flume集群日志收集
一、Flume简介
Flume是一个分布式的、高可用的海量日志收集、聚合和传输日志收集系统,支持在日志系统中定制各类数据发送方(如:Kafka,HDFS等),便于收集数据。其核心为agent,agent是一个java进程,运行在日志收集节点。
agent里面包含3个核心组件:source、channel、sink。
source组件是专用于收集日志的,可以处理各种类型各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定义,同时 source组件把数据收集
以后,临时存放在channel中。
channel组件是在agent中专用于临时存储数据的,可以存放在memory、jdbc、file、自定义等。channel中的数据只有在sink发送成功之后才会被删除。
sink组件是用于把数据发送到目的地的组件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、hbase、solr、自定义。
在整个数据传输过程中,流动的是event。事务保证是在event级别。flume可以支持多级flume的agent,支持扇入(fan-in)、扇出(fan-out)。
二、环境准备
1)hadoop集群(楼主用的版本2.7.3,共6个节点,可参考http://www.cnblogs.com/qq503665965/p/6790580.html)
2)flume集群规划:
|
HOST |
作用 |
方式 |
路径 |
|
hadoop01 |
agent |
spooldir |
/home/hadoop/logs |
|
hadoop05 |
collector |
HDFS |
/logs |
|
hadoop06 |
collector |
HDFS |
/logs |
其基本结构官网给出了更加具体的说明,这里楼主就直接copy过来了:
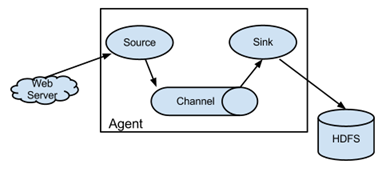
三、集群配置
1)系统环境变量配置
export FLUME_HOME=/home/hadoop/apache-flume-1.7.0-bin
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$FLUME_HOME/bin
记得 source /etc/profile 。
2)flume JDK环境
mv flume-env.sh.templete flume-env.sh
vim flume-env.sh
export JAVA_HOME=/usr/jdk1.7.0_60//增加JDK安装路径即可
3)hadoop01中flume配置
在conf目录增加配置文件 flume-client ,内容为:
#agent1名称
agent1.channels = c1
agent1.sources = r1
