基于Python开发数据宽表实例
搭建宽表作用,就是为了让业务部门的数据分析人员,在日常工作可以直接提取所需指标,快速做出对应专题的数据分析。在实际工作中,数据量及数据源繁多,如果每个数据分析人员都从计算加工到出报告,除了工作效率巨慢也会导致服务器资源紧张。因此建设数据集市层,包含了该宽表层并在非工作时间做自动生成。
本文引用CDNow网站的一份用户购买CD明细数据,梳理业务需求,搭建一套数据宽表。
该CD数据包括用户ID,购买日期,购买数量,购买金额四个字段(此项目中用userid,datatime,products,amounts字段来表示)
业务逻辑参考文章:zhuanlan.zhihu.com/p/109767465
指标维度整理如下:
(实际业务场景中,由于获取的数据维度非常多,基础指标及衍生指标的加工最后有几千个指标都很正常,本次该数据集主要用于提出思路。另外,基于机器学习算法自动生成的衍生指标不在本次文章讨论范围,本次宽表指标主要是从业务角度出发,开发具备可解释性指标)
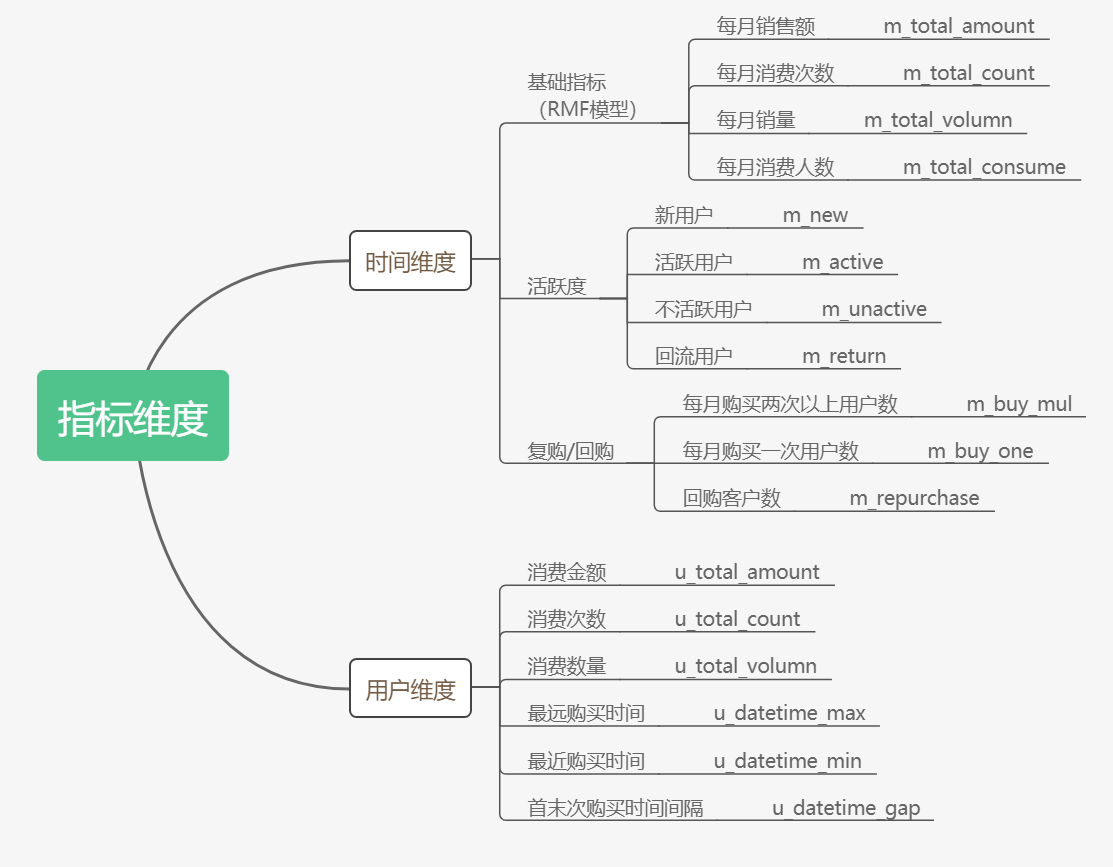
ps:指标名、统计口径、数据类型、小数位的统一非常重要
数据加载
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime
%matplotlib inline
df = pd.read_table('CDNOW_master.txt',delim_whitespace=True,header=None,names=['userid','datetime','products','amounts'])
df['datetime'] = pd.to_datetime(df['datetime'],format='%Y%m%d')
#加入月维度
df['month'] = df['datetime'].values.astype('datetime64[M]')
df.head()
一、时间维度
①基础指标:销售额/销量/消费次数/消费人数,可用以支撑RMF模型
#每月的总销售额/销量/消费次数
df_m_total_1 = df.pivot_table(index='month',values=['amounts','userid','products',]
,aggfunc={'amounts':'sum','userid':'count','products':'sum'})
#每月的消费人数
df_m_total_consume = pd.DataFrame(df.groupby('month')['userid'].nunique())
#合并
df_m_total = pd.merge(df_m_total_1, df_m_total_consume, on=['month'])
#修改列名
df_m_total.columns = ['m_total_amount','m_total_count','m_total_volumn','m_total_consume']
②活跃度指标:新用户/活跃用户/不活跃用户/回流用户
#每个用户每月的消费次数
pivoted_counts = df.pivot_table(index='userid',columns='month',values='datetime',aggfunc='count').fillna(0)
#1代表本月消费,0代表未消费
df_purchase = pivoted_counts.applymap(lambda x:1 if x>0 else 0)
col = ['1997-01-01', '1997-02-01', '1997-03-01', '1997-04-01',
