Stanford机器学习笔记-1.线性回归
Content:
1. Linear Regression
1.1 Linear Regression with one variable
1.1.1 Gradient descent algorithm
1.2 Linear Regression with multiple variable
1.2.1 Feature Scaling
1.2.2 Features and polynomial regression
1.2.3 Normal equation
1.2.4 Probalilistic interpretation for cost function
key words: Linear Regression, Gradient Descent, Learning Rate, Feature Scaling, Normal Equation
1. Linear Regression
1.1 Linear Regression with one variable
某个目标量可能由一个或多个变量决定,单变量线性回归就是我们仅考虑一个变量与目标量的关系。例如,我们可以仅考虑房子的面积X与房价y的关系,如下图。
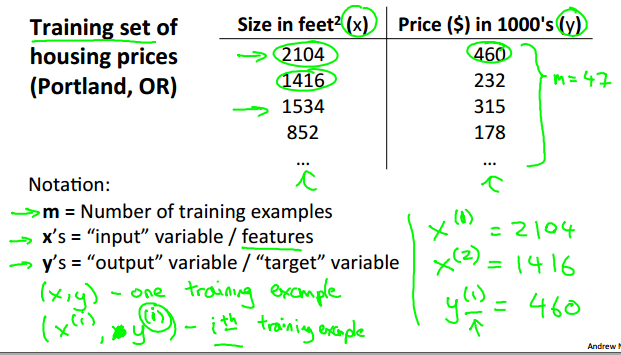
通常将已有的可利用的数据成为data set or training set。
首先我们定义出线性的hypothesis function h,然后定义出cost function J,为了使得假设函数接近或等于实际值,目标是使得函数J取最小值。
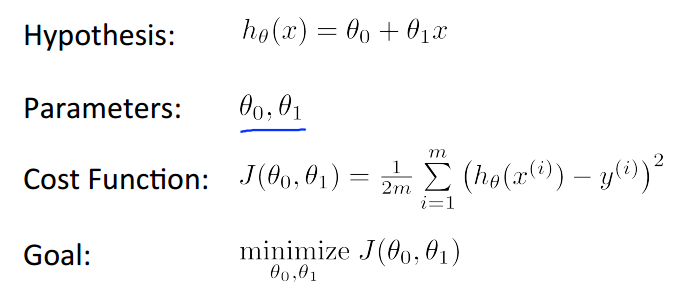
1.1.1 Gradient descent algorithm (梯度下降法)
梯度下降法可以求解线性回归问题,具体描述如下:

函数J是一个二元函数,为使得取最小值,分别对求偏导数,得到对应的变化率。然后,设定一个合适的learning rate,对theta进行更新。更新策略如下:

注意更新要同步,否则前一个theta0会影响后一个theta1更新(通过影响cost function : J)
其中对J函数求偏导数如下:
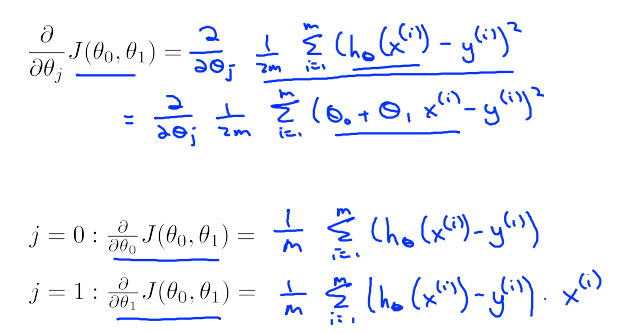
带入得:

迭代次数和learning rate是影响梯度下降法是否成功收敛到最优值的重要因素。
- 迭代次数:
- 过少可能使得算法还没有收敛就停止,
- 过多导致资源(时间等)的浪费;
- learning rate:
- 过小,使得每次迭代时theta的变化量过小,从而算法收敛过慢,换言之需要增加迭代次数使得算法收敛;
- 过大,使得每次迭代时theta的变化量过大,可能在变化(迭代)过程中越过最优(收敛)点。直观地:
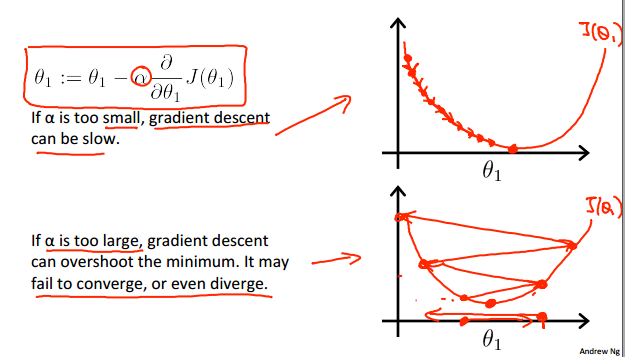

正常的收敛应大致如下:

1.2 Linear Regression with multiple variables
在实际生活中,一个量通常受很多变量的影响。同样以房价为例:
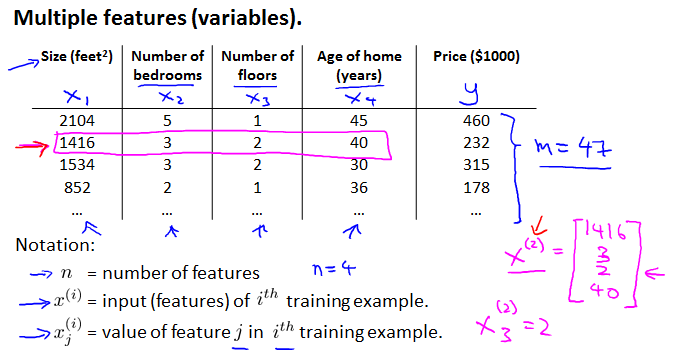
此时相应的量(函数)有如下变化:theta从2维变成了n+1维向量;从而hypothesis function为下图所示(注意定义x0=1的小细节):
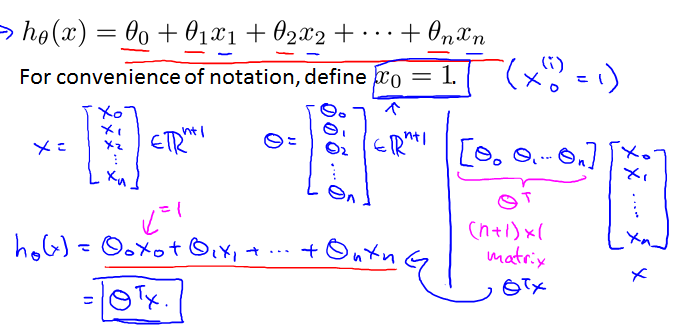
同样的,可以用梯度下降法来解决多变量线性回归问题。

注意与单变量线性回归对应的变化和联系。事实上,单变量线性回归是多变量线性回归的特殊情况(n=1)。

1.2.1 Feature Scaling(数据规范化)
不同的特征量由于单位不同,可能在数值上相差较大,Feature Scaling可以去量纲,减少梯度下降法的迭代次数,提高速度,所以在算法执行前通常需要Feature Scaling。直观上来说,考虑两个特征量,规范化前的椭圆很瘪,可能导致收敛的路径变长,数据规范化后使得椭圆较均匀,缩短收敛路径,如下:
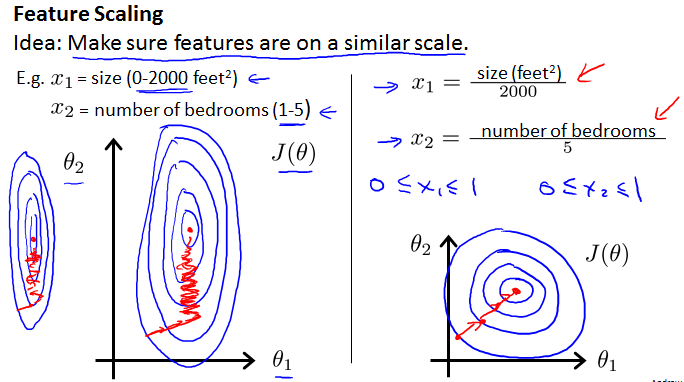
下面给出一种规范化策略:
- 求每个特征量X的平均值mean
- 求每个特征量X的标准差segma (matlab中std()函数)
- 规范化:X = (X-mean) / sigma

