python+selenium+unittest,爬虫电影网站
以前经常在这个网站上下载电影下来看,这个网站比较坑的就是,主页上只有电影的名称,但是评分是看不到的;只有再点击电影名字,进入电影主页时才能看到评分。一般下载的电影都是评分高的才看,低的就忽略掉了。每次都要来回去看评分,太麻烦了。So,我就写了一个小小的爬虫,暂时就叫爬虫好了。
在脚本中使用的是:python2.7 + selenium + unittest + chrome(其实我想用phantomjs的,但是在抓取评分的时候,老是抓取不到,好像是js搞的鬼)
其实流程很简单:1、进入主页获取电影的title和url,2、根据获取的url,获取该电影的评分score,3、保存结果到本地文件中
1、进入主页获取电影的title和url
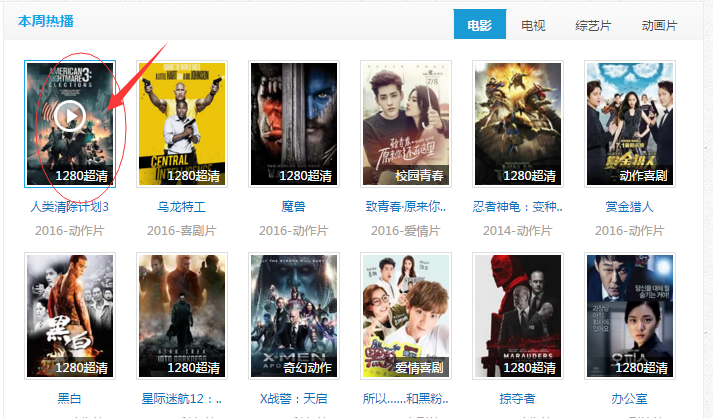
2、根据获取的url,获取该电影的评分score
下面我就逐步分解:
首先,进入该网站的主页,利用webdriver来定位电影,然后获取所有电影的属性:title,url,使用的定位是css
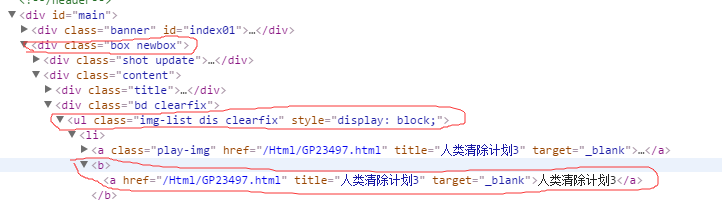
def geturl(self): # 该函数是获取首页的电影的 title 和 url
self.dr.get('http://www.xiamp4.com') # 网站首页
urls = [] # 存放结果的list
eles = self.dr.find_elements_by_css_selector('div.box.newbox ul.img-list.dis.clearfix b a') # 定位满足条件的所有电影,css定位
for ele in eles:
tmp = dict()
url = ele.get_attribute('href') # 获取电影的url
title = ele.get_attribute('title') # 获取电影的title
tmp['url'] = url
tmp['title'] = title
urls.append(tmp) # 将电影的title和url放在一个字典中,然后添加到 urls中
return urls
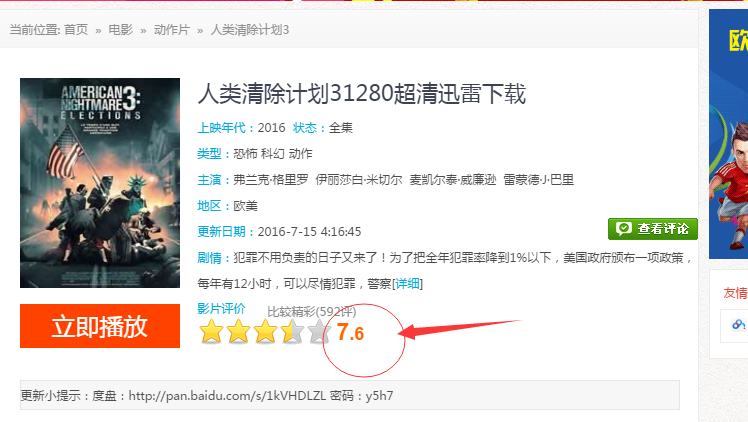
2、根据获取的url,获取该电影的评分score

def getscore(self, url):
# url = 'http://www.xiamp4.com/Html/GP23161.html'
self.dr.get(url) # 进入电影的页面
time.sleep(2)
ele = self.dr.find_element_by_css_selector('input#MARK_B2') # 定位评分的元素
score = ele.get_attribute('value') # 获取元素value的值
# print score
return score # 该函数的左右就是 根据参数电影的url,返回该电影的评分
下面是最终的代码:
#coding=utf-8 from selenium import webdriver
import unittest
import time class Spider(unittest.TestCase):
def setUp(self):
print '####################### Start #######################'
self.dr = webdriver.Chrome()
self.dr.implicitly_wait(10) def tearDown(self):
self.dr.close()
print '####################### End #######################' def geturl(self):
self.dr.get('http://www.xiamp4.com')
