switch...case...语句分析(大表跟小表何时产生)
一、switch...case...的格式
switch(表达式)
{
case 常量表达式1:
语句;
break;
case 常量表达式2:
语句;
break;
case 常量表达式3:
语句;
break;
case 常量表达式3:
语句;
break;
default:
语句;
break;
}
switch要求:
1、case后面必须是常量表达式
2、case后常量表达式的值不能一样
3、switch后面表达式必须为整数,不能为浮点数
4、case后的语句可以有多个且不用花括号括起来;
5、case和default子句的先后顺序可以先后变动,default子句可以省略不用;
二、switch...case...与if...else...的区别
1、switch语句 是if语句的简写,我们可以看一下分析,
void Function(int m)
{
if (m == )
{
printf("%d\n", );
}
else if (m == )
{
printf("%d\n", );
}
else if (m == )
{
printf("%d\n", );
}
else if (m == )
{
printf("%d\n", );
}
else if (m == )
{
printf("%d\n", );
}
} int main(int argc, char* argv[])
{
Function();
return ;
}
反汇编代码如下
push ebp
mov ebp,esp
sub esp,40h
push ebx
push esi
push edi
lea edi,[ebp-40h]
0040102C mov ecx,10h
mov eax,0CCCCCCCCh
rep stos dword ptr [edi]
cmp dword ptr [ebp+],
0040103C jne Function+2Fh (0040104f)
0040103E push
push offset string "%d\n" (0042201c)
call printf ()
0040104A add esp,
0040104D jmp Function+89h (004010a9)
0040104F cmp dword ptr [ebp+],
jne Function+46h ()
push
push offset string "%d\n" (0042201c)
0040105C call printf ()
add esp,
jmp Function+89h (004010a9)
cmp dword ptr [ebp+],
0040106A jne Function+5Dh (0040107d)
0040106C push
0040106E push offset string "%d\n" (0042201c)
call printf ()
add esp,
0040107B jmp Function+89h (004010a9)
0040107D cmp dword ptr [ebp+],
jne Function+74h ()
push
push offset string "%d\n" (0042201c)
0040108A call printf ()
0040108F add esp,
jmp Function+89h (004010a9)
cmp dword ptr [ebp+],
jne Function+89h (004010a9)
0040109A push
0040109C push offset string "%d\n" (0042201c)
004010A1 call printf ()
004010A6 add esp,
004010A9 pop edi
004010AA pop esi
004010AB pop ebx
004010AC add esp,40h
004010AF cmp ebp,esp
004010B1 call __chkesp (004011d0)
004010B6 mov esp,ebp
004010B8 pop ebp
004010B9 ret
下面来一段相同功能的switch语句,再观察反汇编
#include "stdafx.h" void Function(int m)
{
switch (m)
{
case :
printf("1\n");
break;
case :
printf("2\n");
break;
case :
printf("3\n");
break;
default:
printf("Error!\n");
break;
}
} int main(int argc, char* argv[])
{
Function();
return ;
}
反汇编代码如下
push ebp
mov ebp,esp
sub esp,44h
push ebx
push esi
push edi
lea edi,[ebp-44h]
0040102C mov ecx,11h
mov eax,0CCCCCCCCh
rep stos dword ptr [edi]
mov eax,dword ptr [ebp+]
0040103B mov dword ptr [ebp-],eax
0040103E cmp dword ptr [ebp-],
je Function+32h ()
cmp dword ptr [ebp-],
je Function+41h ()
0040104A cmp dword ptr [ebp-],
0040104E je Function+50h ()
jmp Function+5Fh (0040107f)
push offset string "1\n" (00422f54)
call printf ()
0040105C add esp,
0040105F jmp Function+6Ch (0040108c)
push offset string "4\n" (0042212c)
call printf ()
0040106B add esp,
0040106E jmp Function+6Ch (0040108c)
push offset string "5\n" (0042201c)
call printf ()
0040107A add esp,
0040107D jmp Function+6Ch (0040108c)
0040107F push offset string "Error!\n" (00422fa4)
call printf ()
add esp,
0040108C pop edi
0040108D pop esi
0040108E pop ebx
0040108F add esp,44h
cmp ebp,esp
call __chkesp (004011d0)
mov esp,ebp
0040109B pop ebp
0040109C ret
观察反汇编代码可以看到,此时判定状态差别不大,均是cmp,jmp
三、switch语句大表的产生
1、基于上例子的基础上,添加case后面的值,一个一个增加,观察反汇编代码的变化(何时生成大表).
