spider-通过scrapyd网页管理工具执行scrapy框架
1.首先写一个scrapy框架爬虫的项目
scrapy startproject 项目名称 # 创建项目
cd 项目名称
scrapy genspider 爬虫名称 爬虫网址(www.xxxx) #生成一个爬虫
scrapy crawl 爬虫名称 # 启动爬虫
2.部署环境
pip install scrapyd
pip install scrapyd-client
3.在爬虫项目目录下输入命令:scrapyd,已经在本地6800端口运行

4.在爬虫根目录执行:scrapyd-deploy,如果提示不是内部命令,需要到python目录下scripts下新建一个名为scrapyd-deploy.bat的文件,最好复制,其中有必要的空格可能会遗漏导致报错,路径参考各自的路径
@echo off
"C:\Users\lu\AppData\Local\Programs\Python\Python37-32\python.exe" "C:\Users\lu\AppData\Local\Programs\Python\Python37-32\Scripts\scrapyd-deploy" %*
5.在爬虫项目根目录下执行:
scrapyd-deploy 爬虫名称 -p 爬虫项目名称
6.如遇到报错:Unknown target: 爬虫名称,找到该爬虫项目的scrapy.cfg,作如下修改:
[deploy:abckg] # 加冒号爬虫名称
url = http://localhost:6800/ # 去掉井号
project = ABCkg # 项目名称
7.重新执行第5条操作:此时提示ok

8.如果打开上图中链接显示状态为error,可以直接在6800端口复制:curl http://localhost:6800/schedule.json -d project=default -d spider=somespider在cmd命令行执行,可以得到状态:ok
curl http://localhost:6800/schedule.json -d project=项目名称 -d spider=爬虫名称
若遇到提示curl不是内部命令,可以在git bash里执行。
9.此时该项目已经部署到网页上