agent1.sinks = k1 k2 #sink组名称
agent1.sinkgroups = g1 #set channel
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
agent1.channels.c1.transactionCapacity = 100 agent1.sources.r1.channels = c1
agent1.sources.r1.type = spooldir
#日志源
agent1.sources.r1.spoolDir =/home/hadoop/logs agent1.sources.r1.interceptors = i1 i2
agent1.sources.r1.interceptors.i1.type = static
agent1.sources.r1.interceptors.i1.key = Type
agent1.sources.r1.interceptors.i1.value = LOGIN
agent1.sources.r1.interceptors.i2.type = timestamp # 设置sink1
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
#sink1所在主机
agent1.sinks.k1.hostname = hadoop05
agent1.sinks.k1.port = 52020 #设置sink2
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro
#sink2所在主机
agent1.sinks.k2.hostname = hadoop06
agent1.sinks.k2.port = 52020 #设置sink组包含sink1,sink2
agent1.sinkgroups.g1.sinks = k1 k2 #高可靠性
agent1.sinkgroups.g1.processor.type = failover
#设置优先级
agent1.sinkgroups.g1.processor.priority.k1 = 10
agent1.sinkgroups.g1.processor.priority.k2 = 1
agent1.sinkgroups.g1.processor.maxpenalty = 10000
4)hadoop05配置
#设置 Agent名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1 #设置channlels
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100 # 当前节点信息
a1.sources.r1.type = avro
#绑定主机名
a1.sources.r1.bind = hadoop05