上个例子中,switch语句中,只有3个分支,我们增加一个case看看
#include "stdafx.h" void Function(int m)
{
switch (m)
{
case :
printf("1\n");
break;
case :
printf("2\n");
break;
case :
printf("3\n");
break;
case :
printf("4\n");
break;
default:
printf("Error!\n");
break;
}
} int main(int argc, char* argv[])
{
Function();
return ;
}
push ebp
mov ebp,esp
sub esp,44h
push ebx
push esi
push edi
lea edi,[ebp-44h]
0040102C mov ecx,11h
mov eax,0CCCCCCCCh
rep stos dword ptr [edi]
mov eax,dword ptr [ebp+]
0040103B mov dword ptr [ebp-],eax
0040103E mov ecx,dword ptr [ebp-]
sub ecx,
mov dword ptr [ebp-],ecx
cmp dword ptr [ebp-],
0040104B ja $L539+0Fh ()
0040104D mov edx,dword ptr [ebp-]
jmp dword ptr [edx*+4010B1h]
$L533:
push offset string "1\n" ()
0040105C call printf ()
add esp,
jmp $L539+1Ch (004010a0)
$L535:
push offset string "2\n" ()
0040106B call printf ()
add esp,
jmp $L539+1Ch (004010a0)
$L537:
push offset string "3\n" (0042202c)
0040107A call printf ()
0040107F add esp,
jmp $L539+1Ch (004010a0)
$L539:
push offset string "4\n" ()
call printf ()
0040108E add esp,
jmp $L539+1Ch (004010a0)
push offset string "Error!\n" (0042201c)
call printf ()
0040109D add esp,
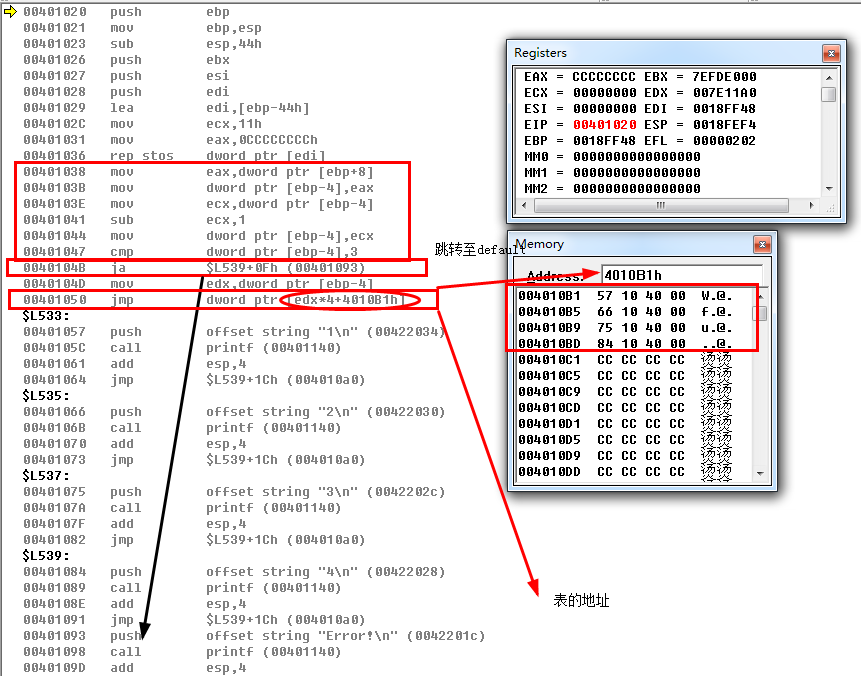
00401038 mov eax,dword ptr [ebp+8] //将参数m放置eax
0040103B mov dword ptr [ebp-4],eax //将eax的值给到局部变量ebp-4
0040103E mov ecx,dword ptr [ebp-4] //局部变量的值给ecx
00401041 sub ecx,1 //ecx的值减去case中最小的常量值
00401044 mov dword ptr [ebp-4],ecx //再将ecx的值给局部变量,此时ecx的值为2
00401047 cmp dword ptr [ebp-4],3 //将局部变量m与3比较,以至于为什么是跟3比较呢?首先会有一张表,这个表记录了每个case分支的函数地址,这个表的首地址是以最下的case + 常量值为首,如果超过这个表,那么则都跳转至default处
