python识别html主要文本框
在抓取网页的时候只想抓取主要的文本框,例如 csdn 中的主要文本框为下图红色框:
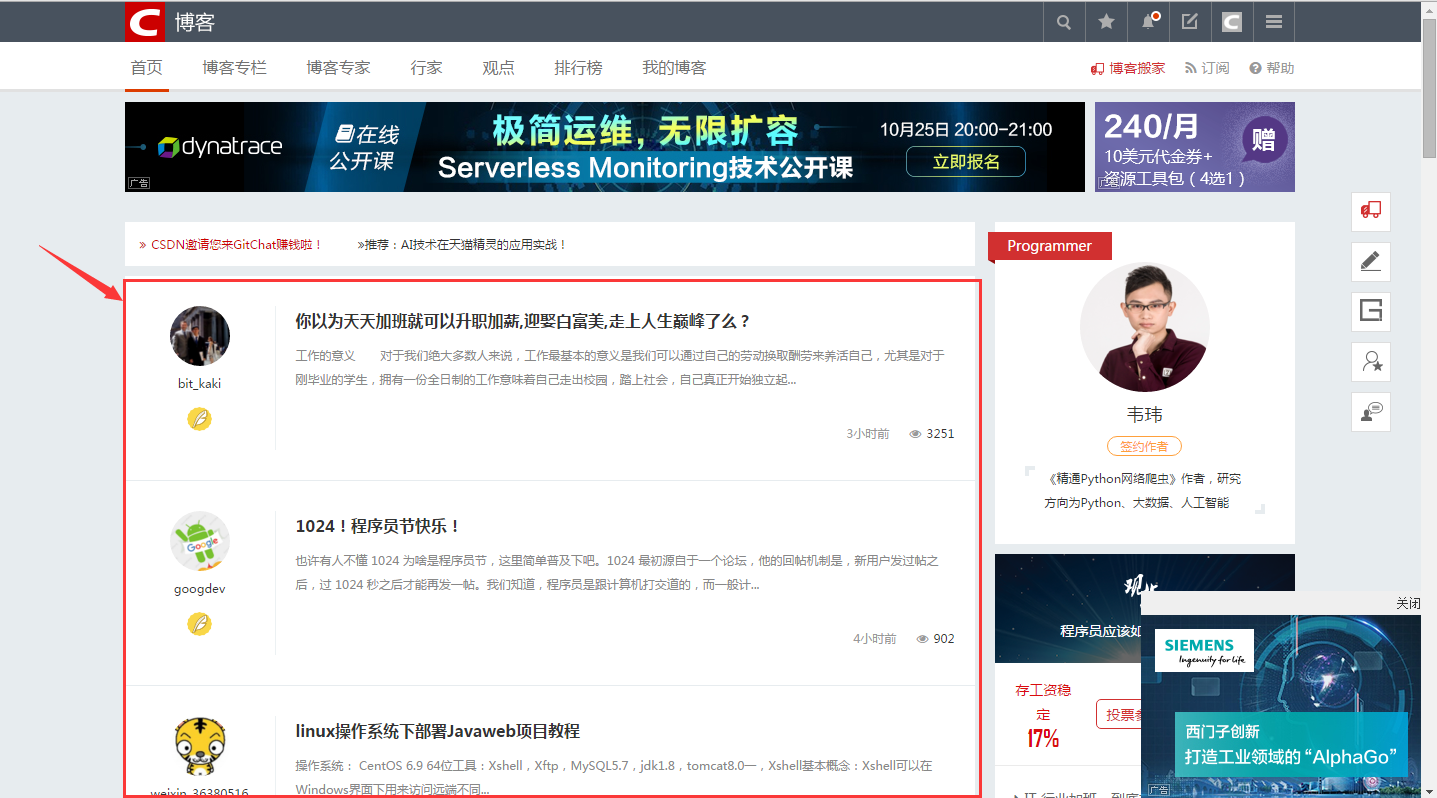
抓取的思想是,利用 bs4 查找所有的 div,用正则筛选出每个 div 里面的中文,找到中文字数最多的 div 就是属于正文的 div 了。定义一个抓取的头部抓取网页内容:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36',
'Host': 'blog.csdn.net'}
session = requests.session()
def getHtmlByRequests(url):
headers.update(
dict(Referer=url, Accept="*/*", Connection="keep-alive"))
htmlContent = session.get(url=url, headers=headers).content
return htmlContent.decode("utf-8", "ignore")
识别每个 div 中文字的正则:
import re
# 统计中文字数
def countContent(string):
pattern = re.compile(u'[\u1100-\uFFFD]+?')
content = pattern.findall(string)
return content
遍历每一个 div ,利用正则判断里面中文的字数长度,找到长度最长的 div :
# 分析页面信息
def analyzeHtml(html):
# 初始化网页
soup = BeautifulSoup(html, "html.parser")
part = soup.select('div')
match = ""
for paragraph in part:
content = countContent(str(paragraph))
if len(content) > len(match):
match = str(paragraph)
return match
得到主要的 div 后,提取里面的文字出来:
def main():
url = "http://blog.csdn.net/"
html = getHtmlByRequests(url)
mainContent = analyzeHtml(html)
soup = BeautifulSoup(mainContent, "html.parser")
print(soup.select('div')[0].text)
完整的代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
import re
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36',
'Host': 'blog.csdn.net'}
session = requests.session()
def getHtmlByRequests(url):
headers.update(
dict(Referer=url, Accept="*/*", Connection="keep-alive"))
htmlContent = session.get(url=url, headers=headers).content
return htmlContent.decode("utf-8", "ignore")
# 统计中文字数
def countContent(string):
pattern = re.compile(u'[\u1100-\uFFFD]+?')
