(转)新手写爬虫v2.5(使用代理的异步爬虫)
开始
开篇:爬代理ip v2.0(未完待续),实现了获取代理ips,并把这些代理持久化(存在本地)。同时使用的是tornado的HTTPClient的库爬取内容。
中篇:开篇主要是获取代理ip;中篇打算使用代理ip,同时优化代码,并且异步爬取内容。所以接下来,就是写一个:异步,使用代理的爬虫。定义为:爬虫 v2.5
为什么使用代理
在开篇中我们爬来的代理ip怎么用?
在需要发送请求的时候,需要把请求,先发送到代理服务器(通过代理ip和端口),再由代理服务器请求目标网站。目标网站返回响应的时候也是先返回给代理服务器。所以代理(代理服务器)做的事情就是转发请求,在转发请求的时候有三种方式,也就是分别对应着,透明代理、匿名代理、高匿名代理,解释请看开篇。
所以,如果使用高匿名代理,就不会暴露真实的ip,目标网站只知道代理的ip。让爬虫循环使用把爬来的高匿名ip,从而降低,单一ip爬虫的被封ip和访问频率的问题。
使用代理
1.事情要一步步的做,首先我需要验证代理IP是否可用!最简单的方法就是用Request库,下面的例子,我就用Request官方文档的示例:
import requests
# 测试代理是否可用的URL,TEST_PROXY这个网站只返回访问者的ip
TEST_PROXY = 'http://icanhazip.com'
proxies = {
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080",
}
requests.get(TEST_PROXY, proxies=proxies)2.现在把爬取代理的方法和测试代理是否可用的方法,写成一个Proxy类。Proxy类做的事情就是‘返回经过测试的可用代理’,整理后代码如下:
class Proxy(object):
"""
获取代理ips
"""
def __init__(self, url, **kwargs):
self.response = Spider(url, **kwargs).get()
def test_proxy(self):
""" 返回经测试可用的代理 """
fail_num = 1
success_num = 1
success_proxy = []
for ip_info in self.ips_info:
proxy_str = ip_info['proxy_host']+':'+ip_info['proxy_port']
proxies = dict(http='http://'+proxy_str)
try:
requests.get("http://icanhazip.com", timeout=5, proxies=proxies)
except Exception:
print '失败数:{}'.format(fail_num)
fail_num += 1
continue
else:
print '成功数:{}!'.format(success_num)
success_num += 1
success_proxy.append(ip_info)
# 返回测试过,可用的代理
print '结束:成功获取{}个代理'.format(len(success_proxy))
return success_proxy
@property
def ips_info(self):
""" 清理内容得到IP信息 """
ips_list = []
html_body = self.response.body
soup = BeautifulSoup(html_body, "html.parser")
ip_list_table = soup.find(id='ip_list')
for fi_ip_info in ip_list_table.find_all('tr'):
ip_detail = fi_ip_info.find_all('td')
if ip_detail:
# 注意:为什么我用list和str方法?否则就是bs4对象!!!
ips_list.append(dict(proxy_host=str(list(ip_detail)[2].string),
proxy_port=str(list(ip_detail)[3].string)))
return ips_list3.现在有Proxy类和Content类(开篇存储代理),下面写一个方法,把得到的,可用的代理ip,存到数据库中或许文本中。Content类,我修改一些地方,代码整理如下:
def get_proxy_ips():
""" 获取代理ips,并存储 """
try:
proxy = Proxy(url=URL, headers=CLIENT_CONFIG['headers'])
ips_list = proxy.test_proxy()
print ips_list
except HTTPError as e:
print '{}:Try again!!!'.format(e)
get_proxy_ips()
else:
# 存到数据库中
t = Content(models.Proxy)
for ip_data in ips_list:
t.save(ip_data)
# 默认存到运行运行脚本的目录,文件名:data.txt
t = Content()
t.save_to_file(ips_list)好了,下面就要开始写异步的代理爬虫了。
异步的代理爬虫
tornado的所有HTTPClient中,只有CurlAsyncHTTPClient支持代理。具体的实现逻辑请查看curl_httpclient源码,它也支持异步,所以接下来就是使用CurlAsyncHTTPClient的get方法,带着代理的host和port(注意:不需要指明协议)。代码如下:
@gen.coroutine
def main():
flag = 1
ips_list = models.Proxy.find_all()
for ip in ips_list:
while 1:
print 'proxy_ip {}:{}'.format(ip['proxy_host'], ip['proxy_port'])
try:
s = Spider(TEST, headers=CLIENT_CONFIG['headers'],
proxy_host=ip['proxy_host'], request_timeout=5,
proxy_port=int(ip['proxy_port']))
response = yield s.async_get()
print 'NO:{}: status {}'.format(flag, response.code)
except HTTPError, e:
print '换代理,错误信息:{}'.format(e)
break
else:
flag += 1
if __name__ == '__main__':
get_proxy_ips()
IOLoop().run_sync(main)优化改进
写完这个主爬虫,我思考了一下,那是否test_proxy方法是否也可以用异步呢?还有就是不应该使用requests库,因为tornado使用的PycURL库,同时我去看官方文档的时候关于速度的说明,PycURL文档
Speed - libcurl is very fast and PycURL, being a thin wrapper above libcurl, is very fast as well. PycURL was benchmarked to be several times faster than requests.