1.2.2 Features and polynomial regression
有时候,我们可以将某些特征量联合成一个新的特征量或许可以得到更好的结果,例如要预测房价,考虑到房价主要由area决定,不妨将特征量frontage和depth联合成一个新的特征量area.
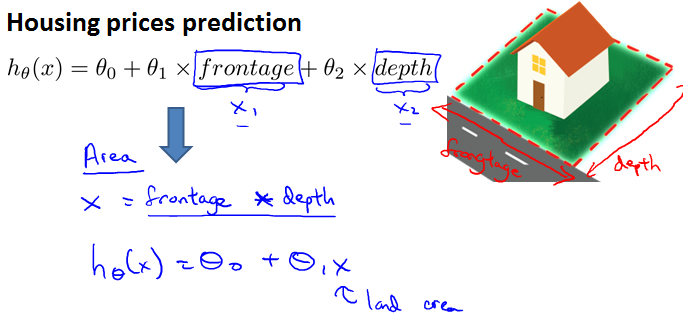
对于有些情况,线性回归的结果可能不是很理想,可以考虑多项式回归。注意应该结合实际考虑选择几次的多项式,例如下面的例子,特征量是size,目标量是price,所以就不应该选择二次多项式,否则会出现size增大而price变小的情况,不符合实际情况。
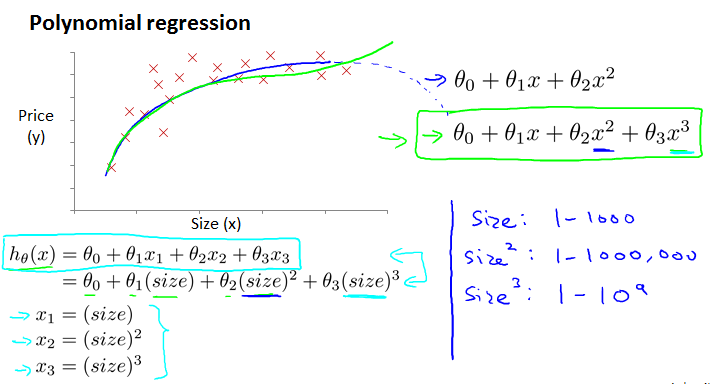
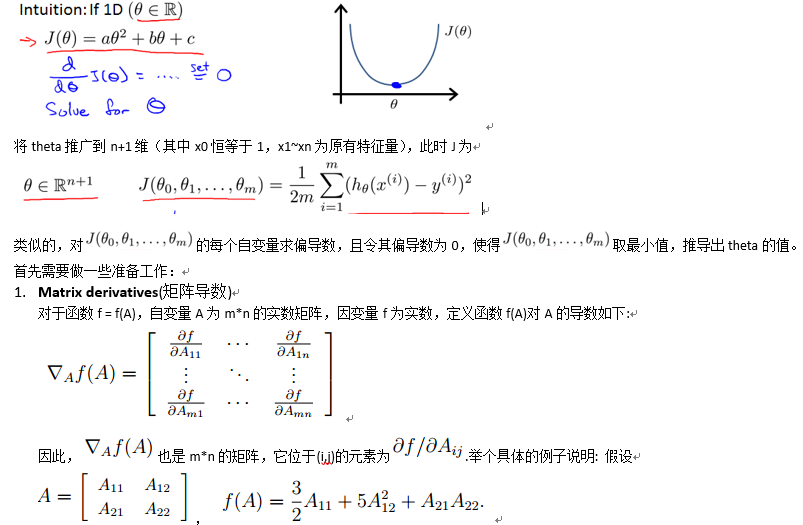
1.2.3 Normal equation(正则方程)
Normal equation: Method to solve for analytically.
首先考虑cost function J的自变量theta为一维的情况,这时的J为关于theta的一元二次函数,可以直接求导得到最小值点,如下图所示:




下面对Gradient Descent 和 Normal Equation做一下比较
- m = 20000, n = 10000,优先考虑Gradient Descent
- m = 20000, n = 10, 优先考虑Normal Equation

