java过滤敏感词汇
前言
现在几乎所有的网站再发布带有文字信息的内容时都会要求过滤掉发动的、不健康的、影响社会安定的等敏感词汇,这里为大家提供了可以是现在这种功能的解决方案
第一种方式
- 创建敏感词汇文件;首先需要准备一个txt格式的文件用于存放需要过滤的敏感词汇,这个文件放到resources资源文件的根目录
代码如下
package com.xxxx.service;
import lombok.Data;
import org.springframework.stereotype.Service;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
/**
* 敏感词汇service
*
* @author
* @date
*/
@Data
@Service
public class SensitiveWordService {
private StringBuilder replaceAll;
/**
* 编码
* <P>
* 在读敏感词汇文件时需要用到
*/
private String encoding = "UTF-8";
/**
* 替换字符窜
* <P>
* 用于替换敏感词汇的字符窜
*/
private String replceStr = "*";
/**
*单次替换的敏感词汇的长度
*/
private int replceSize = 500;
/**
* 敏感词汇文件
* <P>
* 此文件放在资源文件的根目录下
*/
private String fileName = "censorwords.txt";
private List<String> arrayList;
/**
* 包含的敏感词列表,过滤掉重复项
*/
public Set<String> sensitiveWordSet;
/**
* 包含的敏感词列表,包括重复项,统计次数
*/
public List<String> sensitiveWordList;
/**
* 移除敏感词汇
*
* @param str 需要过滤的字符窜
*
* @return 过滤之后的字符窜
*/
public String removeSensitiveWord(String str){
SensitiveWordService sw = new SensitiveWordService("censorwords.txt");
sw.InitializationWork();
return sw.filterInfo(str);
}
/**
* 拦截信息
* <P>
* 过滤掉敏感词汇的方法
*
* @param str 将要被过滤信息
*
* @return 过滤后的信息
*/
public String filterInfo(String str) {
sensitiveWordSet = new HashSet<String>();
sensitiveWordList= new ArrayList<>();
StringBuilder buffer = new StringBuilder(str);
HashMap<Integer, Integer> hash = new HashMap<Integer, Integer>(arrayList.size());
String temp;
for(int x = 0; x < arrayList.size();x++) {
temp = arrayList.get(x);
int findIndexSize = 0;
for(int start = -1;(start=buffer.indexOf(temp,findIndexSize)) > -1;){
//System.out.println("###replace="+temp);
findIndexSize = start+temp.length();//从已找到的后面开始找
Integer mapStart = hash.get(start);//起始位置
//满足1个,即可更新map
if(mapStart == null || (mapStart != null && findIndexSize > mapStart)){
hash.put(start, findIndexSize);
//System.out.println("###敏感词:"+buffer.substring(start, findIndexSize));
}
}
}
Collection<Integer> values = hash.keySet();
for(Integer startIndex : values){
Integer endIndex = hash.get(startIndex);
//获取敏感词,并加入列表,用来统计数量
String sensitive = buffer.substring(startIndex, endIndex);
//System.out.println("###敏感词:"+sensitive);
if (!sensitive.contains("*")) {//添加敏感词到集合
sensitiveWordSet.add(sensitive);
sensitiveWordList.add(sensitive);
}
buffer.replace(startIndex, endIndex, replaceAll.substring(0,endIndex-startIndex));
}
hash.clear();
return buffer.toString();
}
/**
* 初始化敏感词库
*/
private void InitializationWork() {
replaceAll = new StringBuilder(replceSize);
for(int x=0;x < replceSize;x++)
{
replaceAll.append(replceStr);
}
//加载词库
arrayList = new ArrayList<String>();
InputStreamReader read = null;
BufferedReader bufferedReader = null;
try {
read = new InputStreamReader(SensitiveWordService.class.getClassLoader().getResourceAsStream(fileName),encoding);
bufferedReader = new BufferedReader(read);
for(String txt = null;(txt = bufferedReader.readLine()) != null;){
if(!arrayList.contains(txt))
arrayList.add(txt);
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
if(null != bufferedReader)
bufferedReader.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if(null != read)
read.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 测试方法
*
* @param args 参数
*/
public static void main(String[] args){
long startNumer = System.currentTimeMillis();
SensitiveWordService sw = new SensitiveWordService("censorwords.txt");
sw.InitializationWork();
//System.out.println("敏感词的数量:" + arrayList.size());
String str = "你好呀,我这里有敏感词汇,来过滤我呀";
