python识别html主要文本框
在抓取网页的时候只想抓取主要的文本框,例如 csdn 中的主要文本框为下图红色框:
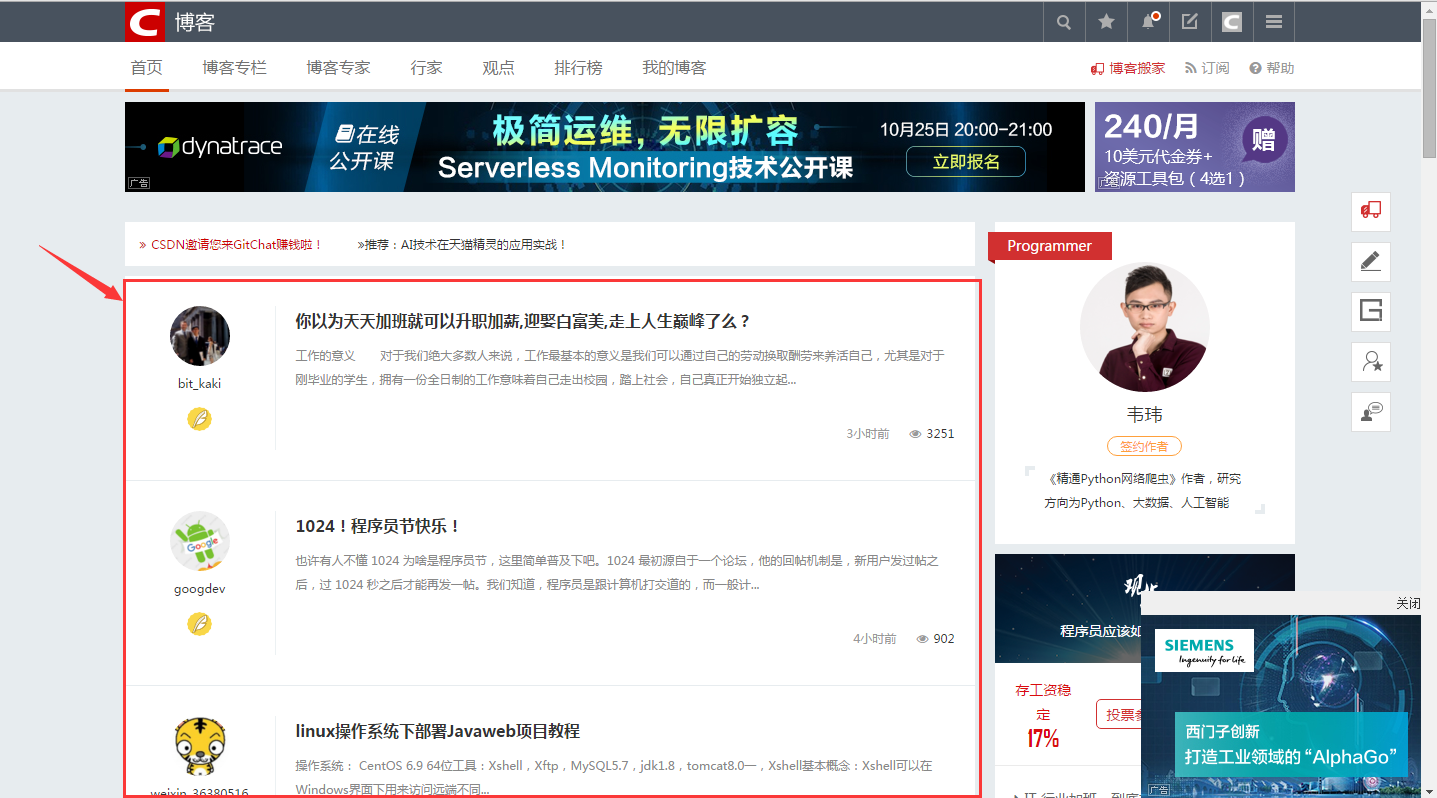
抓取的思想是,利用 bs4 查找所有的 div,用正则筛选出每个 div 里面的中文,找到中文字数最多的 div 就是属于正文的 div 了。定义一个抓取的头部抓取网页内容:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36',
'Host': 'blog.csdn.net'}
session = requests.session()
def getHtmlByRequests(url):
headers.update(
dict(Referer=url, Accept="*/*", Connection="keep-alive"))
htmlContent = session.get(url=url, headers=headers).content
return htmlContent.decode("utf-8", "ignore")
识别每个 div 中文字的正则:
import re
# 统计中文字数
def countContent(string):
pattern = re.compile(u'[\u1100-\uFFFD]+?')
content = pattern.findall(string)
return content
遍历每一个 div ,利用正则判断里面中文的字数长度,找到长度最长的 div :
# 分析页面信息
def analyzeHtml(html):
# 初始化网页
soup = BeautifulSoup(html, "html.parser")
part = soup.select('div')
match = ""
for paragraph in part:
content = countContent(str(paragraph))
if len(content) > len(match):
match = str(paragraph)
return match
得到主要的 div 后,提取里面的文字出来:
def main():
url = "http://blog.csdn.net/"
html = getHtmlByRequests(url)
mainContent = analyzeHtml(html)
soup = BeautifulSoup(mainContent, "html.parser")
print(soup.select('div')[0].text)
完整的代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
import re
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36',
'Host': 'blog.csdn.net'}
session = requests.session()
def getHtmlByRequests(url):
headers.update(
dict(Referer=url, Accept="*/*", Connection="keep-alive"))
htmlContent = session.get(url=url, headers=headers).content
return htmlContent.decode("utf-8", "ignore")
# 统计中文字数
def countContent(string):
pattern = re.compile(u'[\u1100-\uFFFD]+?')