1.2.4 Probalilistic interpretation for cost function



参考:https://www.coursera.org/learn/machine-learning/
Stanford机器学习笔记-1.线性回归的更多相关文章
- coursera机器学习笔记-多元线性回归,normal equation
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- Stanford机器学习笔记-10. 降维(Dimensionality Reduction)
10. Dimensionality Reduction Content 10. Dimensionality Reduction 10.1 Motivation 10.1.1 Motivation ...
- Stanford机器学习笔记-9. 聚类(Clustering)
9. Clustering Content 9. Clustering 9.1 Supervised Learning and Unsupervised Learning 9.2 K-means al ...
- Stanford机器学习笔记-6. 学习模型的评估和选择
6. 学习模型的评估与选择 Content 6. 学习模型的评估与选择 6.1 如何调试学习算法 6.2 评估假设函数(Evaluating a hypothesis) 6.3 模型选择与训练/验证/ ...
- Stanford机器学习笔记-9. 聚类(K-means算法)
9. Clustering Content 9. Clustering 9.1 Supervised Learning and Unsupervised Learning 9.2 K-means al ...
- Stanford机器学习笔记-8. 支持向量机(SVMs)概述
8. Support Vector Machines(SVMs) Content 8. Support Vector Machines(SVMs) 8.1 Optimization Objection ...
- Stanford机器学习笔记-7. Machine Learning System Design
7 Machine Learning System Design Content 7 Machine Learning System Design 7.1 Prioritizing What to W ...
- Stanford机器学习笔记-5.神经网络Neural Networks (part two)
5 Neural Networks (part two) content: 5 Neural Networks (part two) 5.1 cost function 5.2 Back Propag ...
- Stanford机器学习笔记-4. 神经网络Neural Networks (part one)
4. Neural Networks (part one) Content: 4. Neural Networks (part one) 4.1 Non-linear Classification. ...
随机推荐
- FreeBSD10上编译尝试DeepIn UI
经历了两百多次命令的输入尝试,终于搞定. 1 git clone https://github.com/linuxdeepin/deepin-ui.git 11 git clone https://g ...
- cppcheck
http://sourceforge.net/projects/cppcheck/files/?source=navbar https://github.com/danmar/cppcheck htt ...
- vim 正则替换
http://www.cppblog.com/kefeng/archive/2010/10/20/130574.html Vim中的正则表达式功能很强大,如果能自由运用,则可以完成很多难以想象的操作. ...
- Servlet-Jsp
Jsp实际就是Servlet. 我们访问Http://localhost:8080/Web/index.jsp的流程: 1 [jsp文件名].jsp转义为[jsp文件名_jsp].java,文件存储在 ...
- JMS学习(一)基本概念
这两天面试了一两个公司,由于简历中的最近一个项目用到了JMS,然而面试官似乎对这个很感兴趣,所以都被问到了,但可惜的是,我除了说我们使用了JMS外,面对他们提出的一些关于JMS的问题,我回答得相当差, ...
- 利用jquery实现网页禁止鼠标右键、禁止复制
很多时候,网站的内容辛苦写法被轻松复制,为了不让自己的劳动成果外流,可以利用禁止鼠标右键等方式保护自己的原创内容! 方式1:禁止鼠标右键操作 <script src="http://l ...
- R语言-神经网络包RSNNS
code{white-space: pre;} pre:not([class]) { background-color: white; }if (window.hljs && docu ...
- nodeJS中npm常见的命令
常用的nodeJS中npm的命令:npm主要是node包管理和发布的工具.npm常用的命令:1:npm install <name> //(下载包) 下载后的包放在当前路径下面 npm i ...
- 通过sftp实现文件分发功能
1 环境: 分发服务器:ubuntu server 64bit,192.168.56.22 接受服务器:windows server 2008,192.168.56.102 2 ...
- SparseArray<E>详解
SparseArray<E> 是官方推荐的用来替代 HashMap<Integer, E> 的一个工具类,相比来说有着更好的性能(其核心是折半查找函数(binarySearch ...