软雅黑)别傻傻的设置微软雅黑字体了 如果一定要微软雅黑操作如下 @font-face 定义为微软雅黑字体并存放到 web 服务器上,在需要使用时被自动下 ...
- 在Linux系统中安装Chrome浏览器
前言:作为一个Web开发人员,经常与我们相伴的必然少不了浏览器,而Google旗下的chrome浏览器更是凭借着出色的性能.简洁的界面被广大开发者所喜爱,今天分享下如何在linux系统下安装chrom ...