8 NLP-自然语言处理Demo
1 NLP(自然语言处理)
1.1相似度
相似度和距离之间关系:
- 1、文本相似度:
- 1) 语义相似、但字面不相似:
- 老王的个人简介
- 铁王人物介绍
- 2) 字面相似、但是语义不相似:
- 我吃饱饭了
- 我吃不饱饭
- 2、方案:
- 1) 语义相似:依靠用户行为,最基本的方法:(1)基于共点击的行为(协同过滤),(2)借助回归算法
- 歌神 -> 张学友
- 2) 字面相似:(1) LCS最大公共子序列 (2) 利用中文分词
- 老王的个人简介 => 老王 / 的 / 个人 / 简介
- token
- 3 字面相似的问题解决:
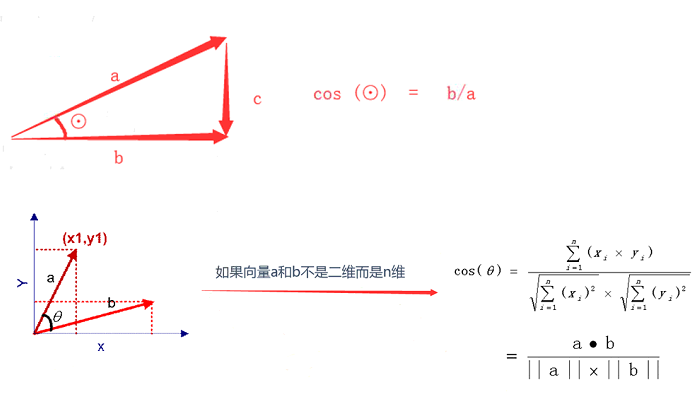
- 余弦相似度 cosine
- 举例:A(1,2,3) B(2,3,4)
- cosine(A,B) = 分子 / 分母 - 分子:A * B = 1 * 2+2 *
3+3 * 4 = 20
- 分母:|A| * |B| = 20.12
- |A| = sqrt(1 * 1+2 * 2+3 * 3) = 3.74 - |B| = sqrt(2 * 2+3
* 3+4 * 4) = 5.38
1.2 常用方法
• 相似度度量:计算个体间相似程度
• 相似度值越小,距离越大,相似度值越大,距离越小
• 最常用——余弦相似度
- 一个向量空间中两个向量夹角的余弦值作为衡量两个个体之间差异的大小
- 余弦值接近1,夹角趋于0,表明两个向量越相似

得到了文本相似度计算的处理流程是:
– 找出两篇文章的关键词; – 每篇文章各取出若干个关键词,合并成一个集合,计算每篇文章对于这个集合中的词的词频 – 生成两篇文章各自的词频向量; – 计算两个向量的余弦相似度,值越大就表示越相似
1.3 关键词
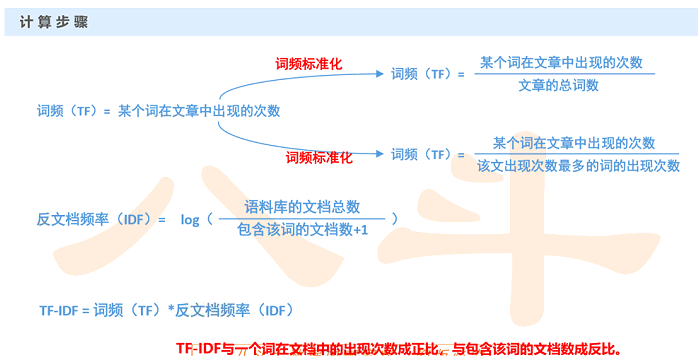
TF/IDF
- 1) TF:词频
- 假设:如果一个词很重要,应该会在文章中多次出现
- 词频——TF(Term Frequency):一个词在文章中出现的次数
- 也不是绝对的!出现次数最多的是“的”“是”“在”,这类最常用的词, 叫做停用词(stop words)
- 停用词对结果毫无帮助,必须过滤掉的词
- 过滤掉停用词后就一定能接近问题么?