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
a1.sources.r1.interceptors.i1.value = hadoop05
a1.sources.r1.channels = c1 #sink的hdfs地址
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=/logs
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=TEXT
#没1K产生文件
a1.sinks.k1.hdfs.rollInterval=1
a1.sinks.k1.channel=c1
#文件后缀
a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d
5)hadoop06配置
#设置 Agent名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1 #设置channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100 # 当前节点信息
a1.sources.r1.type = avro
#绑定主机名
a1.sources.r1.bind = hadoop06
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
a1.sources.r1.interceptors.i1.value = hadoop06
a1.sources.r1.channels = c1
#设置sink的hdfs地址目录
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=/logs
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=TEXT
a1.sinks.k1.hdfs.rollInterval=1
a1.sinks.k1.channel=c1
a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d
四、启动flume集群
1)启动collector,即hadoop05,hadoop06
flume-ng agent -n a1 -c conf -f flume-server -Dflume.root.logger=DEBUG,console
2)启动agent,即hadoop01
flume-ng agent -n a1 -c conf -f flume-client -Dflume.root.logger=DEBUG,console
agent启动后,hadoop05,hadoop06的控制台可看到如下打印信息:

五、日志收集测试
1)启动zookeeper集群(未搭建zookeeper的同学可以忽略)