0040104B ja $L539+0Fh (00401093) //如果高于等于的话,函数则跳转至0x00401096地址处,这个地址其实就是default的位置
0040104D mov edx,dword ptr [ebp-4] //将局部变量ebp-4,m的值赋给edx
00401050 jmp dword ptr [edx*4+4010B1h] //大表根据这个差值来跳转值那个函数地址
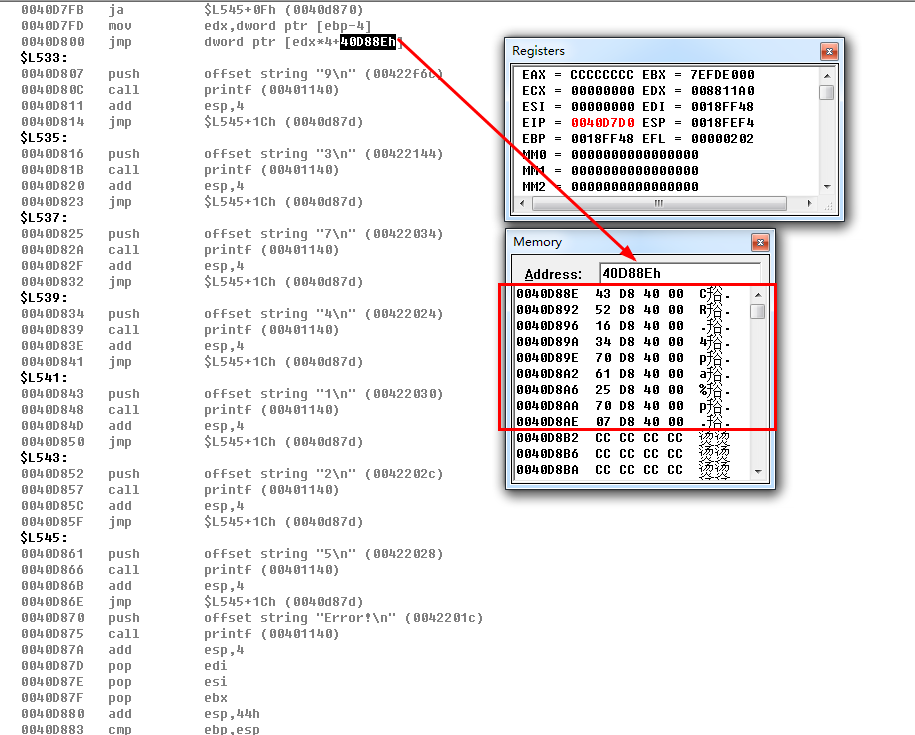
2、将1中的常量值的顺序打乱,观察反汇编代码(观察顺序是否会影响生成大表).
为了方便,我增加几句case
#include "stdafx.h" void Function(int m)
{
switch (m)
{
case :
printf("9\n");
break;
case :
printf("3\n");
break;
case :
printf("7\n");
break;
case :
printf("4\n");
break;
case :
printf("1\n");
break;
case :
printf("2\n");
break;
case :
printf("6\n");
break;
default:
printf("Error!\n");
break;
}
} int main(int argc, char* argv[])
{
Function();
return ;
}
0040D7D0 push ebp
0040D7D1 mov ebp,esp
0040D7D3 sub esp,44h
0040D7D6 push ebx
0040D7D7 push esi
0040D7D8 push edi
0040D7D9 lea edi,[ebp-44h]
0040D7DC mov ecx,11h
0040D7E1 mov eax,0CCCCCCCCh
0040D7E6 rep stos dword ptr [edi]
0040D7E8 mov eax,dword ptr [ebp+]
0040D7EB mov dword ptr [ebp-],eax
0040D7EE mov ecx,dword ptr [ebp-]
0040D7F1 sub ecx,
0040D7F4 mov dword ptr [ebp-],ecx
0040D7F7 cmp dword ptr [ebp-],
0040D7FB ja $L545+0Fh (0040d870)
0040D7FD mov edx,dword ptr [ebp-]
0040D800 jmp dword ptr [edx*+40D88Eh]
$L533:
0040D807 push offset string "9\n" (00422f6c)
0040D80C call printf ()
0040D811 add esp,
0040D814 jmp $L545+1Ch (0040d87d)
$L535:
0040D816 push offset string "3\n" ()
0040D81B call printf ()
0040D820 add esp,
0040D823 jmp $L545+1Ch (0040d87d)
$L537:
0040D825 push offset string "7\n" ()
0040D82A call printf ()
0040D82F add esp,
0040D832 jmp $L545+1Ch (0040d87d)
$L539:
0040D834 push offset string "4\n" ()
0040D839 call printf ()
0040D83E add esp,
0040D841 jmp $L545+1Ch (0040d87d)