最后,支持直接用行脚本,兼容不使用数据库。全部代码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#
# Author : XueWeiHan
# E-mail : 595666367@qq.com
# Date : 16/3/31 下午4:21
# Desc : 爬虫 v2.5
from bs4 import BeautifulSoup
from tornado.httpclient import HTTPRequest, HTTPClient, HTTPError
from tornado.curl_httpclient import CurlAsyncHTTPClient
from tornado import gen
from tornado.ioloop import IOLoop
try:
from model import db
from model import models
from config import configs
NO_DB = 1
# 连接数据库
db.create_engine(**configs['db'])
except ImportError:
# NO_DB表示不用数据库
NO_DB = 0
print "Can't use db"
from client_config import CLIENT_CONFIG
# 测试用的访问目标(github API)
TEST = 'https://api.github.com/search/users?q=tom+repos:%3E42+followers:%3E1000'
# 测试代理是否可用的URL
TEST_PROXY = 'http://icanhazip.com'
# 获取代理的目标网站
URL = 'http://www.xicidaili.com/nn/' # 高匿ip
#URL = 'http://www.xicidaili.com/nt/' # 透明ip
class Spider(object):
"""
爬
"""
def __init__(self, url, **kwargs):
self.request = HTTPRequest(url, **kwargs)
@gen.coroutine
def async_get(self, **kwargs):
""" 异步get """
## 注意:只有CurlAsyncHTTPClient支持代理,所以这里用它
response = yield CurlAsyncHTTPClient().fetch(self.request, **kwargs)
raise gen.Return(response)
def get(self, **kwargs):
""" 同步get """
return HTTPClient().fetch(self.request, **kwargs)
def post(self):
""" post暂时没用,先占坑 """
self.request.method = "POST"
return HTTPClient().fetch(self.request)
class Content(object):
"""
存储(持久化)相关操作
"""
def __init__(self, model=None):
self.model = model
def save(self, save_dict=None):
""" 存到数据库 """
if self.model:
if save_dict:
data = self.model(**save_dict)
data.insert()
else:
print 'no save_dict'
else:
print 'no model'
@staticmethod
def save_to_file(all_content, str_split=':', path='./data.txt'):
"""
把数据存到文件中
:param all_content: 需要是list类型
:param str_split: 分割符号
:param path: 文件位置,默认为当前脚本运行的位置,文件名:data.txt
"""
with open(path, 'w') as fb:
print '开始写入文件'
for content in all_content:
content_str = ''
for k, v in content.items():
content_str += v + str_split
fb.write(content_str+'\n')
print '写入文件完成'
class Proxy(object):
"""
获取代理ips
"""
def __init__(self, url, **kwargs):
self.response = Spider(url, **kwargs).get()
@gen.coroutine
def test_proxy(self):
""" 返回经测试可用的代理 """
# flag用于计数
flag = 1
all_ips = self.ips_info()
print '初始化爬到{}个代理,下面开始测试这些代理的可用性:'.format(len(all_ips))
success_proxy = []
for ip_info in all_ips:
try:
s = Spider(TEST_PROXY, headers=CLIENT_CONFIG['headers'],
proxy_host=ip_info['proxy_host'], request_timeout=5,
proxy_port=int(ip_info['proxy_port']))
yield s.async_get()
except Exception:
print '第{}个,失败。'.format(flag)
continue
else:
print '第{}个:成功!'.format(flag)
success_proxy.append(ip_info)
finally:
flag += 1
# 返回测试过,可用的代理
print '经测试:{}个可用,可用率:{}%'.format(len(success_proxy),
len(success_proxy)/len(all_ips))
raise gen.Return(success_proxy)
def ips_info(self):
""" 清理内容得到IP信息 """
ips_list = []
html_body = self.response.body
soup = BeautifulSoup(html_body, "html.parser")
ip_list_table = soup.find(id='ip_list')
for fi_ip_info in ip_list_table.find_all('tr'):
ip_detail = fi_ip_info.find_all('td')
if ip_detail:
# 注意:为什么我用list和str方法?否则就是bs4对象!!!
ips_list.append(dict(proxy_host=str(list(ip_detail)[2].string),
proxy_port=str(list(ip_detail)[3].string)))
return ips_list
@gen.coroutine
def get_proxy_ips():
""" 获取代理ips,并存储 """
try:
proxy = Proxy(url=URL, headers=CLIENT_CONFIG['headers'])
ips_list = yield proxy.test_proxy()
except HTTPError as e:
print 'Try again! Error info:{}'.format(e)
else:
if NO_DB:
# 存到数据库中
t = Content(models.Proxy)
for ip_data in ips_list:
t.save(ip_data)
# 默认存到运行运行脚本的目录,文件名:data.txt
t = Content()
t.save_to_file(ips_list)
raise gen.Return(ips_list)
@gen.coroutine
defmain():
""" 使用代理的异步爬虫 """
flag = 1
ips_list = yield get_proxy_ips()
for ip in ips_list:
while 1:
print 'Use proxy ip {}:{}'.format(ip['proxy_host'], ip['proxy_port'])
try:
# 这里就是异步的代理爬虫,利用代理获取目标网站的信息
s = Spider(TEST, headers=CLIENT_CONFIG['headers'],
proxy_host=ip['proxy_host'], request_timeout=10,
proxy_port=int(ip['proxy_port']))
# response爬虫返回的response对象,response.body就是内容
response = yield s.async_get()
print 'NO:{}: status {}'.format(flag, response.code)
except HTTPError, e:
print '换代理,错误信息:{}'.format(e)
break
else:
flag += 1
if __name__ == '__main__':
IOLoop().run_sync(main)运行效果:
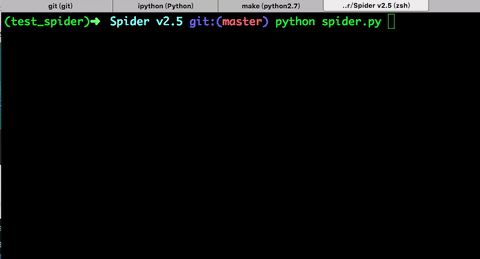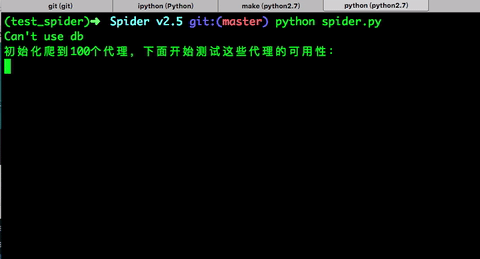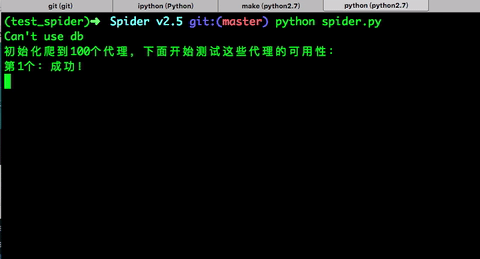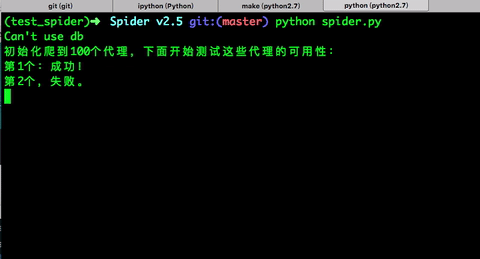
TODO
这个脚本可用性还是很差,因为爬的是免费代理,代理的稳定性很差,很差,很差!!!会导致,测试可用的代理。但是在使用的时候就连不上了!所以,后面想学习怎么自己搞到代理。我发现使用代理的爬虫,代理的稳定性,至关重要!应该会用到的技术:扫端口?计算机网络的知识。
现在的流程是:爬取并测试所有的代理,然后持久化可用的代理。后面想做成,如果有成功的代理,后面的爬虫就工作,使用成功的代理爬取目标URL。应该会用到的技术:队列,多线程
速度还是很慢。
(转)新手写爬虫v2.5(使用代理的异步爬虫)的更多相关文章
- [python]新手写爬虫v2.5(使用代理的异步爬虫)
开始 开篇:爬代理ip v2.0(未完待续),实现了获取代理ips,并把这些代理持久化(存在本地).同时使用的是tornado的HTTPClient的库爬取内容. 中篇:开篇主要是获取代理ip:中篇打 ...