'1997-05-01', '1997-06-01', '1997-07-01', '1997-08-01',
'1997-09-01', '1997-10-01', '1997-11-01', '1997-12-01',
'1998-01-01', '1998-02-01', '1998-03-01', '1998-04-01',
'1998-05-01', '1998-06-01']
def active_status(data): #data是df_purchase的一行
status=[]
for i in range(18): #一共有18个月,判断每一个月的消费情况,也可以使用len(df_purchase.columns)
#若本月没有消费
if data[i]==0:
if len(status)>0:#之前有记录
if status[i-1]=='m_unreg': #一直没有注册,看作未注册用户
status.append('m_unreg') #未注册用户
else:
status.append('m_unactive') #这个月没消费,之前消费过
else:#之前没有记录
status.append('m_unreg') #第一个月没有消费,未注册
#若本月消费
else:
if len(status)==0:#之前没有记录
status.append('m_new') #第一次消费
else:#之前有记录
if status[i-1]=='m_unactive':
status.append('m_return') #前几个月不活跃,现在又消费了,回流
elif status[i-1]=='m_unreg':
status.append('m_new') #判断第一次消费
else:
status.append('m_active') #一直在消费
return pd.Series(status,index = col)
pivoted_status = df_purchase.apply(active_status,axis = 1)
#用NaN替代m_unreg,以便后续计算不包含这些数据,未注册不考虑
purchase_stats_ct=pivoted_status.replace({'m_unreg':np.NaN}).apply(lambda x:x.value_counts())
#分层图
purchase_stats_ct.fillna(0).T.plot.area()
#每月活跃情况数量
df_active_level = purchase_stats_ct.T.fillna(0)
#每月活跃情况数量占比
df_active_level_por = pd.DataFrame(purchase_stats_ct.fillna(0).T.apply(lambda x:x/x.sum(),axis = 1))
③复购类指标:每月购买两次以上的客户数/购买一次的客户数
#购买两次以上标为1,一次为0,无购买记录为空
user_df2=pivoted_counts.applymap(lambda x : 1 if x > 1 else np.NaN if x == 0 else 0)
#汇总转置
user_df3 = user_df2.apply(lambda x:x.value_counts()).T
#修改列名
user_df3.columns=['m_buy_one','m_buy_mul']
④回购类指标:回购人数
#某一个时间窗口内消费的用户,在下一个时间窗口仍旧消费的占比。比如,
#我1月消费用户1000,他们中有400个2月依然消费,回购率是40%。