- 进一步调整假设:如果某个词比较少见,但是它在这篇文章中多次出现,那 么它很可能反映了这篇文章的特性,正是我们所需要的关键词
- 2) IDF:反文档频率
- 在词频的基础上,赋予每一个词的权重,进一步体现该词的重要性,
- 最常见的词(“的”、“是”、“在”)给予最小的权重
- 较常见的词(“国内”、“中国”、“报道”)给予较小的权重
- 较少见的词(“养殖”、“维基”、“涨停”)给予较小的权重
(关键词:在当前文章出现较多,但在其他文章中出现较少)
(将TF和IDF进行相乘,就得到了一个词的TF-IDF值,某个词对文章重要性越高,该值越大, 于是排在前面的几个词,就是这篇文章的关键词。)
1.4 关键词方法 : 自动摘要
- 1) 确定关键词集合(两种方法(a)top-10 (b)阈值截断 > 0.8 ) (阈值截断针对TFIDF的值进行截断取值操作)
- 2)哪些句子包含关键词,把这些句子取出来
- 3) 对关键词排序,对句子做等级划分
- 4)把等级高的句子取出来,就是摘要
1.5 NLP总结
• 优点:简单快速,结果比较符合实际情况
• 缺点:单纯以“词频”做衡量标准,不够全面,有时重要的词可能出现的次数并不多
这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。(一种解决方法是,对全文的第一段和每一段的第一句话,给予较大的权重。)
1.6 TFIDF实践实践:

这个下面放了508篇文章
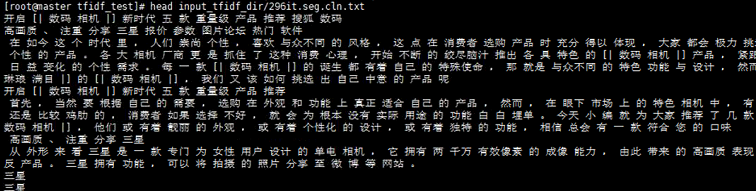
发现这些文章已经进行分词(已空格分隔)
如果每篇文章都打开那么会非常的慢,所以需要对文章进行预处理
(1)数据预处理:把所有文章的内容,全部收集到一个文件中
convert.py
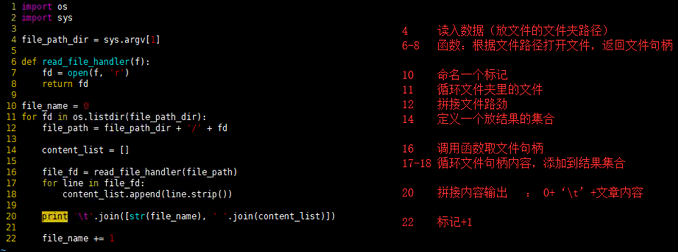
import os
import sys
file_path_dir = sys.argv[1]
def read_file_handler(f):
fd = open(f, 'r')
return fd
file_name = 0
for fd in os.listdir(file_path_dir):
file_path = file_path_dir + '/' + fd
content_list = []
file_fd = read_file_handler(file_path)
for line in file_fd:
content_list.append(line.strip())
print '\t'.join([str(file_name), ' '.join(content_list)])
file_name += 1

python convert.py input_tfidf_dir/ > idf_input.data

一共508行 有数字标记
(2)计算IDF:通过MapReduce批量计算IDF
map.py
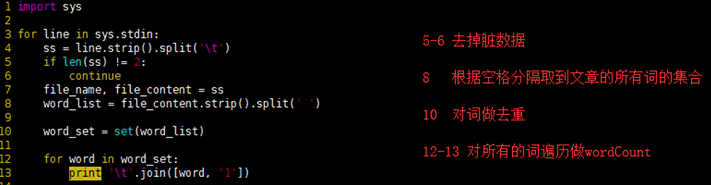
import sys
for line in sys.stdin:
ss = line.strip().split('\t')
if len(ss) != 2:
continue
file_name, file_content = ss
word_list = file_content.strip().split(' ')
word_set = set(word_list)
for word in word_set:
print '\t'.join([word, ''])
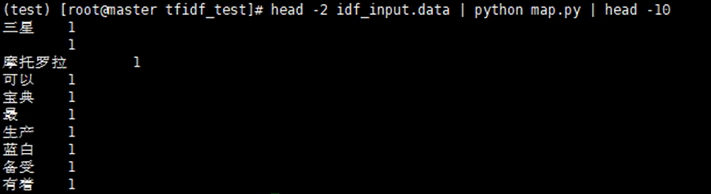
head -2 idf_input.data | python map.py | head -10
测试没有问题继续reduce
red.py
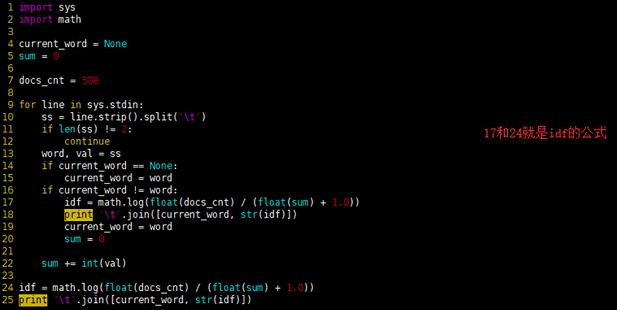
import sys
import math
current_word = None
sum = 0
docs_cnt = 508
for line in sys.stdin:
ss = line.strip().split('\t')
