Spark集群无法停止的原因分析和解决
今天想停止spark集群,发现执行stop-all.sh的时候spark的相关进程都无法停止。提示:
no org.apache.spark.deploy.master.Master to stop
no org.apache.spark.deploy.worker.Worker to stop
上网查了一些资料,再翻看了一下stop-all.sh,stop-master.sh,stop-slaves.sh,spark-daemon.sh,spark-daemons.sh等脚本,发现很有可能是由于$SPARK_PID_DIR的一个环境变量导致。
我搭建的是Hadoop2.6.0+Spark1.1.0+Yarn的集群。Spark、Hadoop和Yarn的停止,都是通过一些xxx.pid文件来操作的。以spark的stop-master为例,其中停止语句如下:

再查看spark-daemon.sh中的操作:
$SPARK_PID_DIR中存放的pid文件中,就是要停止进程的pid。其中$SPARK_PID_DIR默认是在系统的/tmp目录:
系统每隔一段时间就会清除/tmp目录下的内容。到/tmp下查看一下,果然没有相关进程的pid文件了。这才导致了stop-all.sh无法停止集群。
担心使用kill强制停止spark相关进程会破坏集群,因此考虑回复/tmp下的pid文件,再使用stop-all.sh来停止集群。
分析spark-daemon.sh脚本,看到pid文件命名规则如下:
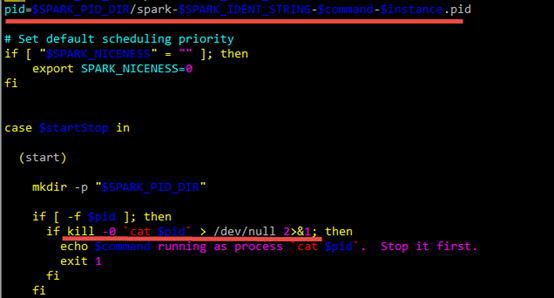
pid=$SPARK_PID_DIR/spark-$SPARK_IDENT_STRING-$command-$instance.pid
其中
$SPARK_PID_DIR是/tmp
$SPARK_IDENT_STRING是登录用户$USER,我的集群中用户名是cdahdp
$command是调用spark-daemon.sh时的参数,有两个:
org.apache.spark.deploy.master.Master
org.apache.spark.deploy.worker.Worker
$instance也是调用spark-daemon.sh时的参数,我的集群中是1
因此pid文件名如下:
/tmp/spark-cdahdp-org.apache.spark.deploy.master.Master-1.pid
/tmp/spark-cdahdp-org.apache.spark.deploy.worker.Worker-1.pid
通过jps查看相关进程的pid:
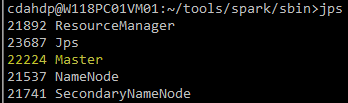
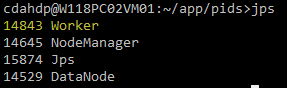
将pid保存到对应的pid文件即可。
之后调用spark的stop-all.sh,即可正常停止spark集群。
停止hadoop和yarn集群时,调用stop-all.sh,也会出现这个现象。其中NameNode,SecondaryNameNode,DataNode,NodeManager,ResourceManager等就是hadoop和yarn的相关进程,stop时由于找不到pid导致无法停止。分析方法同spark,对应pid文件名不同而已。
Hadoop的pid命名规则:
pid=$HADOOP_PID_DIR/hadoop-$HADOOP_IDENT_STRING-$command.pid
pid文件名:
/tmp/hadoop-cdahdp-namenode.pid
/tmp/hadoop-cdahdp-secondarynamenode.pid
/tmp/hadoop-cdahdp-datanode.pid
Yarn的pid命名规则:
pid=$YARN_PID_DIR/yarn-$YANR_IDENT_STRING-$command.pid
pid文件名:
/tmp/yarn-cdahdp-resourcemanager.pid
/tmp/yarn-cdahdp-nodemanager.pid
恢复这些pid文件即可使用stop-all.sh停止hadoop和yarn进程。

要根治这个问题,只需要在集群所有节点都设置$SPARK_PID_DIR, $HADOOP_PID_DIR和$YARN_PID_DIR即可。
修改hadoop-env.sh,增加:
export HADOOP_PID_DIR=/home/ap/cdahdp/app/pids
修改yarn-env.sh,增加:
export YARN_PID_DIR=/home/ap/cdahdp/app/pids
修改spark-env.sh,增加:
export SPARK_PID_DIR=/home/ap/cdahdp/app/pids
启动集群以后,查看/home/ap/cdahdp/app/pids目录,如下:

Spark集群无法停止的原因分析和解决的更多相关文章
- 解决Spark集群无法停止
执行stop-all.sh时,出现报错:no org.apache.spark.deploy.master.Master to stop,no org.apache.spark.deploy.work ...
- Spark Streaming揭秘 Day30 集群模式下SparkStreaming日志分析
Spark Streaming揭秘 Day30 集群模式下SparkStreaming日志分析 今天通过集群运行模式观察.研究和透彻的刨析SparkStreaming的日志和web监控台. Day28 ...
- Spark Streaming揭秘 Day31 集群模式下SparkStreaming日志分析(续)
Spark Streaming揭秘 Day31 集群模式下SparkStreaming日志分析(续) 今天延续昨天的内容,主要对为什么一个处理会分解成多个Job执行进行解析. 让我们跟踪下Job调用过 ...
- zhihu spark集群,书籍,论文
spark集群中的节点可以只处理自身独立数据库里的数据,然后汇总吗? 修改 我将spark搭建在两台机器上,其中一台既是master又是slave,另一台是slave,两台机器上均装有独立的mongo ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- Spark集群搭建中的问题
参照<Spark实战高手之路>学习的,书籍电子版在51CTO网站 资料链接 Hadoop下载[链接](http://archive.apache.org/dist/hadoop/core/ ...
- spark-2.2.0安装和部署——Spark集群学习日记
前言 在安装后hadoop之后,接下来需要安装的就是Spark. scala-2.11.7下载与安装 具体步骤参见上一篇博文 Spark下载 为了方便,我直接是进入到了/usr/local文件夹下面进 ...
- Spark集群数据处理速度慢(数据本地化问题)
SparkStreaming拉取Kafka中数据,处理后入库.整个流程速度很慢,除去代码中可优化的部分,也在spark集群中找原因. 发现: 集群在处理数据时存在移动数据与移动计算的区别,也有些其他叫 ...
- Spark集群-Standalone 模式
Spark 集群相关 table td{ width: 15% } 来源于官方, 可以理解为是官方译文, 外加一点自己的理解. 版本是2.4.4 本篇文章涉及到: 集群概述 master, worke ...
随机推荐
- 关于div设置display: inline-block之后盒子之间间距的处理
当两个盒子都设置display: inline-block之后并且css也清除了默认样式 这时候会发现div盒子之间仍然存在间隙 将font-size清0间距就会取消
- [ZOJ3316]:Game
题面 vjudge Sol 有一个棋盘,棋盘上有一些棋子,两个人轮流拿棋,第一个人可以随意拿,以后每一个人拿走的棋子与上一个人拿走的棋子的曼哈顿距离不得超过L,无法拿棋的人输,问后手能否胜利 首先距离 ...
- 广告点击率预测(CTR) —— 在线学习算法FTRL的应用
FTRL由google工程师提出,在13的paper中给出了伪代码和实现细节,paper地址:http://www.eecs.tufts.edu/~dsculley/papers/ad-click-p ...
- 初学Git和Github
一开始看到老师的作业,出于好奇打开看了一下教程链接,一脸懵逼.What is this???然后慢慢了解,自己百度琢磨这个陌生的git,Git是一款免费.开源的分布式版本控制系统.Github是一个代 ...
- CCF201409-1相邻数对
试题编号: 201409-1 试题名称: 相邻数对 时间限制: 1.0s 内存限制: 256.0MB 问题描述: 问题描述 给定n个不同的整数,问这些数中有多少对整数,它们的值正好相差1. 输入格式 ...
- C# mvc读取模板并修改上传到web
C# mvc读取模板并修改上传到web 后台: public FileResult GetXls() { FileStream fs = new FileStream(System.Web.HttpC ...
- devexpress chart 散点图加载并分组显示(可以自定义颜色 同组中的点颜色相同)
this.dChart.Diagram.Series.Clear();//清空图的内容 var groups = result.GroupBy(itm => itm["flag&quo ...
- QT样式
最近在写QT的UI 分享一个助手网页 http://doc.qt.io/qt-4.8/stylesheet-examples.html
- Redhat5.9安装qt5.5.1出错error while loading shared libraries:libX11-cxb.so.1 标签: qt5 2017-06-02 11
出错原因是缺少了共享库libX11-cxb.so.1,是由于系统版本过低所致:重新安装红帽6.5即可解决该问题.
- js函数 标签: javascript 2016-08-12 16:48 56人阅读 评论(0) 收藏
函数实际上是对象,函数名实际上也是一个指向函数对象的指针. 使用不带圆括号的函数名是访问函数指针,而非调用函数. 函数声明和函数表达式: alert(test(2,3)); function test ...