content = pattern.findall(string)
return content
# 分析页面信息
def analyzeHtml(html):
# 初始化网页
soup = BeautifulSoup(html, "html.parser")
part = soup.select('div')
match = ""
for paragraph in part:
content = countContent(str(paragraph))
if len(content) > len(match):
match = str(paragraph)
return match
def main():
url = "http://blog.csdn.net/"
html = getHtmlByRequests(url)
mainContent = analyzeHtml(html)
soup = BeautifulSoup(mainContent, "html.parser")
print(soup.select('div')[0].text)
if __name__ == '__main__':
main()
python识别html主要文本框的更多相关文章
- python开发_tkinter_获取文本框内容_给文本框添加键盘输入事件
在之前的blog中有提到python的tkinter中的菜单操作 python开发_tkinter_窗口控件_自己制作的Python IDEL_博主推荐 python开发_tkinter_窗口控件_自 ...
- python tkinter-按钮.标签.文本框、输入框
按钮 无功能按钮 Button的text属性显示按钮上的文本 tkinter.Button(form, text='hello button').pack() 无论怎么变幻窗体大小,永远都在窗体的最上 ...
- python selenium无法清除文本框内容问题
正常是我们在清除文本框内容的时候,都会使用 clear() 函数进行清除,但是有时候会出现,清除完成后再点击查询时,文本框的内容会再次自动填充,这个时候我们可以选择以下方式: #清空查询条件drive ...
- (2)python tkinter-按钮.标签.文本框、输入框
按钮 无功能按钮 Button的text属性显示按钮上的文本 tkinter.Button(form, text='hello button').pack() 无论怎么变幻窗体大小,永远都在窗体的最上 ...
- Selenium示例集锦--常见元素识别方法、下拉框、文本域及富文本框、鼠标操作、一组元素定位、弹窗、多窗口处理、JS、frame、文件上传和下载
元素定位及其他操作 0.常见的识别元素的方法是什么? driver.find_element_by_id() driver.find_element_by_name() driver.find_ele ...
- wxpython 支持python语法高亮的自定义文本框控件的代码
在研发闲暇时间,把开发过程中比较重要的一些代码做个珍藏,下面的代码内容是关于wxpython 支持python语法高亮的自定义文本框控件的代码,应该是对大家也有用. import keywordimp ...
- Python Tkinter Entry(文本框)
Python学习记录--关于Tkinter Entry(文本框)的选项.方法说明,以及一些示例. 属性(Options) background(bg) borderwidth(bd) cursor e ...
- python webdriver api-操作富文本框
操作富文本框-就是邮件正文部分,可以选字体啥的 第一种方式: 一般都是在iframe里,要切进去,一般是”html/body”,编辑之后,再切出来,然后再send_keys就完事儿 #encoding ...
- Python+selenium之获取文本值和下拉框选择数据
Python+selenium之获取文本值和下拉框选择数据 一.结合实例进行描述 1. 实例如下所示: #新增标签操作 def func_labels(self): self.driver.find_ ...
随机推荐
- 201521123025《java程序设计》第14周学习总结
1. 本周学习总结 2. 书面作业 1. MySQL数据库基本操作 1.1建立数据库,将自己的姓名.学号作为一条记录插入.(截图,需出现自己的学号.姓名) 1.2在自己建立的数据库上执行常见SQL语句 ...
- 201521123075 《Java程序设计》第14周学习总结
1. 本周学习总结 2. 书面作业 1. MySQL数据库基本操作 建立数据库,将自己的姓名.学号作为一条记录插入.(截图,需出现自己的学号.姓名) 在自己建立的数据库上执行常见SQL语句(截图) 参 ...
- php环境和apache服务启动不的解决方法
安装服务器,可能需要设置apache的端口号,用记事本打开httpd.conf ctrl+F搜索80,在中间添加数字8 08 0,不解释 在sql中配置好了服务器 服务器安装路径中的WWW文件作为服 ...
- Eclipse rap 富客户端开发总结(10) : Rap不同系统间的差异和处理方式
平常进行 rap 程序开发一般都是在 win 下面完成 , 然后在 tomcat 下面测试 , 但是程序最终发布一般都是在 linux aix 上面 , 这个时候就有能会出现一下问题,下面 2 个问 ...
- 一种Webconfig自动化升级方法
1.方法功能 使用本方法,可以将开发环境最新版本的web.config结构与生产环境环境的config融合,而不用考虑两个config的版本差异值是多少.使用一种标记的方式,在开发环境webconfi ...
- Android 之异步加载LoaderManager
LoaderManager: Loader出现的背景: Activity是我们的前端页面展现,数据库是我们的数据持久化地址,那么正常的逻辑就是在展示页面的渲染页面的阶段进行数据库查询.拿到数据以后才展 ...
- Android性能优化xml之<include>、<merge>、<ViewStub>标签的使用
一.使用<include>标签对"重复代码"进行复用 <include>标签是我们进行Android开发中经常用到的标签,比如多个界面都同样用到了一个左侧筛 ...
- [C#]关于DBNULL的解释
1 概述 如下例子,你觉得有什么问题?如你能很快的找出问题,并且解决它,那么你可以跳过本篇文章,谢谢~~. List<Base_Employee> ltPI = new List< ...
- Check for Palindromes-FCC
問題: 检查回文字符串 如果给定的字符串是回文,返回true,反之,返回false. 如果一个字符串忽略标点符号.大小写和空格,正着读和反着读一模一样,那么这个字符串就是palindrome(回文). ...
- Perfect Pth Powers poj1730
Perfect Pth Powers Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 16383 Accepted: 37 ...