ubuntu安装伪分布式Hadoop3.1.2
本文是基于已经安装好的ubuntu环境上搭建伪分布式hadoop,在virtualbox安装ubuntu可以参考小编的
”virtualbox安装ubuntu16.04 LTS及其配置“
一、Hadoop的三种运行模式(启动模式)
1.1、单机模式(独立模式)(Local或Standalone Mode)
-默认情况下,Hadoop即处于该模式,用于开发和调式。
-不对配置文件进行修改。
-使用本地文件系统,而不是分布式文件系统。
-Hadoop不会启动NameNode、DataNode、JobTracker、TaskTracker等守护进程,Map()和Reduce()任务作为同一个进程的不同部分来执行的。
-用于对MapReduce程序的逻辑进行调试,确保程序的正确。
1.2、伪分布式模式(Pseudo-Distrubuted Mode)
-Hadoop的守护进程运行在本机机器,模拟一个小规模的集群
-在一台主机模拟多主机。
-Hadoop启动NameNode、DataNode、JobTracker、TaskTracker这些守护进程都在同一台机器上运行,是相互独立的Java进程。
-在这种模式下,Hadoop使用的是分布式文件系统,各个作业也是由JobTraker服务,来管理的独立进程。在单机模式之上增加了代码调试功能,允许检查内存使用情况,HDFS输入输出,
以及其他的守护进程交互。类似于完全分布式模式,因此,这种模式常用来开发测试Hadoop程序的执行是否正确。
-修改3个配置文件:core-site.xml(Hadoop集群的特性,作用于全部进程及客户端)、hdfs-site.xml(配置HDFS集群的工作属性)、mapred-site.xml(配置MapReduce集群的属性)
-格式化文件系统
1.3、全分布式集群模式(Full-Distributed Mode)
-Hadoop的守护进程运行在一个集群上
-Hadoop的守护进程运行在由多台主机搭建的集群上,是真正的生产环境。
-在所有的主机上安装JDK和Hadoop,组成相互连通的网络。
-在主机间设置SSH免密码登录,把各从节点生成的公钥添加到主节点的信任列表。
-修改3个配置文件:core-site.xml、hdfs-site.xml、mapred-site.xml,指定NameNode和JobTraker的位置和端口,设置文件的副本等参数
-格式化文件系统
二、准备系统环境
2.1、运行虚拟机,进行静态网络配置:
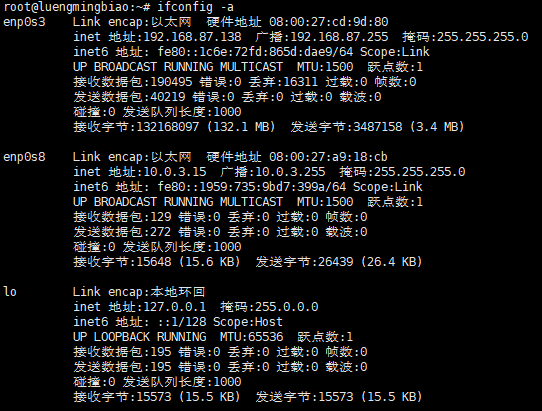
在终端上输入ifconfig -a命令查看网卡名,我的主机有三个网络接口,分别是enp0s3(桥接网卡),enp0s8(NAT),lo(动态获取ip)
# ifconfig -a
对/etc/network/interfaces文件进行编辑,以下是在终端上执行的命令:
sudo vim /etc/network/interfaces

上图是ubuntu的/etc/network/interfaces文件默认的内容,默认动态获取方法的配置。
但是在业务上需要给ubuntu主机配置静态ip网络,在这里我只对enp0s3进行修改,以下是静态分配的配置方法(根据自己的需求改):
auto enp0s3
iface enp0s3 inet static
address 192.168.87.138
netmask 255.255.255.0
gateway 192.168.87.254
接下来需要添加域名服务器,编辑/etc/resolv.conf文件,添加域名服务器,在这里我选择了全球通用的DNS域名服务器,国内用户推荐使用,速度较快!
sudo vim /etc/resolv.conf
nameserver 114.114.114.114
或者
nameserver 8.8.8.8
配置已经完成了,接下来需要重启网络,网络重启有多种方法,在这里只列出两种方法,二选一即可。
1. 重启网卡
/etc/init.d/networking restart
2. 这两条命令是重启某个网络接口,一个系统可能有多个网络接口
# ifdown enp0s3
# ifup enp0s3
检查网络配置参数是否正确:
# ifconfig