if len(ss) != 2:
continue
word, val = ss
if current_word == None:
current_word = word
if current_word != word:
idf = math.log(float(docs_cnt) / (float(sum) + 1.0))
print '\t'.join([current_word, str(idf)])
current_word = word
sum = 0
sum += int(val)
idf = math.log(float(docs_cnt) / (float(sum) + 1.0))
print '\t'.join([current_word, str(idf)])
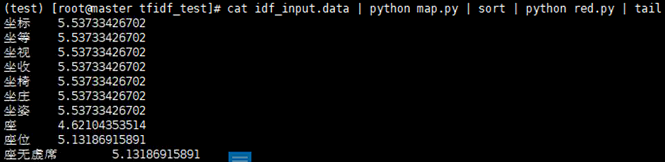
cat idf_input.data | python map.py | sort | python red.py | tail
测试一下,发现没有问题,注意数据量过大回报上面的异常
现在做mapReduce的准备工作,将我们预处理的数据提交到hdfs上

编写脚本run.sh
HADOOP_CMD="/usr/local/src/hadoop-2.6.5/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.5/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar"
INPUT_FILE_PATH="/idf_input.data"
OUTPUT_PATH="/tfidf_output"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH \
-output $OUTPUT_PATH \
-mapper "python map.py" \
-reducer "python red.py" \
-file ./map.py \
-file ./red.py
然后
bash run.sh hadoop fs -ls /tfidf_output hadoop fs -text /tfidf_output/part- | sort -k2 -n | head hadoop fs -text /tfidf_output/part- | sort -k2 -nr | head

8 NLP-自然语言处理Demo的更多相关文章
- flask 第六章 人工智能 百度语音合成 识别 NLP自然语言处理+simnet短文本相似度 图灵机器人
百度智能云文档链接 : https://cloud.baidu.com/doc/SPEECH/index.html 1.百度语音合成 概念: 顾名思义,就是将你输入的文字合成语音,例如: from a ...
- NLP 自然语言处理实战
前言 自然语言处理 ( Natural Language Processing, NLP) 是计算机科学领域与人工智能领域中的一个重要方向.它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和 ...
- NLP自然语言处理 jieba中文分词,关键词提取,词性标注,并行分词,起止位置,文本挖掘,NLP WordEmbedding的概念和实现
1. NLP 走近自然语言处理 概念 Natural Language Processing/Understanding,自然语言处理/理解 日常对话.办公写作.上网浏览 希望机器能像人一样去理解,以 ...
- NLP自然语言处理入门-- 文本预处理Pre-processing
引言 自然语言处理NLP(nature language processing),顾名思义,就是使用计算机对语言文字进行处理的相关技术以及应用.在对文本做数据分析时,我们一大半的时间都会花在文本预处理 ...
- NLP 自然语言处理
参考: 自然语言处理怎么最快入门:http://www.zhihu.com/question/ 自然语言处理简介:http://wenku.baidu.com/link?url=W6Mw1f-XN8s ...