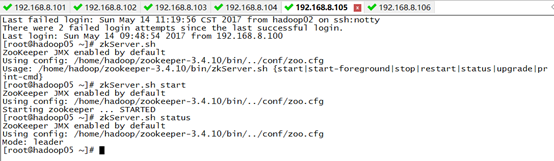
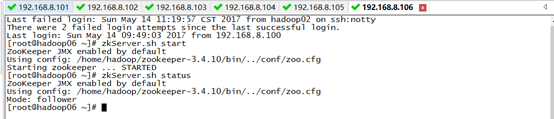
2)启动hdfs start-dfs.sh

3)模拟网站日志,楼主这里随便弄的测试数据
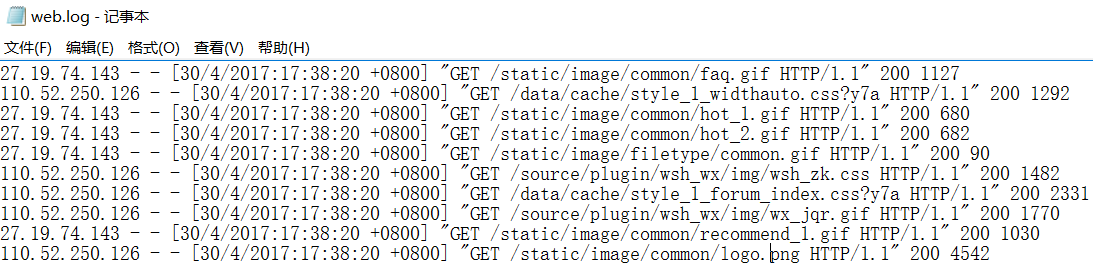
4)上传到/hadoop/home/logs
hadoop01输出:

hadoop05输出:

由于hadoop05设置的优先级高于hadoop06,因此hadoop06无日志写入。
我们再看hdfs上,是否成功上传了日志文件:
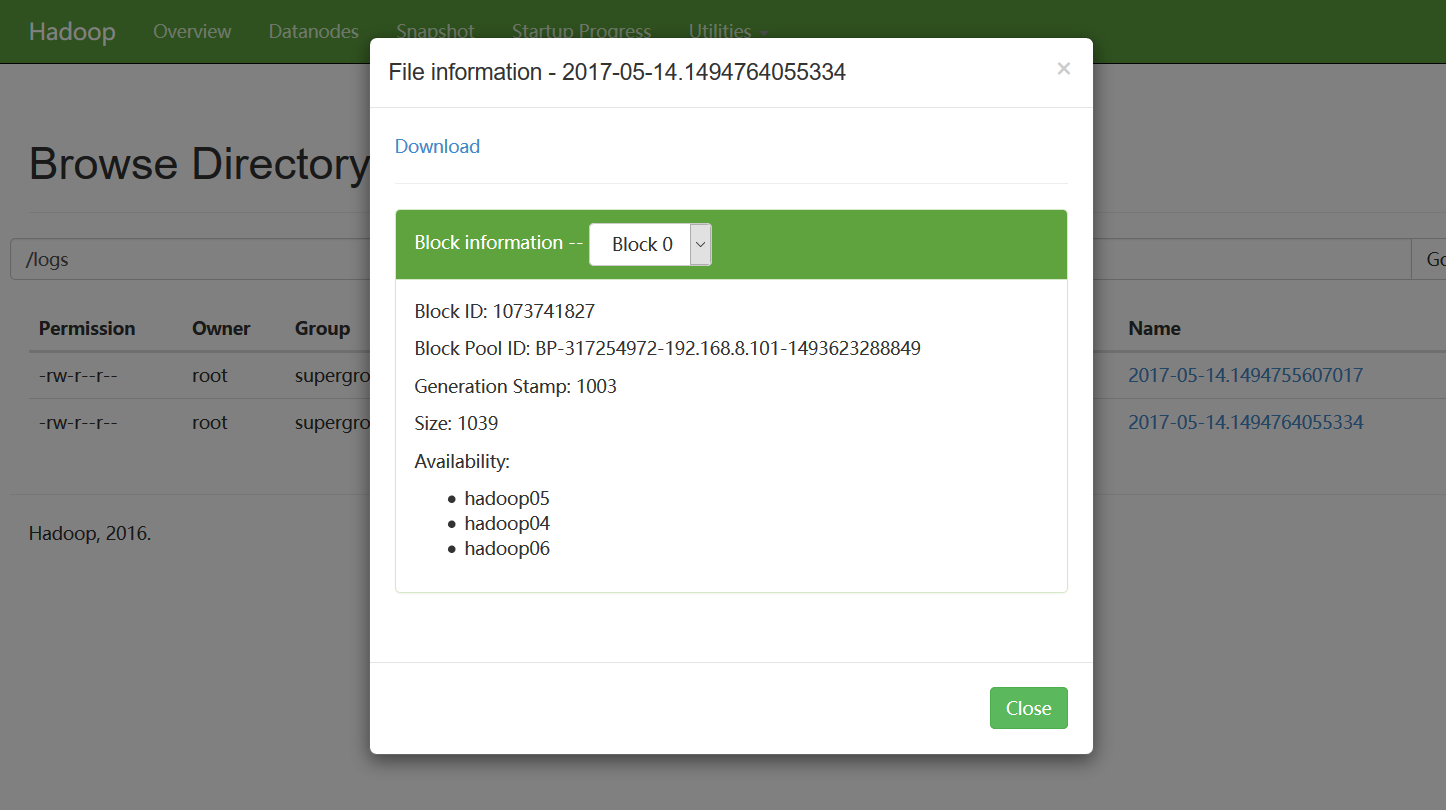
六、高可用性测试
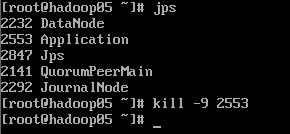
由于楼主设置的hadoop05的优先级要高于hadoop06,这也是上面的日志收集hadoop05输出而不是hadoop06输出的原因。现在我们干掉优先级高的hadoop05,看hadoop06是否能正常进行日志采集工作。

我们向日志源添加一个测试日志文件:

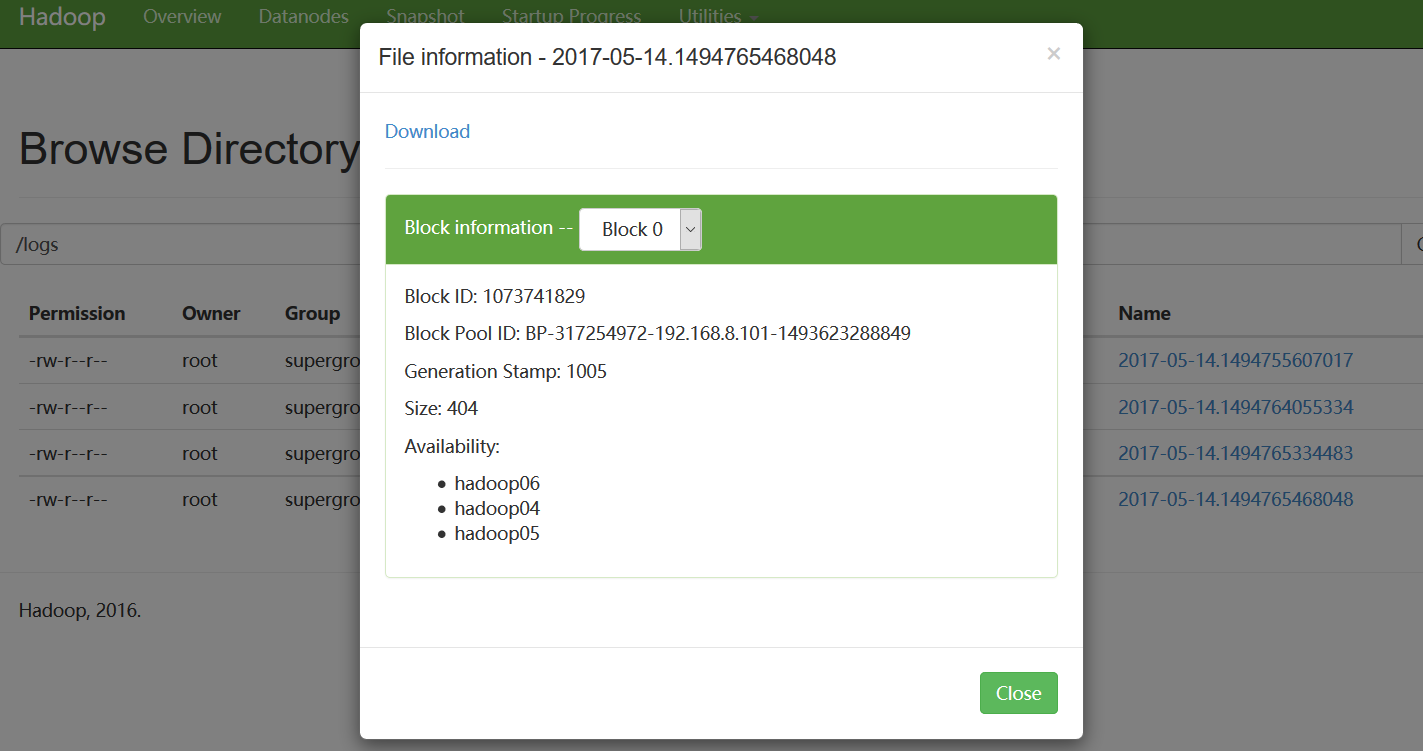
hadoop06输出:

查看hdfs:
好了!flume集群配置及日志收集就介绍到这里,下次楼主楼主会具体介绍利用mapreduce对日志进行清洗,并存储到hbase相关的内容。
flume集群日志收集的更多相关文章
- CentOS7下 简单安装和配置Elasticsearch Kibana Filebeat 快速搭建集群日志收集平台
目录 1.添加elasticsearch官网的yum源 2.Elasticsearch 安装elasticsearch 配置elasticsearch 启动elasticsearch并设为开机启动 3 ...
- 分布式实时日志系统(二) 环境搭建之 flume 集群搭建/flume ng资料
最近公司业务数据量越来越大,以前的基于消息队列的日志系统越来越难以满足目前的业务量,表现为消息积压,日志延迟,日志存储日期过短,所以,我们开始着手要重新设计这块,业界已经有了比较成熟的流程,即基于流式 ...
- ElasticSearch+Logstash+Filebeat+Kibana集群日志管理分析平台搭建
一.ELK搜索引擎原理介绍 在使用搜索引擎是你可能会觉得很简单方便,只需要在搜索栏输入想要的关键字就能显示出想要的结果.但在这简单的操作背后是搜索引擎复杂的逻辑和许多组件协同工作的结果. 搜索引擎的组 ...
- centos7搭建ELK Cluster集群日志分析平台(一):Elasticsearch
应用场景: ELK实际上是三个工具的集合,ElasticSearch + Logstash + Kibana,这三个工具组合形成了一套实用.易用的监控架构, 很多公司利用它来搭建可视化的海量日志分析平 ...