检查是否能ping通:
ping www.qq.com
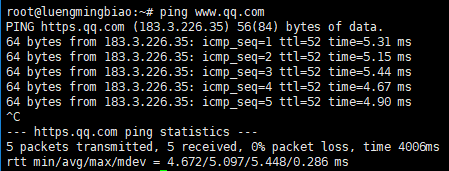
已成功ping通,静态网络已配置好了。
2.2、修改主机名与IP地址的对应关系
查看主机名:
# hostname

修改/etc/hosts文件:
# vim /etc/hosts
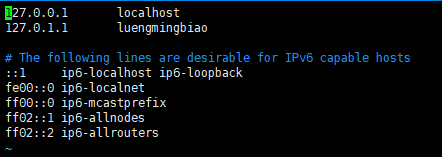
/etc/hosts文件默认是上图所示,修改文件为以下内容,注释127.0.1.1,添加主机静态地址与主机名:
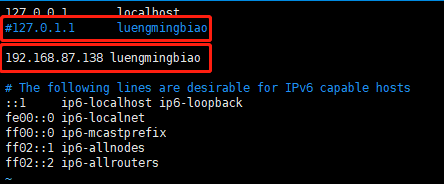
2.3、配置本机ssh免密码登录
单机配置ssh免密登陆的话,输入以下的命令即可:
提示输入信息,一直回车按默认即可。
# ssh-keygen -t rsa
# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# chmod ~/.ssh/authorized_keys

完成之后,以 root 用户登录,修改 ssh 配置文件:
vim /etc/ssh/sshd_config
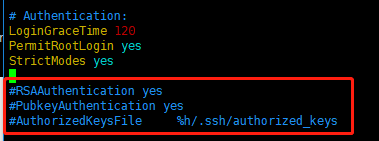
把文件中的下面几条信息的注释去掉,如图所示:
RSAAuthentication yes # 启用RSA认证
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile .ssh/authorized_keys #公钥文件路径(和上面生成的文件同)
然后重启服务:
# service sshd restart
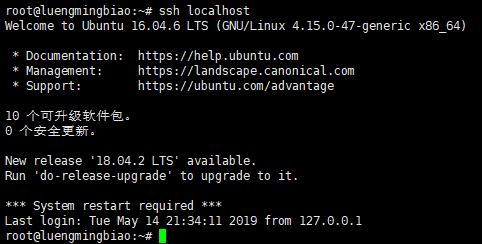
输入ssh localhost验证出现如下界面,中间不需要输入密码,即配置完成。
# ssh localhost
2.4、 安装Oracle Java,并配置环境变量
2. 解压tar包,指定解压/usr/local/目录
# tar -zxvf jdk-8u211-linux-x64.tar.gz -C /usr/local/
3. 配置环境变量
# vim /etc/profile
然后添加以下配置在文件尾:
export JAVA_HOME=/usr/local/jdk1..0_211
export PATH=$PATH:$JAVA_HOME/bin
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
保存退出即可。
4. 测试jdk配置成功否
刷新环境变量:
# source /etc/profile
输入java -verion,如配置成功,有下图的java版本在终端上显示:

到此,hadoop需要的系统环境已经搭建完毕了,接下来开始搭建伪分布式hadoop集群~
三、搭建伪分布式hadoop集群
3.1 安装hadoop
从官网下载hadoop3.1.2,解压hadoop安装包到/usr/local/目录下:
# tar -zxvf hadoop-3.1..tar.gz -C /usr/local
在环境变量配置hadoop:
# vim /etc/profile
然后添加以下配置在文件尾:
export HADOOP_HOME=/usr/local/hadoop-3.1.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_HDFS_HOME=/usr/local/hadoop-3.1.2
export HADOOP_CONF_DIR=/usr/local/hadoop-3.1.2/etc/hadoop
使用source /etc/profile刷新环境变量后,用hadoop version命令测试是否安装成功:
# source /etc/profile
# hadoop version