- NLP自然语言处理学习笔记二(初试)
前言: 用Python对自然语言处理有很好的库.它叫NLTK.下面就是对NLTK的第一尝试. 安装: 1.安装Pip 比较简单,得益于CentOS7自带的easy_install.执行一行命令就可以搞 ...
- java自然语言理解demo,源码分享(基于欧拉蜜)
汇率换算自然语言理解功能JAVA DEMO >>>>>>>>>>>>>>>>>>>&g ...
- 初识NLP 自然语言处理
接下来的一段时间,要深入研究下自然语言处理这一个学科,以期能够带来工作上的提升. 学习如何实用python实现各种有关自然语言处理有关的事物,并了解一些有关自然语言处理的当下和新进的研究主题. NLP ...
- NLP 自然语言处理之综述
(1) NLP 介绍 NLP 是什么? NLP (Natural Language Processing) 自然语言处理,是计算机科学.人工智能和语言学的交叉学科,目的是让计算机处理或"理解 ...
- [NLP自然语言处理]谷歌BERT模型深度解析
我的机器学习教程「美团」算法工程师带你入门机器学习 已经开始更新了,欢迎大家订阅~ 任何关于算法.编程.AI行业知识或博客内容的问题,可以随时扫码关注公众号「图灵的猫」,加入”学习小组“,沙雕博主 ...
随机推荐
- Django之Cookie Session详解,CBV,FBV登陆验证装饰器和自定义分页
Cookie Session和自定义分页 cookie Cookie的由来 大家都知道HTTP协议是无状态的. 无状态的意思是每次请求都是独立的,它的执行情况和结果与前面的请求和之后的请求都无直接 ...
- C++程序设计2(侯捷video all)
一.转换函数Conversion function(video2) 一个类型的对象,使用转换函数可以转换为另一种类型的对象. 例如一个分数,理应该可以转换为一个double数,我们用以下转换函数来实现 ...
- 【设计模式】行为型11解释器模式(Interpreter Pattern)
解释器模式(Interpreter Pattern) 解释器模式应用场景比较小,也没有固定的DEMO,中心思想就是自定义解释器用来解释固定的对象. 定义:给定一个语言,定义它的文法表示,并定义一个 ...
- eclipse中junit简单使用
1.在工程中右击 Build Path,Add libraries 然后就可以运行对应的方法了,不需要main方法调用了
- Unity Shader 屏幕后效果——颜色校正
屏幕后效果指的是,当前整个场景图已经渲染完成输出到屏幕后,再对输出的屏幕图像进行的操作. 在Unity中,一般过程通常是: 1.建立用于处理效果的shader和临时材质,给shader脚本传递需要控制 ...
- Vue SSR初探
因为之前用nuxt开发过应用程序,但是nuxt早就达到了开箱即用的目的,所以一直对vue ssr的具体实现存在好奇. 构建步骤 我们通过上图可以看到,vue ssr 也是离不开 webpack 的打包 ...
- HTML end~
一.浏览器的兼容问题(关于浏览器的兼容问题 有很多大佬已经解释的很清楚了 这个得自己百度去多花点时间去了解 这里咱们只说一下前面的漏点) 浏览器兼容性问题又被称为网页兼容性或网站兼容性问题,指网页在各 ...
- SQL Server温故系列(3):SQL 子查询 & 公用表表达式 CTE
1.子查询 Subqueries 1.1.单行子查询 1.2.多行子查询 1.3.相关子查询 1.4.嵌套子查询 1.5.子查询小结及性能问题 2.公用表表达式 CTE 2.1.普通公用表表达式 2. ...
- 数据结构与算法---树结构(Tree structure)
为什么需要树这种数据结构 数组存储方式的分析 优点:通过下标方式访问元素,速度快.对于有序数组,还可使用二分查找提高检索速度. 缺点:如果要检索具体某个值,或者插入值(按一定顺序)会整体移动,效率较低 ...
- webpack4基础入门操作(一)
基于webpack4实践:开始:打开控制面板,制定到创建Webpack的文件夹. 并创建初始配置文件package.json 输入命令:npm init -y,在文件夹中出现一个package.jso ...