- 深入理解协程(四):async/await异步爬虫实战
本文目录: 同步方式爬取博客标题 async/await异步爬取博客标题 本片为深入理解协程系列文章的补充. 你将会在从本文中了解到:async/await如何运用的实际的爬虫中. 案例 从CSDN上 ...
- [Python]新手写爬虫全过程(转)
今天早上起来,第一件事情就是理一理今天该做的事情,瞬间get到任务,写一个只用python字符串内建函数的爬虫,定义为v1.0,开发中的版本号定义为v0.x.数据存放?这个是一个练手的玩具,就写在tx ...
- [Python]新手写爬虫全过程(已完成)
今天早上起来,第一件事情就是理一理今天该做的事情,瞬间get到任务,写一个只用python字符串内建函数的爬虫,定义为v1.0,开发中的版本号定义为v0.x.数据存放?这个是一个练手的玩具,就写在tx ...
- (转)Python新手写出漂亮的爬虫代码2——从json获取信息
https://blog.csdn.net/weixin_36604953/article/details/78592943 Python新手写出漂亮的爬虫代码2——从json获取信息好久没有写关于爬 ...
- (转)Python新手写出漂亮的爬虫代码1——从html获取信息
https://blog.csdn.net/weixin_36604953/article/details/78156605 Python新手写出漂亮的爬虫代码1初到大数据学习圈子的同学可能对爬虫都有 ...
- Python爬虫02——贴吧图片爬虫V2.0
Python小爬虫——贴吧图片爬虫V2.0 贴吧图片爬虫进阶:在上次的第一个小爬虫过后,用了几次发现每爬一个帖子,都要自己手动输入帖子链接,WTF这程序简直反人类!不行了不行了得改进改进. 思路: 贴 ...
- 反爬虫之搭建IP代理池
反爬虫之搭建IP代理池 听说你又被封 ip 了,你要学会伪装好自己,这次说说伪装你的头部.可惜加了header请求头,加了cookie 还是被限制爬取了.这时就得祭出IP代理池!!! 下面就是requ ...
- python scrapy版 极客学院爬虫V2
python scrapy版 极客学院爬虫V2 1 基本技术 使用scrapy 2 这个爬虫的难点是 Request中的headers和cookies 尝试过好多次才成功(模拟登录),否则只能抓免费课 ...
随机推荐
- Serv-u Mysql数据库用户
Serv-u 关联Mysql数据库用户需要用到ODBC数据源,windows不自带支持MySQL.所以要网上下载自己安装 官网下载地址:http://dev.mysql.com/downloads/c ...
- Java复习随笔
1.StringTokenizer str = new StringTokenizer("字符串"); str.countTokns(); //可得出字符串非连续的个数(可用于 ...
- windows下配置cygwin和dig的环境变量
配置cygwin和dig的环境变量 打开"控制面板"("开始">"设置">"控制面板"),然后双击" ...
- 坏块管理(Bad Block Management,BBM)
看了很多坏块管理的文章,加上自己的理解,把整个坏块管理做了个总结. 坏块分类 1.出厂坏块 又叫初始坏块,厂商会给点最小有效块值(NVB,mininum number of valid blocks) ...
- if else 和switch case以及continue,break的区别
1,if 经常用于做区间判断 或者 固定值: break和continue的使用 break:用来结束循环结构或者switch case continue:结束此次循环进入 ...
- jdk 环境变量配置方法总结
全部修改在用户变量/系统变量 系统变量→新建 JAVA_HOME 变量 .变量值填写jdk的安装目录(本人是 D:\java\Java\jdk1.8.0_72) 系统变量→寻找 Path 变量→编辑在 ...
- C++ STL pair详解
一.解释: p { margin-bottom: 0.25cm; direction: ltr; color: #00000a; line-height: 120%; text-align: left ...
- 关于Java JDK中 URLDecoder.decode 方法
java.net.URLDecoder.decode 在项目中碰到了个比较奇怪的问题,就是我在本地使用java.net.URLDecoder.decode(ruleName)方法解码,没有问题,本地的 ...
- vue的一些坑(第一天)
1:刚开始在创建项目的时候一直出现vue不是内部或外部命令 关于这个的解决方案网上给出的很多的解决方案是配置环境,这个我就不在赘述了: 但是我觉得那样太麻烦,就没用,只是重新 npm i vue-cl ...
- python学习===打印时间
>>> import time >>> print(time.time()) 1501749158.9849465 >>> print(time. ...