3.2 伪分布式hadoop配置
hadoop的配置文件统一放在$HADOOP_HOME/etc/hadoop目录下,在这里我们只需要修改5个文件,分别是hadoop-env.sh,core-site.xml,mapred-site.xml,yarn-site.xml,yarn-site.xml。
1. hadoop-env.sh
在文件中修改如下:
export JAVA_HOME=/usr/local/jdk1..0_211
export HADOOP_HOME=/usr/local/hadoop-3.1.2
2. core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/data/</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>file:///usr/local/hadoop/data/dfs/namesecondary</value>
</property>
</configuration>
3. hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.http.address</name>
<value>luengmingbiao:</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop/data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoop/data/dfs/data</value>
</property>
</configuration>
4. mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5. yarn-site.xml
<configuraion>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>luengmingbiao</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/usr/local/hadoop-3.1.2/etc/hadoop:/usr/local/hadoop-3.1.2/share/hadoop/common/lib/*:/usr/local/hadoop-3.1.2/share/hadoop/common/*:/usr/local/hadoop-3.1.2/share/hadoop/hdfs:/usr/local/hadoop-3.1.2/share/hadoop/hdfs/lib/*:/usr/local/hadoop-3.1.2/share/hadoop/hdfs/*:/usr/local/hadoop-3.1.2/share/hadoop/mapreduce/lib/*:/usr/local/hadoop-3.1.2/share/hadoop/mapreduce/*:/usr/local/hadoop-3.1.2/share/hadoop/yarn:/usr/local/hadoop-3.1.2/share/hadoop/yarn/lib/*:/usr/local/hadoop-3.1.2/share/hadoop/yarn/*</value>
</property>
</configuraion>
注: “yarn.application.classpath“可以通过在终端上输入如下命令获取:
# hadoop classpath
对hdfs(Hadoop Distributed File System)进行格式化,hdfs是用来存储数据的分布式文件系统。
# hdfs namenode -format
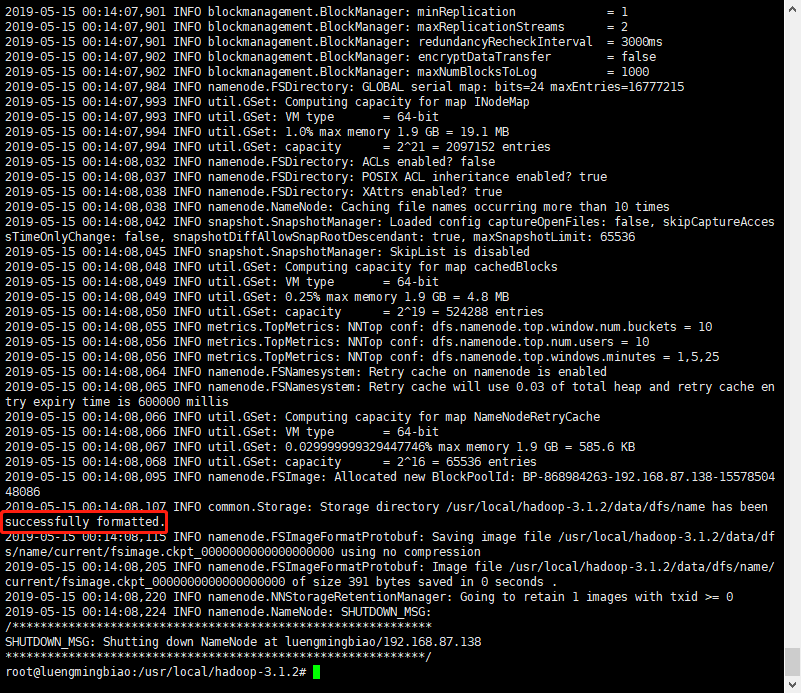
出现上述图所示,代表成功格式化。
Hadoop3.x以上版本在启动上有一个坑,不添加以下配置启动进程的时候会报以下的错并打印到终端上:
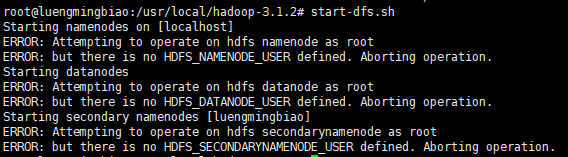
解决方案(可以只针对ERROR出现的变量进行定义,如果不行再配置全部):
# vim $HADOOP_HOME/sbin/start-dfs.sh

