Spark集群无法停止的原因分析和解决
今天想停止spark集群,发现执行stop-all.sh的时候spark的相关进程都无法停止。提示:
no org.apache.spark.deploy.master.Master to stop
no org.apache.spark.deploy.worker.Worker to stop
上网查了一些资料,再翻看了一下stop-all.sh,stop-master.sh,stop-slaves.sh,spark-daemon.sh,spark-daemons.sh等脚本,发现很有可能是由于$SPARK_PID_DIR的一个环境变量导致。
我搭建的是Hadoop2.6.0+Spark1.1.0+Yarn的集群。Spark、Hadoop和Yarn的停止,都是通过一些xxx.pid文件来操作的。以spark的stop-master为例,其中停止语句如下:

再查看spark-daemon.sh中的操作:
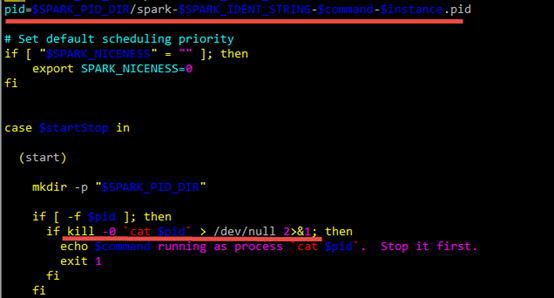
$SPARK_PID_DIR中存放的pid文件中,就是要停止进程的pid。其中$SPARK_PID_DIR默认是在系统的/tmp目录:
系统每隔一段时间就会清除/tmp目录下的内容。到/tmp下查看一下,果然没有相关进程的pid文件了。这才导致了stop-all.sh无法停止集群。
担心使用kill强制停止spark相关进程会破坏集群,因此考虑回复/tmp下的pid文件,再使用stop-all.sh来停止集群。
分析spark-daemon.sh脚本,看到pid文件命名规则如下:
pid=$SPARK_PID_DIR/spark-$SPARK_IDENT_STRING-$command-$instance.pid
其中
$SPARK_PID_DIR是/tmp
$SPARK_IDENT_STRING是登录用户$USER,我的集群中用户名是cdahdp
$command是调用spark-daemon.sh时的参数,有两个:
org.apache.spark.deploy.master.Master
org.apache.spark.deploy.worker.Worker
$instance也是调用spark-daemon.sh时的参数,我的集群中是1
因此pid文件名如下:
/tmp/spark-cdahdp-org.apache.spark.deploy.master.Master-1.pid
/tmp/spark-cdahdp-org.apache.spark.deploy.worker.Worker-1.pid
通过jps查看相关进程的pid:
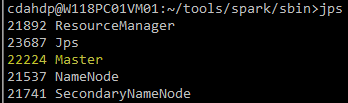
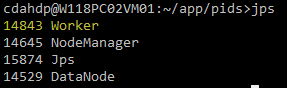
将pid保存到对应的pid文件即可。
之后调用spark的stop-all.sh,即可正常停止spark集群。
停止hadoop和yarn集群时,调用stop-all.sh,也会出现这个现象。其中NameNode,SecondaryNameNode,DataNode,NodeManager,ResourceManager等就是hadoop和yarn的相关进程,stop时由于找不到pid导致无法停止。分析方法同spark,对应pid文件名不同而已。
Hadoop的pid命名规则:
pid=$HADOOP_PID_DIR/hadoop-$HADOOP_IDENT_STRING-$command.pid
pid文件名:
/tmp/hadoop-cdahdp-namenode.pid
/tmp/hadoop-cdahdp-secondarynamenode.pid
/tmp/hadoop-cdahdp-datanode.pid
Yarn的pid命名规则:
pid=$YARN_PID_DIR/yarn-$YANR_IDENT_STRING-$command.pid
pid文件名:
/tmp/yarn-cdahdp-resourcemanager.pid
/tmp/yarn-cdahdp-nodemanager.pid
恢复这些pid文件即可使用stop-all.sh停止hadoop和yarn进程。

要根治这个问题,只需要在集群所有节点都设置$SPARK_PID_DIR, $HADOOP_PID_DIR和$YARN_PID_DIR即可。
修改hadoop-env.sh,增加:
export HADOOP_PID_DIR=/home/ap/cdahdp/app/pids
修改yarn-env.sh,增加:
export YARN_PID_DIR=/home/ap/cdahdp/app/pids
修改spark-env.sh,增加:
export SPARK_PID_DIR=/home/ap/cdahdp/app/pids
启动集群以后,查看/home/ap/cdahdp/app/pids目录,如下:

Spark集群无法停止的原因分析和解决的更多相关文章
- 解决Spark集群无法停止
执行stop-all.sh时,出现报错:no org.apache.spark.deploy.master.Master to stop,no org.apache.spark.deploy.work ...
- Spark Streaming揭秘 Day30 集群模式下SparkStreaming日志分析
Spark Streaming揭秘 Day30 集群模式下SparkStreaming日志分析 今天通过集群运行模式观察.研究和透彻的刨析SparkStreaming的日志和web监控台. Day28 ...
- Spark Streaming揭秘 Day31 集群模式下SparkStreaming日志分析(续)
Spark Streaming揭秘 Day31 集群模式下SparkStreaming日志分析(续) 今天延续昨天的内容,主要对为什么一个处理会分解成多个Job执行进行解析. 让我们跟踪下Job调用过 ...
- zhihu spark集群,书籍,论文
spark集群中的节点可以只处理自身独立数据库里的数据,然后汇总吗? 修改 我将spark搭建在两台机器上,其中一台既是master又是slave,另一台是slave,两台机器上均装有独立的mongo ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- Spark集群搭建中的问题
参照<Spark实战高手之路>学习的,书籍电子版在51CTO网站 资料链接 Hadoop下载[链接](http://archive.apache.org/dist/hadoop/core/ ...
- spark-2.2.0安装和部署——Spark集群学习日记
前言 在安装后hadoop之后,接下来需要安装的就是Spark. scala-2.11.7下载与安装 具体步骤参见上一篇博文 Spark下载 为了方便,我直接是进入到了/usr/local文件夹下面进 ...
- Spark集群数据处理速度慢(数据本地化问题)
SparkStreaming拉取Kafka中数据,处理后入库.整个流程速度很慢,除去代码中可优化的部分,也在spark集群中找原因. 发现: 集群在处理数据时存在移动数据与移动计算的区别,也有些其他叫 ...
- Spark集群-Standalone 模式
Spark 集群相关 table td{ width: 15% } 来源于官方, 可以理解为是官方译文, 外加一点自己的理解. 版本是2.4.4 本篇文章涉及到: 集群概述 master, worke ...
随机推荐
- ajax接收flask传递的json数据
from flask import Flask, request import json app = Flask(__name__) @app.route('/') def func(): res = ...
- [小北De编程手记] : Lesson 02 - Selenium For C# 之 核心对象
从这一篇开始,开始正式的介绍Selenium 以及相关的组件,本文的将讨论如下问题: Selenium基本的概念以及在企业化测试框架中的位置 Selenium核心对象(浏览器驱动) Web Drive ...
- flexviewer infowindow背景问题
flexiewer里遇到的一些问题 infoWindowRenderer问题 在arcgis api for flex中要设置infowindow的外观很容易,只需要在编写一下css文件即可,就如 e ...
- mysql游标的用法及作用
1当前有三张表A.B.C其中A和B是一对多关系,B和C是一对多关系,现在需要将B中A表的主键存到C中:常规思路就是将B中查询出来然后通过一个update语句来更新C表就可以了,但是B表中有2000多条 ...
- Glide实现查看图片和保存图片到手机
两种方式, 推荐方式一 方式一 downloadOnly 创建一个 ImageActivity public class ImageActivity extends AppCompatActivity ...
- dbms_randon package
reference to wbsite:http://zhangzhongjie.iteye.com/blog/1948930#comments DBMS_RANDON PACKAGE: Define ...
- AutoHotkey批量L版代码转H2的vim脚本
原脚本尽量用表达式的语法写,错误会比较少,比如"If a=", "fun(a=1)"这种语法在V2会出错文件放vim的autoload目录下,可使用以下map使 ...
- Hyperledger Fabric 1.0 学习搭建 (一)--- 基础环境搭建
1: 环境构建在本文中用到的宿主机环境是Centos ,版本为Centos.x86_64 7.2, 一定要用7版本以上, 要不然会安装出错. 通过Docker 容器来运行Fabric的节点,版本为v1 ...
- July 03rd 2017 Week 27th Monday
Even if you are on the right track, you will get run over if you just sit there. 即使你处于正确的轨道上,但如果你只是坐 ...
- SAP S/4HANA使用ABAP获得生产订单的状态
在S/4HANA里,我们如何根据一个销售订单的行项目,查看对应的生产订单状态? 双击行项目: 点击Schedule line: 这里就能看到生产订单的ID和状态了. 其中订单的状态存储在表vsaufk ...