content = pattern.findall(string)
return content
# 分析页面信息
def analyzeHtml(html):
# 初始化网页
soup = BeautifulSoup(html, "html.parser")
part = soup.select('div')
match = ""
for paragraph in part:
content = countContent(str(paragraph))
if len(content) > len(match):
match = str(paragraph)
return match
def main():
url = "http://blog.csdn.net/"
html = getHtmlByRequests(url)
mainContent = analyzeHtml(html)
soup = BeautifulSoup(mainContent, "html.parser")
print(soup.select('div')[0].text)
if __name__ == '__main__':
main()
python识别html主要文本框的更多相关文章
- python开发_tkinter_获取文本框内容_给文本框添加键盘输入事件
在之前的blog中有提到python的tkinter中的菜单操作 python开发_tkinter_窗口控件_自己制作的Python IDEL_博主推荐 python开发_tkinter_窗口控件_自 ...
- python tkinter-按钮.标签.文本框、输入框
按钮 无功能按钮 Button的text属性显示按钮上的文本 tkinter.Button(form, text='hello button').pack() 无论怎么变幻窗体大小,永远都在窗体的最上 ...
- python selenium无法清除文本框内容问题
正常是我们在清除文本框内容的时候,都会使用 clear() 函数进行清除,但是有时候会出现,清除完成后再点击查询时,文本框的内容会再次自动填充,这个时候我们可以选择以下方式: #清空查询条件drive ...
- (2)python tkinter-按钮.标签.文本框、输入框
按钮 无功能按钮 Button的text属性显示按钮上的文本 tkinter.Button(form, text='hello button').pack() 无论怎么变幻窗体大小,永远都在窗体的最上 ...
- Selenium示例集锦--常见元素识别方法、下拉框、文本域及富文本框、鼠标操作、一组元素定位、弹窗、多窗口处理、JS、frame、文件上传和下载
元素定位及其他操作 0.常见的识别元素的方法是什么? driver.find_element_by_id() driver.find_element_by_name() driver.find_ele ...
- wxpython 支持python语法高亮的自定义文本框控件的代码
在研发闲暇时间,把开发过程中比较重要的一些代码做个珍藏,下面的代码内容是关于wxpython 支持python语法高亮的自定义文本框控件的代码,应该是对大家也有用. import keywordimp ...
- Python Tkinter Entry(文本框)
Python学习记录--关于Tkinter Entry(文本框)的选项.方法说明,以及一些示例. 属性(Options) background(bg) borderwidth(bd) cursor e ...
- python webdriver api-操作富文本框
操作富文本框-就是邮件正文部分,可以选字体啥的 第一种方式: 一般都是在iframe里,要切进去,一般是”html/body”,编辑之后,再切出来,然后再send_keys就完事儿 #encoding ...
- Python+selenium之获取文本值和下拉框选择数据
Python+selenium之获取文本值和下拉框选择数据 一.结合实例进行描述 1. 实例如下所示: #新增标签操作 def func_labels(self): self.driver.find_ ...
随机推荐
- 201521123033《Java程序设计》第14周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多数据库相关内容. 2. 书面作业 1. MySQL数据库基本操作 建立数据库,将自己的姓名.学号作为一条记录插入.(截图,需出现自 ...
- 201521123009 《Java程序设计》第13周学习总结
1. 本周学习总结 2. 书面作业 1. 网络基础 1.1 比较ping www.baidu.com与ping cec.jmu.edu.cn,分析返回结果有何不同?为什么会有这样的不同? 从上图来看, ...
- Java:@Override标签的多态性详解
Override(重写)是子类与父类的一种多态性体现. Override允许子类改变父类的一些行为. 为什么需要Override:当父类不满足子类的一些要求时我们就需要子类对父类的一些行为进行重写. ...
- python数据分析panda库
panda内有两种数据结构,Series()和DataFrame() >>> a=pd.Series([1,2],index=['a','b']) >>> a a ...
- Hibernate table schema 的设置与应用
hibernate在实现实体映射时,DB无需强行指定.部署时会较对DB户名和密码,根据用户名以访问的表完成实体映射.如果一个帐号可以访问一个数据库的下多个表,以oracle为例用户user1下面有表t ...
- 凸包GiftWrapping GrahamScan 算法实现
开始 游戏内有需求做多边形碰撞功能,但是接入box2d相对游戏的需求来说太重度了.所以准备自己实现碰撞. 确定多边形,必然要用到凸包的算法.在github上也找到了一些lua实现,但是这里的算法没有考 ...
- 支持向量机SVM(Support Vector Machine)
支持向量机(Support Vector Machine)是一种监督式的机器学习方法(supervised machine learning),一般用于二类问题(binary classificati ...
- oracle 数据库管理--管理表空间和数据文件
一.概念表空间是数据库的逻辑组成部分.从物理上讲,数据库数据存放在数据文件中:从逻辑上讲,数据库数据则是存放在表空间中,表空间由一个或多个数据文件组成. 二.数据库的逻辑结构oracle中逻辑结构包括 ...
- program 1 : python codes for login program(登录程序python代码)
#improt time module for count down puase time import time #set var for loop counting counter=1 #logi ...
- es6函数的rest参数和拓展运算符(...)的解析
es6的新特性对函数的功能新增加了rest参数和...的拓展运算符.这是两个什么东西呢? 先来看一个问题:如何获取一个函数除了定义的参数之外的其他参数?传统的做法是借助函数的arguments关键字来 ...