def purchase_return(data):
status=[]
for i in range(17):
if data[i]==1:
if data[i+1]==1:
status.append(1)
if data[i+1]==0:
status.append(0)
else:
status.append(np.nan)
status.append(np.nan) #定义最后一个月的数据
return pd.Series(status,index = col)
pivoted_purchase_return= df_purchase.apply(purchase_return,axis=1)
#占比图
(pivoted_purchase_return.sum() / pivoted_purchase_return.count()).plot(figsize=(10,4))
#复购人数加总
pivoted_purchase_return2 = pd.DataFrame(pivoted_purchase_return.apply(lambda x:x.sum()))
#修改列名
pivoted_purchase_return2.columns=['m_repurchase']
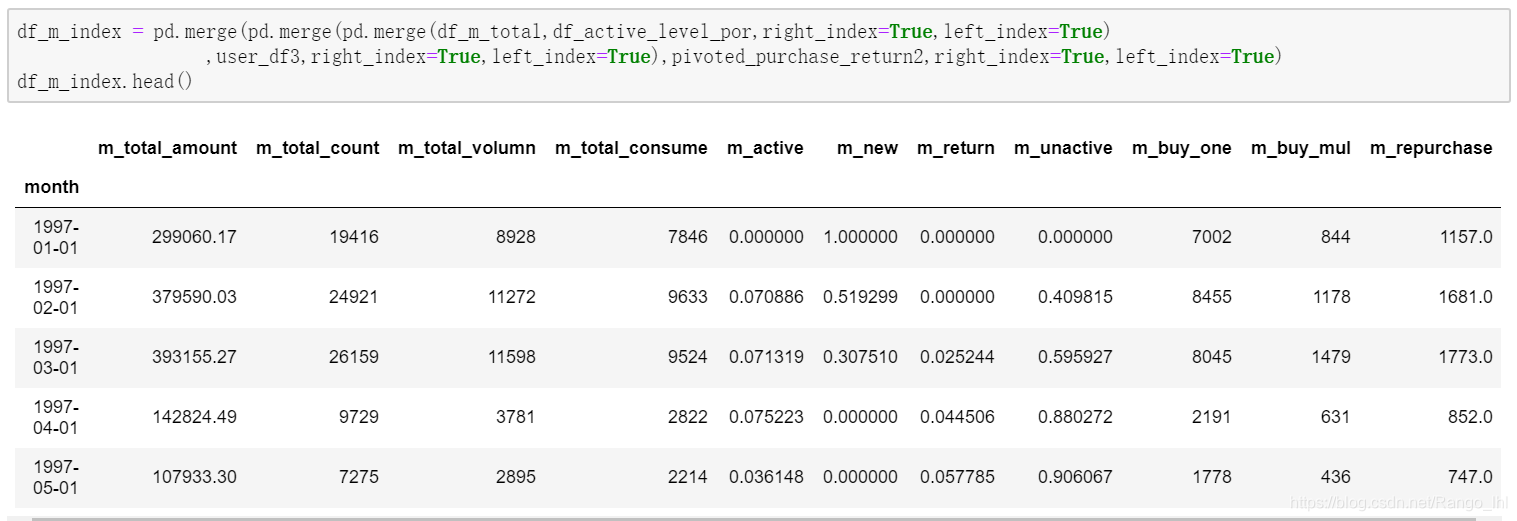
⑤指标合并
df_m_index = pd.merge(pd.merge(pd.merge(df_m_total,df_active_level_por,right_index=True,left_index=True)
,user_df3,right_index=True,left_index=True),pivoted_purchase_return2,right_index=True,left_index=True)
df_m_index.head()
二、用户维度
消费总额/消费次数/消费量/首次消费时间/最近一次消费时间/消费间隔
df_user = df.pivot_table(index='userid',values=['datetime','products','amounts']
,aggfunc={'datetime':['max','min'],'products':['sum','count'],'amounts':'sum'})
df_user['gap'] = (df_user['datetime']['max']-df_user['datetime']['min'])/np.timedelta64(1,'D')
df_user.columns=['u_total_amount','u_datetime_max','u_datetime_min','u_total_count','u_total_volumn','u_datetime_gap']
df_user.head()

学习交流,有任何问题还请随时评论指出交流。
基于Python开发数据宽表实例的更多相关文章
- TriAquae 是一款由国产的基于Python开发的开源批量部署管理工具
怀着鸡动的心情跟大家介绍一款国产开源运维软件TriAquae,轻松帮你搞定大部分运维工作!TriAquae 是一款由国产的基于Python开发的开源批量部署管理工具,可以允许用户通过一台控制端管理上千 ...
- Sublime Text3介绍和插件安装——基于Python开发
Subime编辑器是一款轻量级的代码编辑器,是收费的,但是可以无限期使用.官网下载地址:https://www.sublimetext.com. Sublime Text3支持语言开发种类多样,几乎可 ...