$L541:
0040D843 push offset string "1\n" ()
0040D848 call printf ()
0040D84D add esp,
0040D850 jmp $L545+1Ch (0040d87d)
$L543:
0040D852 push offset string "2\n" (0042202c)
0040D857 call printf ()
0040D85C add esp,
0040D85F jmp $L545+1Ch (0040d87d)
$L545:
0040D861 push offset string "5\n" ()
0040D866 call printf ()
0040D86B add esp,
0040D86E jmp $L545+1Ch (0040d87d)
0040D870 push offset string "Error!\n" (0042201c)
0040D875 call printf ()
0040D87A add esp,
观察大表,以及反汇编代码,很显然,switch语句中,case的顺序不会影响到大表的生成,大表的生成根据地址而来
3、将case后面的值改成从100开始到109,观察汇编变化(观察值较大时是否生成大表).
#include "stdafx.h" void Function(int m)
{
switch (m)
{
case :
printf("101\n");
break;
case :
printf("102\n");
break;
case :
printf("103\n");
break;
case :
printf("104\n");
break;
case :
printf("105\n");
break;
case :
printf("106\n");
break;
case :
printf("107\n");
break;
case :
printf("108\n");
break;
case :
printf("109\n");
break;
case :
printf("110\n");
break;
default:
printf("Error!\n");
break;
}
} int main(int argc, char* argv[])
{
Function();
return ;
}

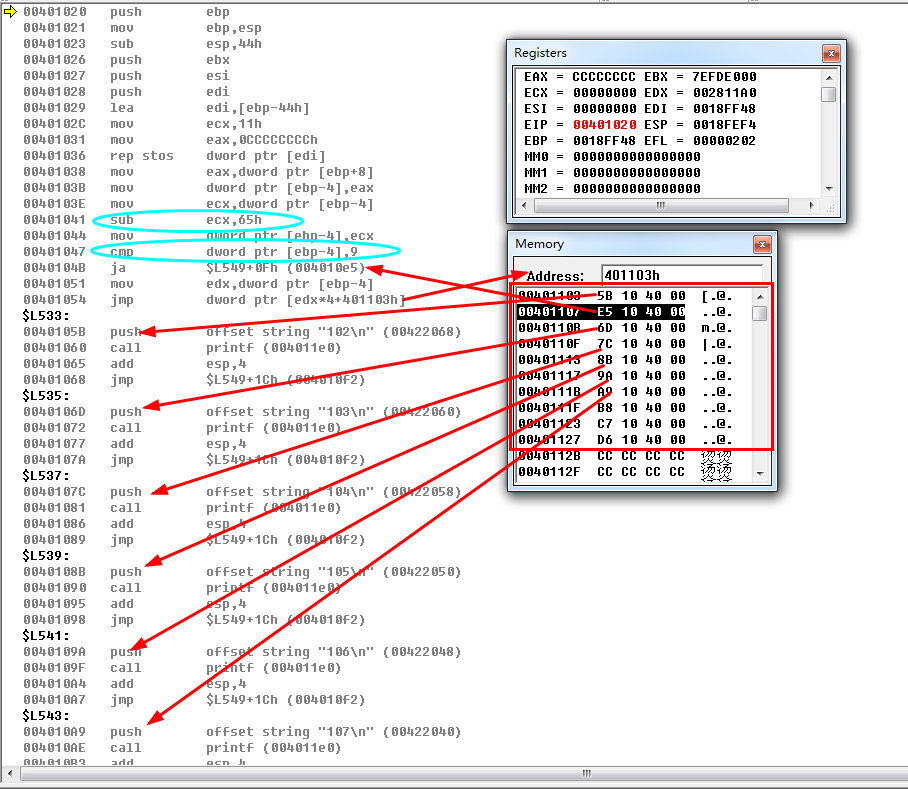
4、将连续的10项中抹去1项或者2项,观察反汇编有无变化(观察大表空缺位置的处理)
#include "stdafx.h" void Function(int m)
{
switch (m)
{
case :
printf("101\n");
break;
/*
case 102:
printf("102\n");
break;
*/
case :
printf("103\n");
break;
case :
printf("104\n");
break;
case :
printf("105\n");
break;
case :
printf("106\n");
break;
case :
printf("107\n");
break;
case :
printf("108\n");
break;
case :
printf("109\n");
break;
case :
printf("110\n");
break;
default:
printf("Error!\n");
break;
}
} int main(int argc, char* argv[])
{
Function();
return ;
}
抹去三项看看?