10.点击jobs,此时scrapy项目已经在运行中,点击右侧log可以查看爬虫日志
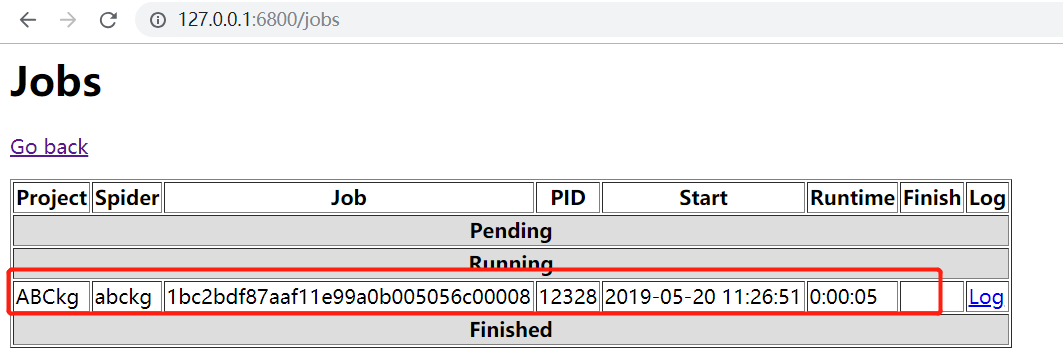
至此! 完毕!!完美实现通过scrapyd网页管理工具执行scrapy框架
spider-通过scrapyd网页管理工具执行scrapy框架的更多相关文章
- KVM网页管理工具WebVirtMgr部署
KVM-WebVirtMgr 0ther https://github.com/retspen/webvirtmgr/wiki System Optimization(Only CentOS6.X) ...
- Python爬虫 ---scrapy框架初探及实战
目录 Scrapy框架安装 操作环境介绍 安装scrapy框架(linux系统下) 检测安装是否成功 Scrapy框架爬取原理 Scrapy框架的主体结构分为五个部分: 它还有两个可以自定义下载功能的 ...
- scrapy可视化管理工具spiderkeeper使用笔记
http://www.scrapyd.cn/doc/156.html 入门中文教程 spiderkeeper是一款开源的spider管理工具,可以方便的进行爬虫的启动,暂停,定时,同时可以查看分布式 ...
- 15款最佳的MySQL管理工具和应用程序
工欲善其事,必先利其器.几乎每个开发人员都有最钟爱的 MySQL 管理工具,它帮助开发人员在许多方面支持包括 PostgreSQL,MySQL,SQLite,Redis,MongoDB 等在内的多种数 ...
- 进程管理工具htop/glances/dstat的使用
进程管理工具htop/glances/dstat的使用 Linux中进程的相关知识 1.什么是进程呢? 通俗的来说进程是运行起来的程序.唯一标示进程的是进程描述符(PID). 2.进程的分类 1)根据 ...
- python爬虫入门(七)Scrapy框架之Spider类
Spider类 Spider类定义了如何爬取某个(或某些)网站.包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item). 换句话说,Spider就是您定义爬取的动作 ...
- 将BUG管理工具(禅道)部署到服务器(测试服务器、云服务器)
禅道是一个开源的项目管理软件,用来记录软件项目的开发过程.bug跟踪以及任务分配,它是基于PHP语言开发的. https://www.zentao.net/download/80111.htm ...
- Zookeeper Windows版的服务安装和管理工具
以前研究过负载均衡,最近正在项目上实施(从来没做过小项目以上级别的东西,哈).然后遇到了多个一模一样但是同时运行的服务.不同服务但依赖同相同的配置数据(前端网页服务:Nginx+IIS+nodejs. ...
- ASP.NET 网站管理工具
ylbtech-Miscellaneos:ASP.NET 网站管理工具 1. 网站管理工具概述返回顶部 网站管理工具概述 介绍 使用网站管理工具,可以通过一个简单的 Web 界面来查看和管理网站配置. ...
随机推荐
- java使用htmlunit工具抓取js中加载的数据
htmlunit 是一款开源的java 页面分析工具,读取页面后,可以有效的使用htmlunit分析页面上的内容.项目可以模拟浏览器运行,被誉为java浏览器的开源实现.这个没有界面的浏览器,运行速度 ...
- C#数据采集用到的几个方法
这两天在做数据采集,因此整理了下数据采集要用到的一些方法.因为我采集的数据比较简单,所以没有用到框架.比较有名的两个框架 HtmlAgilityPack 和 Jumony,感兴趣的可以研究下.当然,火 ...
- SQL Server获取索引创建时间&重建时间&重组时间
之前写过一篇博客"SQL Server中是否可以准确获取最后一次索引重建的时间?",里面主要讲述了三个问题:我们能否找到索引的创建时间?最后一次索引重建(Index Rebuild ...
- (day68)Vue-CLI项目、页面跳转和传参、生命周期钩子
目录 一.Vue-CLI (一)环境搭建 (二)项目的创建 (三)项目目录结构 (四)Vue组件(.vue文件) (五)全局脚本文件main.js(项目入口) (六)Vue请求生命周期 二.页面跳转和 ...
- 新版Notepad++加十六进制查看的插件HexEditor
Notepad++新版虽然去掉了在线插件商店功能,但是依然可以使用自定义插件 Notepad++下载地址 腾讯(请务必点普通下载):https://pc.qq.com/detail/0/detail_ ...
- [译]Vulkan教程(13)图形管道基础之Shader模块
[译]Vulkan教程(13)图形管道基础之Shader模块 Shader modules Unlike earlier APIs, shader code in Vulkan has to be s ...
- [译]Vulkan教程(10)交换链
[译]Vulkan教程(10)交换链 Vulkan does not have the concept of a "default framebuffer", hence it r ...
- ej3-0开端
开始 编码多年,总有一些最佳实践,Java也是,比如设计模式,比如Effective Java 3 (ej3) . 设计模式先后看过<大话设计模式>,<HeadFirst 设计模式& ...
- 如何以管理员方式打开VS
第一种 打开VS快捷方式的属性对话框. 勾选"用管理员身份运行" 但是这种方式只有在点击快捷方式直接打开vs时是一管理员身份启动的,也就是如果直接打开Solution,则不是管理员 ...
- centos添加用户并赋予管理员权限
用centos时,root用户一般都是超级管理员使用的,一般不轻易给别人,但是有时候同事安装软件时需要root账号,又不得不给,只能重新建一个用户,并赋予管理员权限.下面介绍创建用户并赋予管理员权限的 ...