urls = []
eles = self.dr.find_elements_by_css_selector('div.box.newbox ul.img-list.dis.clearfix b a')
for ele in eles:
tmp = dict()
url = ele.get_attribute('href')
title = ele.get_attribute('title')
tmp['url'] = url
tmp['title'] = title
urls.append(tmp)
return urls def getscore(self, url):
# url = 'http://www.xiamp4.com/Html/GP23161.html'
self.dr.get(url)
time.sleep(2)
ele = self.dr.find_element_by_css_selector('input#MARK_B2')
score = ele.get_attribute('value')
# print score
return score def test_run(self):
moves = self.geturl()
# print len(moves)
for move in moves:
move['score'] = self.getscore(move['url'])
try:
if len(moves) > 0:
with open('MoveMessage.txt', 'a') as f:
f.write('####################### Start #######################' + '\n')
for move in moves:
tmp = 'MoveName: %s\t,MoveScore: %s\t,MoveUrl: %s' % (move['title'],move['score'],move['url'])
print tmp
with open('MoveMessage.txt', 'a') as f:
f.write(tmp.encode('utf-8') + '\n')
with open('MoveMessage.txt', 'a') as f:
f.write('####################### End #######################' + '\n')
except Exception,e:
print 'Not found moves!',e if __name__ == '__main__':
unittest.main()
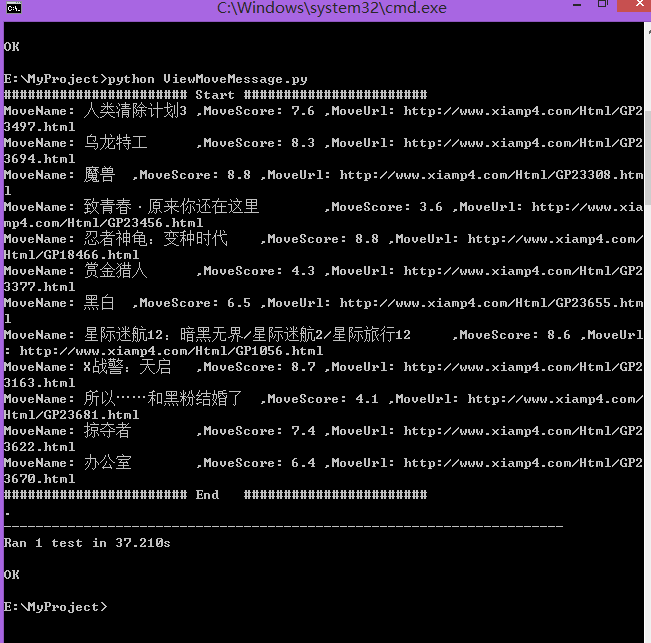
运行的最终结果:

python+selenium+unittest,爬虫电影网站的更多相关文章
- Python+selenium+unittest+HTMLTestReportCN单元测试框架分享
分享一个比较基础的,系统性的知识点.Python+selenium+unittest+HTMLTestReportCN单元测试框架分享 Unittest简介 unittest是Python语言的单元测 ...
- Python+Selenium+Unittest+Ddt+HTMLReport分布式数据驱动自动化测试框架结构
1.Business:公共业务模块,如登录模块,可以把登录模块进行封装供调用 ------login_business.py from Page_Object.Common_Page.login_pa ...
- python+selenium +unittest生成HTML测试报告
python+selenium+HTMLTestRunner+unittest生成HTML测试报告 首先要准备HTMLTestRunner文件,官网的HTMLTestRunner是python2语法写 ...