- centos7搭建ELK Cluster集群日志分析平台
应用场景:ELK实际上是三个工具的集合,ElasticSearch + Logstash + Kibana,这三个工具组合形成了一套实用.易用的监控架构, 很多公司利用它来搭建可视化的海量日志分析平台 ...
- Elasticstack 5.1.2 集群日志系统部署及实践
Elasticstack 5.1.2 集群日志系统部署及实践 一.ELK Stack简介 ELK Stack 是Elasticsearch.Logstash.Kibana三个开源软件的组合,在实时数据 ...
- Kubernetes 集群日志 和 EFK 架构日志方案
目录 第一部分:Kubernetes 日志 Kubernetes Logging 是如何工作的 Kubernetes Pod 日志存储位置 Kubelet Logs Kubernetes 容器日志格式 ...
- 【转】flume+kafka+zookeeper 日志收集平台的搭建
from:https://my.oschina.net/jastme/blog/600573 flume+kafka+zookeeper 日志收集平台的搭建 收藏 jastme 发表于 10个月前 阅 ...
- 基于Flume的美团日志收集系统(二)改进和优化
在<基于Flume的美团日志收集系统(一)架构和设计>中,我们详述了基于Flume的美团日志收集系统的架构设计,以及为什么做这样的设计.在本节中,我们将会讲述在实际部署和使用过程中遇到的问 ...
随机推荐
- bootstrap-typeahead自动补充
官方文档:https://github.com/bassjobsen/Bootstrap-3-Typeahead 这个是基于bootstrap的typeahead与基于jquery的jquery-Ty ...
- unity插件开发——一个例子:简单的svn集成
在unity开发过程中,通常我们习惯性地在Windows操作系统下使用svn进行版本管理,而每次提交更新,都需要回到文件夹下的这种操作让人无法忍受.是不是可以集成svn到unity中呢?查了一圈uni ...
- 深入PHP变量存储结构 标签: PHP存储
1.深入PHP变量存储结构 标签: PHP存储 分类: 编程语言(10) 首先声明,我并没有去读PHP的源码,只是对于PHP的有时候诡异的表现感兴趣,找了一下开发人员laruence的博客结合PH ...
- Ubuntu16.04安装xampp及部署Testlink
一.从官网下载xampp并安装: https://www.apachefriends.org/zh_cn/index.html chmod +x xampp-linux-x64-5.6.30-0-in ...
- Luogu2723丑数Humble Numbers【归并排序】
Luogu2723丑数Humble Numbers 题目背景 对于一给定的素数集合 S = {p1, p2, ..., pK},考虑一个正整数集合,该集合中任一元素的质因数全部属于S.这个正整数集合包 ...
- [SinGuLaRiTy] 树形DP专项测试
[SinGuLaRiTy-1015] Copyright (c) SinGuLaRiTy 2017. All Rights Reserved. 对于所有的题目:Time Limit:1s | Me ...
- 大数据测试之hadoop集群配置和测试
大数据测试之hadoop集群配置和测试 一.准备(所有节点都需要做):系统:Ubuntu12.04java版本:JDK1.7SSH(ubuntu自带)三台在同一ip段的机器,设置为静态IP机器分配 ...
- 老李分享:android手机测试之适配(1)
Android的屏幕适配一直以来都在折磨着我们这些开发者,本篇文章以Google的官方文档为基础,全面而深入的讲解了Android屏幕适配的原因.重要概念.解决方案及最佳实践,我相信如果你能认真的学习 ...
- 利用php数组函数进行函数式编程
因为一个BUG, 我在一个摇摇欲坠,几乎碰一下就会散架的项目中某一个角落中发现下面这样一段代码 这段程序与那个BUG有密切的关系. 我来回反复的捉摸这段代码, 发现这段代码实现了两个功能 第一个是在一 ...
- spring+mybatis事务不起作用的原因
一.场景再现 @Override @Transactional public void updateById(String userId,String username) throws Excepti ...