- scapy - 基于python的数据包操作库
简介 地址:https://github.com/secdev/scapy scapy是一个基于python的交互式数据包操作程序和库. 它能够伪造或者解码多种协议的数据包,通过使用pcap文件对他们 ...
- Django开发密码管理表实例【附源码】
文章及代码比较基础,适合初.中级人员,高手略过 阅读此篇文章你可以: 获取一个Django实现增删改查的案例源码 了解数据加密的使用场景和方法以及如何在Python3中使用 背景介绍 DBA需要维护一 ...
- 基于python开发的股市行情看板
个人博客: https://mypython.me 近期股市又骚动起来,回忆起昔日炒股经历,历历在目,悲惨经历让人黯然神伤,去年共投入4000元入市,最后仅剩1000多,无奈闭关修炼,忘记股市,全身心 ...
- python开发mysql:单表查询&多表查询
一 单表查询,以下是表内容 一 having 过滤 1.1 having和where select * from emp where id > 15; 解析过程;from > where ...
- python开发基础04-列表、元组、字典操作练习
练习1: # l1 = [11,22,33]# l2 = [22,33,44]# a. 获取内容相同的元素列表# b. 获取 l1 中有, l2 中没有的元素列表# c. 获取 l2 中有, l1 中 ...
- 基于python的flask的应用实例注意事项
1.所有的html文件均保存在templates文件夹中 2.运行网页时python manage.py runserver
- Python开发基础-Day3-列表、元组和字典
列表 列表定义:[]内以逗号分隔,按照索引,存放各种数据类型,每个位置代表一个元素 特性: 1.可存放多个值 2.可修改指定索引位置对应的值,可变 3.按照从左到右的顺序定义列表元素,下标从0开始顺序 ...
随机推荐
- nginx转发上传图片接口图片的时候,报错413
我这边有一个接口是上传图片,使用nginx进行代理,上传大一点的图片,直接调用我的接口不会报错,但是调用nginx上传图片就会报错"413 Request Entity Too Large& ...
- 精尽Spring MVC源码分析 - 寻找遗失的 web.xml
该系列文档是本人在学习 Spring MVC 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释 Spring MVC 源码分析 GitHub 地址 进行阅读 Spring 版本:5.2. ...
- hive实例的使用
一.hive用本地文件进行词频统计 1.准备本地txt文件 2.启动hadoop,启动hive 3.创建数据库,创建文本表 4.映射本地文件的数据到文本 5.hql语句进行词频统计交将结果保存到结果表 ...
- 1、MyCat入门
1.Mycat简介 [1].Mycat是什么 Mycat 是数据库中间件 [2].why使用Mycat ①.Java与数据库紧耦合 ②.高访问量高并发对数据库的压力 ③.读写请求数据不一致 [3].数 ...
- vue 图片优化
https://developer.aliyun.com/mirror/npm/package/image-conversionnpm i image-conversion --save # or y ...
- Elasticsearch 新机型发布,性能提升30%
跨年迎双节,2020 年最后一次囤货的机会来啦! Elasticsearch Service 星星海新机型发布,更高性能,更低价格. 爆款机型限时特惠,帮助您顺畅体验 Elasticsearch 云上 ...
- CDH集群spark-shell执行过程分析
目的 刚入门spark,安装的是CDH的版本,版本号spark-core_2.11-2.4.0-cdh6.2.1,部署了cdh客户端(非集群节点),本文主要以spark-shell为例子,对在cdh客 ...
- 记一次 HBase Master is initializing 问题处理
问题 hbase shell中建立建表出错 分析 org.apache.hadoop.hbase.PleaseHoldException: Master is initializing代表Master ...
- Shell变量、函数
上篇文章初步认识了一下shell脚本及其简单的案例,下面我们再来讲一下shell的进击部分. 一.变量 1.常用系统变量:($HOME.$SHELL.$PWD.$USER) 2.自定义变量: 2.1. ...
- NO.001- 简说 Java 并发编程史
这篇文章是Java并发编程思想系列的第一篇,主要从理解Java并发编程历史的原因和Java并发演进过程两部分,以极简地回溯并发编程的历史,帮助大家从历史这个角度去了解一门语言一个特性的演进.对历史理解 ...