System.out.println("被检测字符串长度:"+str.length());
str = sw.filterInfo(str);
long endNumber = System.currentTimeMillis();
//System.out.println("语句中包含敏感词的个数为:" + sensitiveWordSet.size() + "。包含:" + sensitiveWordSet);
//System.out.println("语句中包含敏感词的个数为:" + sensitiveWordList.size() + "。包含:" + sensitiveWordList);
System.out.println("总共耗时:"+(endNumber-startNumer)+"ms");
System.out.println("替换后的字符串为:\n"+str);
System.out.println("替换后的字符串长度为:\n"+str.length());
}
/**
* 有参构造
* <P>
* 文件要求路径在src或resource下,默认文件名为censorwords.txt
* @param fileName 词库文件名(含后缀)
*/
public SensitiveWordService(String fileName) {
this.fileName = fileName;
}
/**
* 有参构造
*
* @param replceStr 敏感词被转换的字符
* @param replceSize 初始转义容量
*/
public SensitiveWordService(String replceStr, int replceSize){
this.replceStr = fileName;
this.replceSize = replceSize;
}
/**
* 无参构造
*/
public SensitiveWordService(){
}
}
第二种方法
package com.xxxx.filters;
import java.io.IOException;
import java.io.InputStream;
import java.util.Enumeration;
import java.util.Properties;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 【匹配度可以,速度较慢】
* Java关键字过滤:http://blog.csdn.net/linfssay/article/details/7599262
* @author ShengDecheng
*
*/
public class KeyWordFilter {
private static Pattern pattern = null;
private static int keywordsCount = 0;
// 从words.properties初始化正则表达式字符串
private static void initPattern() {
StringBuffer patternBuffer = new StringBuffer();
try {
//words.properties
InputStream in = KeyWordFilter.class.getClassLoader().getResourceAsStream("keywords.properties");
Properties property = new Properties();
property.load(in);
Enumeration<?> enu = property.propertyNames();
patternBuffer.append("(");
while (enu.hasMoreElements()) {
String scontent = (String) enu.nextElement();
patternBuffer.append(scontent + "|");
//System.out.println(scontent);
keywordsCount ++;
}
patternBuffer.deleteCharAt(patternBuffer.length() - 1);
patternBuffer.append(")");
//System.out.println(patternBuffer);
// unix换成UTF-8
// pattern = Pattern.compile(new
// String(patternBuf.toString().getBytes("ISO-8859-1"), "UTF-8"));
// win下换成gb2312
// pattern = Pattern.compile(new String(patternBuf.toString()
// .getBytes("ISO-8859-1"), "gb2312"));
// 装换编码
pattern = Pattern.compile(patternBuffer.toString());
} catch (IOException ioEx) {
ioEx.printStackTrace();
}
}
private static String doFilter(String str) {
Matcher m = pattern.matcher(str);
// while (m.find()) {// 查找符合pattern的字符串
// System.out.println("The result is here :" + m.group());
// }
// 选择替换方式,这里以* 号代替
str = m.replaceAll("*");
return str;
}
public static void main(String[] args) {
long startNumer = System.currentTimeMillis();
initPattern();
//String str = "我日,艹,fuck,你妹的 干啥呢";
System.out.println("敏感词的数量:" + keywordsCount);
String str = "你好呀,我这里有敏感词汇,来过滤我呀";
System.out.println("被检测字符串长度:"+str.length());
str = doFilter(str);
//高效Java敏感词、关键词过滤工具包_过滤非法词句:http://blog.csdn.net/ranjio_z/article/details/6299834
//FilteredResult result = WordFilterUtil.filterText(str, '*');
long endNumber = System.currentTimeMillis();
System.out.println("总共耗时:"+(endNumber-startNumer)+"ms");
System.out.println("替换后的字符串为:\n"+str);
//System.out.println("替换后的字符串为:\n"+result.getFilteredContent());
//System.out.println("替换后的字符串为1:\n"+result.getOriginalContent());
//System.out.println("替换后的字符串为2:\n"+result.getBadWords());
}
}
敏感词汇文件keywords.properties
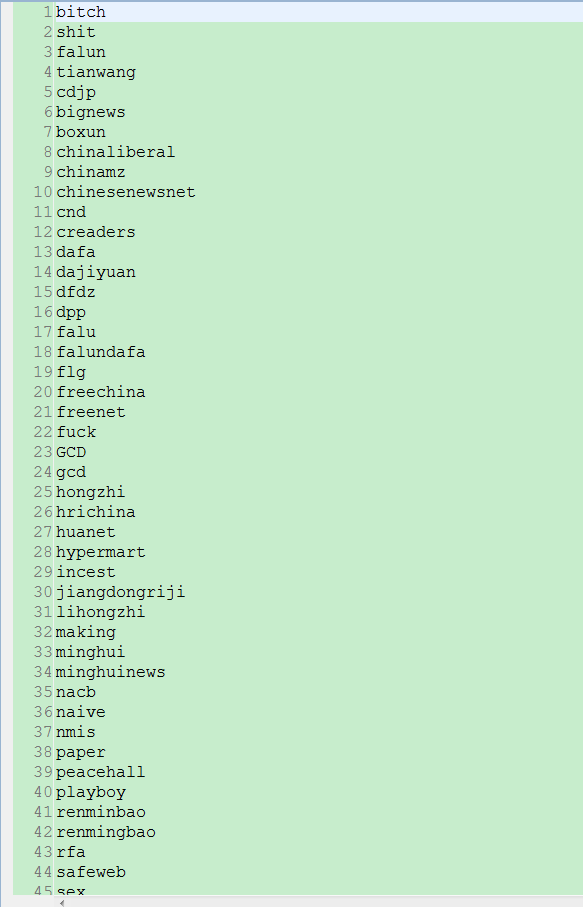

java过滤敏感词汇的更多相关文章
- Java过滤敏感词语/词汇---DFA算法
最近网站需要在评论.投稿等地方过滤敏感词汇,于是在网上查找了相关教程,特此整理分享. 关于DFA算法,详细的可以去http://blog.csdn.net/u013378306/article/det ...