#include "stdafx.h" void Function(int m)
{
switch (m)
{
case :
printf("101\n");
break;
/*
case 102:
printf("102\n");
break;
case 103:
printf("103\n");
break;
case 104:
printf("104\n");
break;
*/
case :
printf("105\n");
break;
case :
printf("106\n");
break;
case :
printf("107\n");
break;
case :
printf("108\n");
break;
case :
printf("109\n");
break;
case :
printf("110\n");
break;
default:
printf("Error!\n");
break;
}
} int main(int argc, char* argv[])
{
Function();
return ;
}
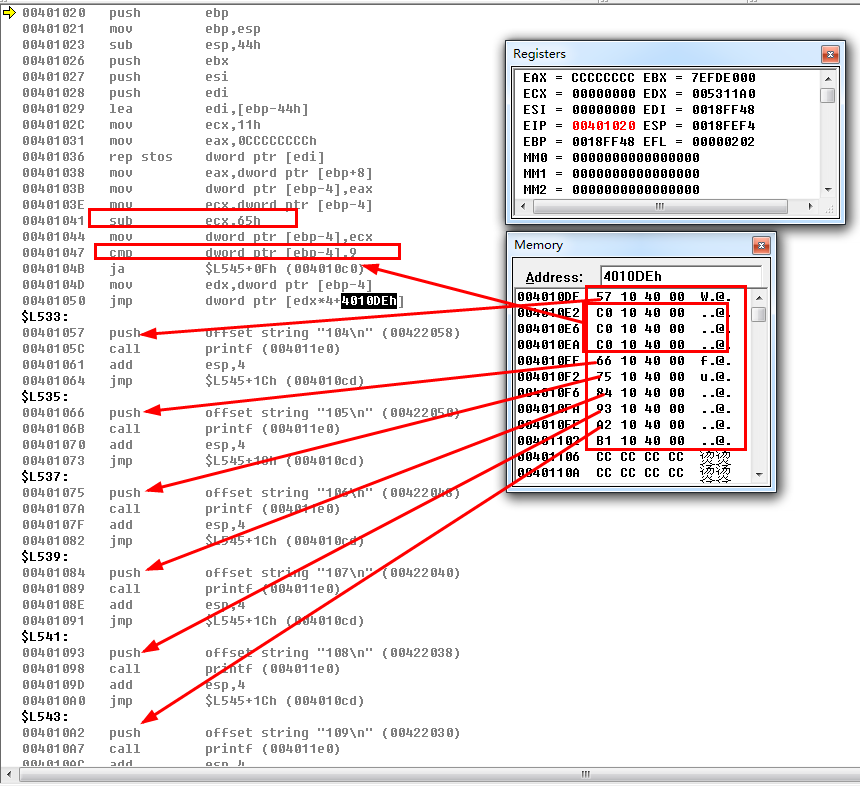
经过上面两个例子可以看出,被抹除掉的项按照default来处理了,我们再抹去两项看看
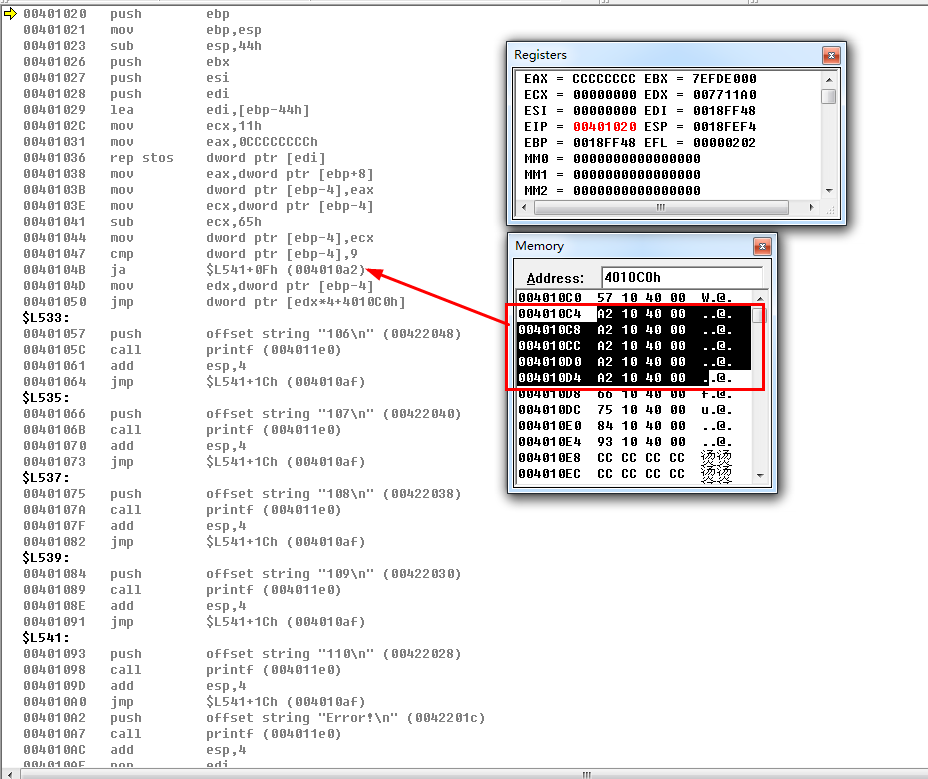
依旧还是生成大表,我们接着再抹除两个,试试看,看编译器是否还是给我们生成大表?