- 【爬虫】如何用python+selenium网页爬虫
一.前提 爬虫网页(只是演示,切勿频繁请求):https://www.kaola.com/ 需要的知识:Python,selenium 库,PyQuery 参考网站:https://selenium- ...
- Python Selenium unittest+HTMLTestRunner实现 自动化测试及发送测试报告邮件
1.UI测试框架搭建-目录结构 2. 文件介绍 2.1.baseinfo->__init__.py 配置文件定义基础参数 #-*-coding:utf-8-*- #测试用例配置参数 base_u ...
- python selenium --unittest 框架
转自:http://www.cnblogs.com/fnng/p/3300788.html 学习unittest 很好的一个切入点就是从selenium IDE 录制导出脚本.相信不少新手学习sele ...
- python + selenium + unittest 自动化测试框架 -- 入门篇
. 预置条件: 1. python已安装 2. pycharm已安装 3. selenium已安装 4. chrome.driver 驱动已下载 二.工程建立 1. New Project:建立自己的 ...
- Python+Selenium ----unittest单元测试框架
unittest是一个单元测试框架,是Python编程的单元测试框架.有时候,也做叫做“PyUnit”,是Junit的Python语言版本.这里了解下,Junit是Java语言的单元测试框架,Java ...
- windiows下搭建python+selenium+unittest+Chrome的Web自动化环境
一.selenium.unittest概念 Selenium 是用于测试 Web 应用程序用户界面 (UI) 的常用框架.它是一款用于运行端到端功能测试的超强工具.您可以使用多个编程语言编写测试,并且 ...
随机推荐
- 用于主题检测的临时日志(b2d5c7b3-e3f6-4b0f-bfa4-a08e923eda9b - 3bfe001a-32de-4114-a6b4-4005b770f6d7)
这是一个未删除的临时日志.请手动删除它.(1c773d57-4f35-40cf-ad62-bd757d5fcfae - 3bfe001a-32de-4114-a6b4-4005b770f6d7)
- liunx 服务内存消耗100% 怎么处理
一.排查问题 查看内存使用 free 查看进程使用存储状况.看是不是业务进程在消耗存储,如果是就要优化业务代码了 使用top 命令 如果不是怎么办 二.处理办法 1.把没有用到的消耗内存的服务进程 ...
- 地铁沉降观测数据分析之巧用VBA编程处理
地铁沉降观测数据分析之巧用VBA编程处理 当你观测了一天累的要死了,回来看着成百上千的测量数据,还要做报表.如果是三五页报表还好说,如果是2000个点的报表 按照一页纸张报30个点就得大约70页的报表 ...
- [译] 一、为何要推出AppCoda系列?
声明:本文翻译自AppCoda网站的文章:Why Launching AppCoda?,作者是创建者Simon Ng.如有异议,请联系博主. 去年九月份,我在App Store上发布了自己第一个iPh ...
- ASP.NET MVC应用require.js实践
这里有更好的阅读体验和及时的更新:http://pchou.info/javascript/asp.net/2013/11/10/527f6ec41d6ad.html Require.js是一个支持j ...
- GPL与LGPL的区别
GPL(GNU General Public License) 我们很熟悉的Linux就是采用了GPL.GPL协议和BSD, Apache Licence等鼓励代码重用的许可很不一样.GPL的出发点 ...
- iOS:缓存与Operation优先级问题
这篇博客来源于今年的一个面试题,当我们使用SDWebImgae框架中的sd_setImageWithURL: placeholderImage:方法在tableView或者collectionView ...
- android 内置视频目录
在做引导界面的时候有一个视频文件, 把它放在res/raw目录下面. 引用方法 如下: videoView = (VideoView) findViewById(R.id.video_view); v ...
- RedRabbit——基于BrokerPattern服务器框架
RedRabbit 经典网游服务器架构 该图省略了专门用途的dbserver.guildserver等用于专门功能的server,该架构的优点有: l LoginGate相当于DNS,可以动态的保证G ...
- [转]ASP.NET页面之间传递值的几种方式
页面传值是学习asp.net初期都会面临的一个问题,总的来说有页面传值.存储对象传值.ajax.类.model.表单等.但是一般来说,常用的较简单有QueryString,Session,Cookie ...