- JavaWeb 过滤敏感词汇
提交的表单数据,常常要检查有没有敏感词汇,如果有,需要给出提示,或者替换为*. 检查.替换敏感词汇有3种常用的方式 (1)在Servlet中操作. (2)在Filter中先检查.如果要替换敏感词汇,r ...
- Filter - 过滤敏感词汇(动态代理)
/** * 敏感词汇过滤器 */ @WebFilter("/*") public class SensitiveWordsFilter implements Filter { pu ...
- PHP+Ajax判断是否有敏感词汇
本文讲述如何使用PHP和Ajax创建一个过滤敏感词汇的方法,判断是否有敏感词汇. 敏感词汇数组sensitive.php return array ( 0 => '111111', 1 => ...
- JavaWeb 之 Filter 敏感词汇过滤案例
需求: 1. 对day17_case案例录入的数据进行敏感词汇过滤 2. 敏感词汇参考 src路径下的<敏感词汇.txt> 3. 如果是敏感词汇,替换为 *** 分析: 1. 对reque ...
- java实现敏感词过滤(DFA算法)
小Alan在最近的开发中遇到了敏感词过滤,便去网上查阅了很多敏感词过滤的资料,在这里也和大家分享一下自己的理解. 敏感词过滤应该是不用给大家过多的解释吧?讲白了就是你在项目中输入某些字(比如输入xxo ...
- Java实现敏感词过滤
敏感词.文字过滤是一个网站必不可少的功能,如何设计一个好的.高效的过滤算法是非常有必要的.前段时间我一个朋友(马上毕业,接触编程不久)要我帮他看一个文字过滤的东西,它说检索效率非常慢.我把它程序拿过来 ...
- Java实现敏感词过滤(转)
敏感词.文字过滤是一个网站必不可少的功能,如何设计一个好的.高效的过滤算法是非常有必要的.前段时间我一个朋友(马上毕业,接触编程不久)要我帮他看一个文字过滤的东西,它说检索效率非常慢.我把它程序拿过来 ...
- Java实现敏感词过滤 - IKAnalyzer中文分词工具
IKAnalyzer 是一个开源的,基于java语言开发的轻量级的中文分词工具包. 官网: https://code.google.com/archive/p/ik-analyzer/ 本用例借助 I ...
随机推荐
- DataGridView导出到Word
#region 使用Interop.Word.dll将DataGridView导出到Word /// <summary> /// 使用Interop.Word.dll将DataGridVi ...
- chrome最小字体12px如何修改
在html标记样式里加入 <style> html { -webkit-text-size-adjust:none } </style> 这样的方式可以设置chrome字体小于 ...
- 阅读关于DuReader:百度大规模的中文机器阅读理解数据集
很久之前就得到了百度机器阅读理解关于数据集的这篇文章,今天才进行总结!.... 论文地址:https://arxiv.org/abs/1711.05073 自然语言处理是人工智能皇冠上的明珠,而机器阅 ...
- Centos 7 安装jdk1.7
在linux中安装jdk是很平凡的事情了,刚学习linux给自己留下一笔记.刚安装centos其中可以会附带jdk,但是这并不影响,只要下载自己的jdk然后替换相对应的环境变量即可. 1.下载相对应的 ...
- Centos修改镜像为国内的阿里云源或者163源等国内源
阿里安装软件镜像源 阿里云Linux安装镜像源地址:http://mirrors.aliyun.com/ 第一步:备份你的原镜像文件,以免出错后可以恢复. mv /etc/yum.repos.d/Ce ...
- 測試 battery capacity curve 的負載
昨天有同事問說, 他要測試 battery capacity curve, 並且負載要使用 33mA, 於是我想到有一個 apk 名稱為 快速放電 (最下方),可以控制 cpu 的 load, 他試了 ...
- uoj#35 后缀排序(后缀数组模版)
#include<bits/stdc++.h> #define N 100005 using namespace std; char s[N]; int a[N],c[N],t1[N],t ...
- 2017多校第6场 HDU 6105 Gameia 博弈
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6105 题意:Alice和Bob玩一个游戏,喷漆!现在有一棵树上边的节点最开始都没有被染色.游戏规则是: ...
- IoT之车联网
一. 背景 这是一个笔者在实习公司策划的关于车联网的小项目,也是笔者参加某竞赛的作品<基于云平台的车内滞留儿童状况监测与处理>,本项目旨在为因各种原因导致儿童滞留车内热死.闷死的社会性事件 ...
- C#调用Excel报 error CS1969: 找不到编译动态表达式所需的一个或多个类型。是否缺少引用?
转自[http://blog.csdn.net/bodybo/article/details/43191319] 程序需要读取Exel文件,有如下代码段 object oMissing = Syste ...