5、在10项中连续抹去,不要抹去最大值和最小值(观察何时生成小表).
#include "stdafx.h" void Function(int m)
{
switch (m)
{
case :
printf("101\n");
break;
/*
case 102:
printf("102\n");
break;
case 103:
printf("103\n");
break;
case 104:
printf("104\n");
break;
case 105:
printf("105\n");
break;
case 106:
printf("106\n");
break;
case 107:
printf("107\n");
break;
*/
case :
printf("108\n");
break;
case :
printf("109\n");
break;
case :
printf("110\n");
break;
default:
printf("Error!\n");
break;
}
} int main(int argc, char* argv[])
{
Function();
return ;
}
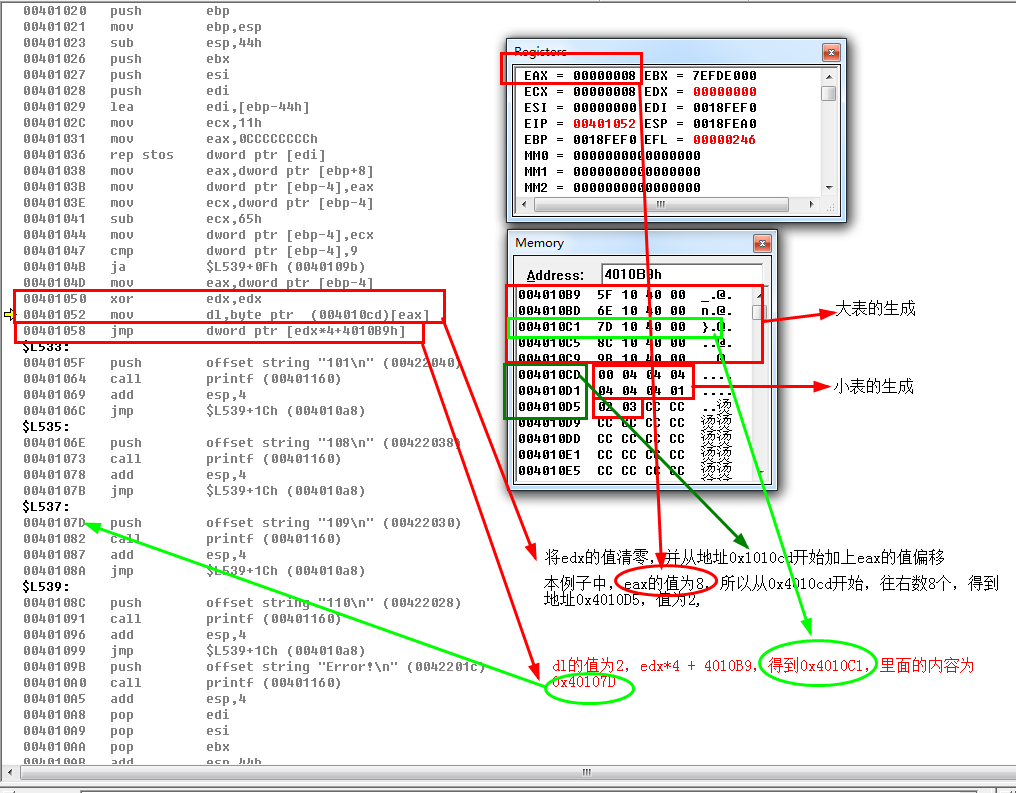
可以看到,由于编译器只采用dl用来存储小表,所以当间隔255个数之后,小表也将不负存在了
6、将case后面常量表达式改成毫不连续的值,观察反汇编变化.
这种switch...case..语句其实基本见不着,因为丝毫无意义
#include "stdafx.h" void Function(int m)
{
switch (m)
{
case :
printf("101\n");
break;
case :
printf("108\n");
break;
case :
printf("109\n");
break;
case :
printf("110\n");
break;
case :
printf("110\n");
break;
case :
printf("110\n");
break;
default:
printf("Error!\n");
break;
}
} int main(int argc, char* argv[])
{
Function();
return ;
}
push ebp
mov ebp,esp
sub esp,44h
push ebx
push esi
push edi
lea edi,[ebp-44h]
0040102C mov ecx,11h
mov eax,0CCCCCCCCh
rep stos dword ptr [edi]
mov eax,dword ptr [ebp+]
0040103B mov dword ptr [ebp-],eax
0040103E cmp dword ptr [ebp-],1388h
jg Function+4Ah (0040106a)
cmp dword ptr [ebp-],1388h
0040104E je Function+8Bh (004010ab)
cmp dword ptr [ebp-],
je Function+5Eh (0040107e)
cmp dword ptr [ebp-],378h
0040105D je Function+6Dh (0040108d)
0040105F cmp dword ptr [ebp-],0C80h
je Function+7Ch (0040109c)
jmp Function+0B8h (004010d8)
0040106A cmp dword ptr [ebp-],2328h
je Function+9Ah (004010ba)
cmp dword ptr [ebp-],4B00h
0040107A je Function+0A9h (004010c9)
0040107C jmp Function+0B8h (004010d8)
0040107E push offset string "101\n" ()
call printf ()
add esp,
0040108B jmp Function+0C5h (004010e5)
0040108D push offset string "108\n" ()
call printf ()
add esp,
0040109A jmp Function+0C5h (004010e5)
0040109C push offset string "109\n" ()
004010A1 call printf ()
004010A6 add esp,
004010A9 jmp Function+0C5h (004010e5)
004010AB push offset string "110\n" ()
004010B0 call printf ()
004010B5 add esp,
004010B8 jmp Function+0C5h (004010e5)
004010BA push offset string "110\n" ()
004010BF call printf ()
004010C4 add esp,
004010C7 jmp Function+0C5h (004010e5)
004010C9 push offset string "110\n" ()
004010CE call printf ()
004010D3 add esp,
004010D6 jmp Function+0C5h (004010e5)
004010D8 push offset string "Error!\n" (0042201c)
004010DD call printf ()
004010E2 add esp,
004010E5 pop edi
004010E6 pop esi
004010E7 pop ebx
004010E8 add esp,44h
switch...case...语句分析(大表跟小表何时产生)的更多相关文章
- if语句,if...else if语句和switch...case语句的区别和分析
前段时间在工作中遇到了一个关于条件判断语句的问题,在if语句,if else if语句和switch case语句这三者之间分析,使用其中最有效率的一种方法. 所以就将这个问题作为自己第一篇博客的主要 ...
- 为什么switch...case语句比if...else执行效率高
在C语言中,教科书告诉我们switch...case...语句比if...else if...else执行效率要高,但这到底是为什么呢?本文尝试从汇编的角度予以分析并揭晓其中的奥秘. 第一步,写一个d ...
- 为什么说在使用多条件判断时switch case语句比if语句效率高?
在学习JavaScript中的if控制语句和switch控制语句的时候,提到了使用多条件判断时switch case语句比if语句效率高,但是身为小白的我并没有在代码中看出有什么不同.去度娘找了半个小 ...
- C语言中switch case语句可变参实现方法(case 参数 空格...空格 参数 :)
正常情况下,switch case语句是这么写的: : : ... ;break ; default : ... ;break ; } 接下来说一种不常见的,但是对于多参数有很大的帮助的写法: 先给一 ...
- 大数据开发实战:Hive优化实战2-大表join小表优化
4.大表join小表优化 和join相关的优化主要分为mapjoin可以解决的优化(即大表join小表)和mapjoin无法解决的优化(即大表join大表),前者相对容易解决,后者较难,比较麻烦. 首 ...
- 逆向知识第九讲,switch case语句在汇编中表达的方式
一丶Switch Case语句在汇编中的第一种表达方式 (引导性跳转表) 第一种表达方式生成条件: case 个数偏少,那么汇编中将会生成引导性的跳转表,会做出 if else的情况(类似,但还是能分 ...
- java中的Switch case语句
java中的Switch case 语句 在Switch语句中有4个关键字:switch,case break,default. 在switch(变量),变量只能是整型或者字符型,程序先读出这个变量的 ...
- switch… case 语句的用法
switch… case 语句的用法 public class Test7 { public static void main(String[] args) { int i=5; switch(i ...
- Python | 基础系列 · Python为什么没有switch/case语句?
与我之前使用的所有语言都不同,Python没有switch/case语句.为了达到这种分支语句的效果,一般方法是使用字典映射: def numbers_to_strings(argument): sw ...
随机推荐
- Dynamics 365触发Microsoft Flow自动生成PDF并作为附件送邮件
我是微软Dynamics 365 & Power Platform方面的工程师罗勇,也是2015年7月到2018年6月连续三年Dynamics CRM/Business Solutions方面 ...
- ABP入门教程13 - 更新菜单
点这里进入ABP入门教程目录 菜单更新 在展示层(即JD.CRS.Web.Mvc)的Startup下打开CRSNavigationProvider.cs //用以存放菜单相关信息 修改如下 using ...
- sqlserver实现分隔字符串
sqlserver 使用函数实现分隔字符串 create function dbo.fn_split ( @str_source nvarchar(max), ) ) returns @temp ta ...
- driver.find_element_by_xpath.clear()无法清空输入框默认值
输入框带默认值,想删除默认值,填写新内容,使用clear()再send_keys(), 发现这种方式无法清除,只会在默认值后面追加新的内容. 上网搜了一下,有两种解决方案,如下: 方法一: 先双击,后 ...
- acwing 50. 序列化二叉树
地址 https://www.acwing.com/problem/content/46/ 请实现两个函数,分别用来序列化和反序列化二叉树. 您需要确保二叉树可以序列化为字符串,并且可以将此字符串反序 ...
- es6一句话拾遗
Symbol最大的作用就是用于消除魔术字符串: Set跟数组的最大区别,就是Set的成员都是唯一的,没有重复:(方法:add(value),has,delete,clear) Map跟对象的最大区别, ...
- Global AI Bootcamp 2019 宁波站活动总结
2019年12月14日,由微软MVP技术社区发起的Global AI Bootcamp 2019盛会在全球60多个国家130个城市点燃.在大中华区,本次活动由全国众多Azure专家及微软MVP技术社区 ...
- React: 认识React
一.简介 React-Native是Facebook开源的跨平台框架,用于实现前端和原生进行混合开发.React-Native开发可以很好的使用原生UI构建用户界面,与传统的使用WebView相比,不 ...
- PHP中查询指定时间范围内的所有日期,月份,季度,年份
/** * 查询指定时间范围内的所有日期,月份,季度,年份 * * @param $startDate 指定开始时间,Y-m-d格式 * @param $endDate 指定结束时间,Y-m-d格式 ...
- es6模板字符串使用使${} 来包裹一个变量或者一个表达式
es6模板字符串使用使${} 来包裹一个变量或者一个表达式 2019-04-28 14:33:54 Gabriel_wei 阅读数 1774 收藏 更多 分类专栏: 前端 版权声明:本文为博主原 ...