# vim $HADOOP_HOME/sbin/stop-dfs.sh

# vim $HADOOP_HOME/sbin/start-yarn.sh
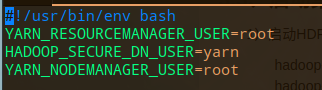
# vim $HADOOP_HOME/sbin/stop-yarn.sh
3.3 启动Hadoop
1. 启动HDFS
# hdfs --daemon start namenode
# hdfs --daemon start datanode
# hdfs --daemon start secondarynamenode
或
# start-dfs.sh
2. 启动YARN集群
# yarn --daemon start resourcemanager
# yarn --daemon start nodemanager
或
# start-yarn.sh
3. jps命令查看是否启动成功
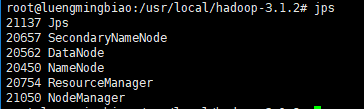
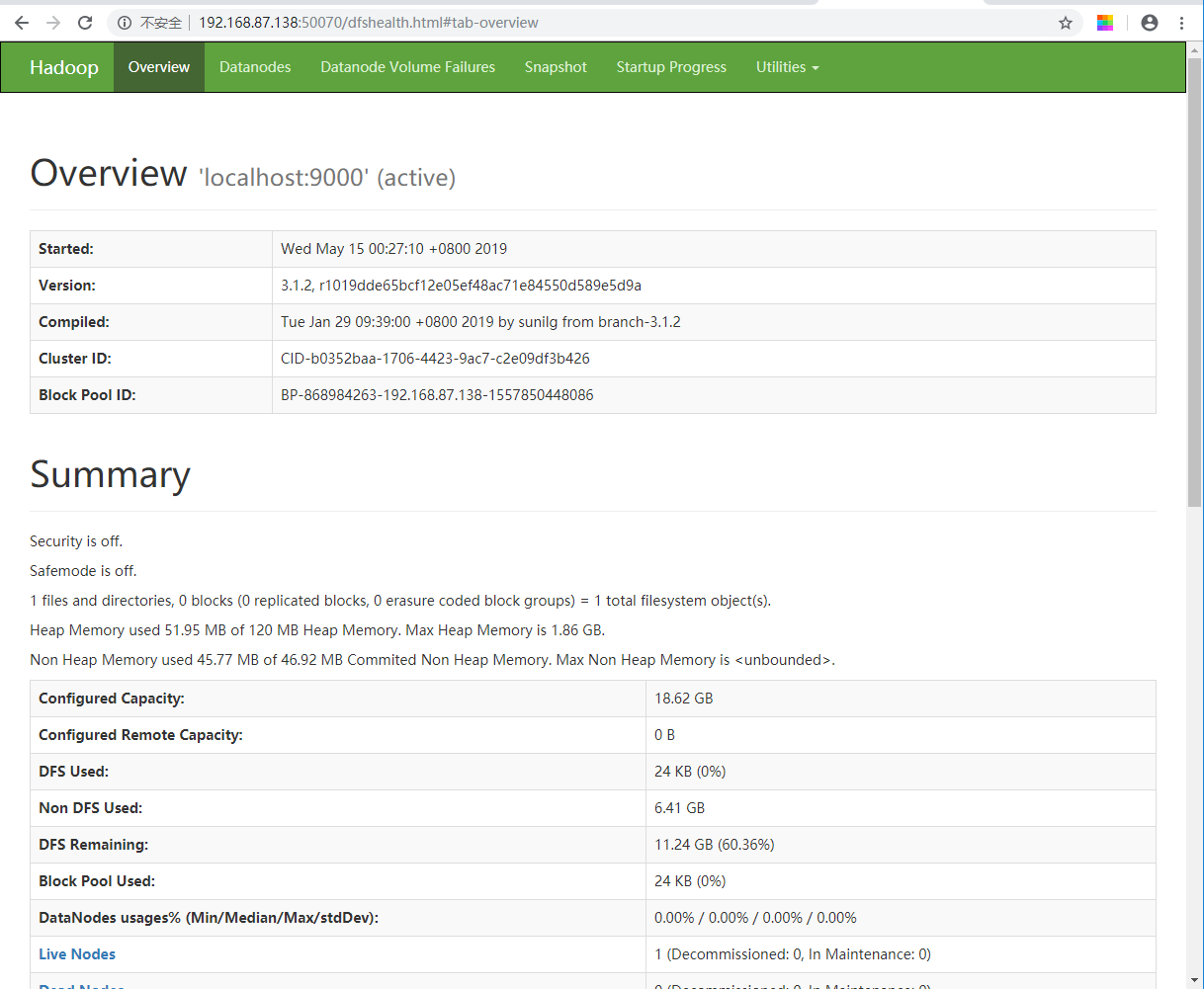
4. HDFS和YARN集群都有默认的Web可视化页面
HDFS: http://主机ip:50070
YARN:http://主机ip:8088
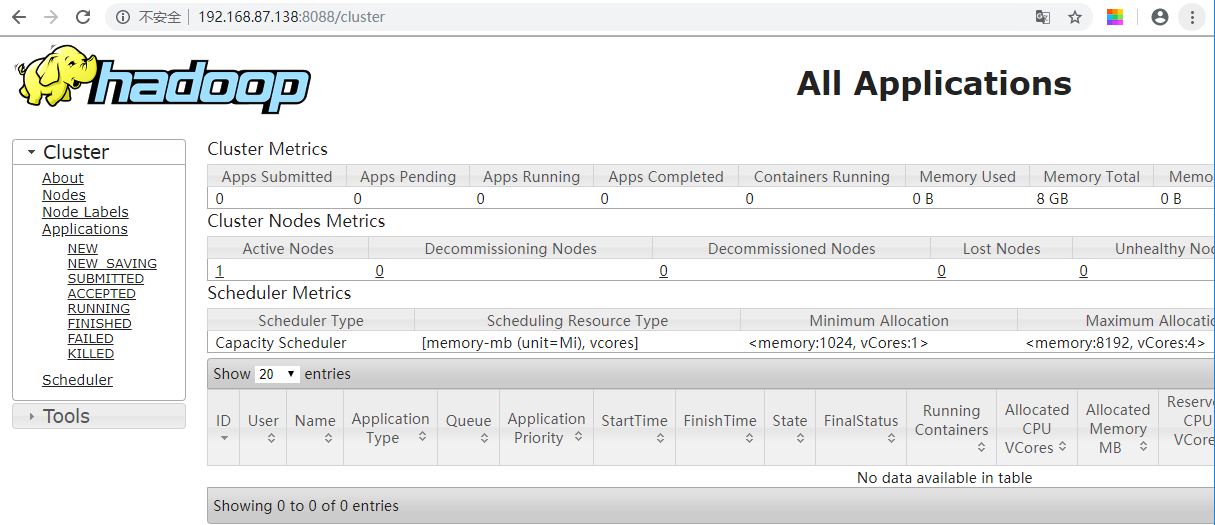
3.4 测试Hadoop
建立测试文件:
# vim test.txt
然后输入如下数据:
hello hadoop
hello World
Hello Java
Hey man
i am a programmer
将测试文件放到测试目录中:
# hdfs dfs -mkdir hdfs:///hadoop
# hdfs dfs -mkdir hdfs:///hadoop/input
# hdfs dfs -put ./test.txt hdfs:///hadoop/input
执行hadoop自带的wordcount程序:
# hadoop jar /usr/local/hadoop-3.1.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar wordcount hdfs:///hadoop/input hdfs:///output


然后在命令行输入 hdfs dfs -cat hdfs:///output/part-r-00000 查看词频统计结果:
# hdfs dfs -cat hdfs:///output/part-r-00000
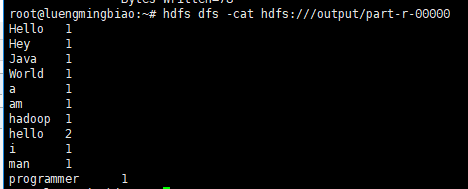
到此,伪分布式Hadoop已经搭建成功了~
ubuntu安装伪分布式Hadoop3.1.2的更多相关文章
- 避坑之Hadoop安装伪分布式(Hadoop3.2.0/Ubuntu14.04 64位)
一.安装JDK环境(这个可以网上随意搜一篇教程了照着弄,这里不赘述) 安装成功之后 输入 输入:java -version 显示如下说明jdk安装成功(我这里是安装JDK8) 二.安装Hadoop3. ...
- Ubuntu下伪分布式模式Hadoop的安装及配置
1.Hadoop运行模式Hadoop有三种运行模式,分别如下:单机(非分布式)模式伪分布式(用不同进程模仿分布式运行中的各类节点)模式完全分布式模式注:前两种可以在单机运行,最后一种用于真实的集群环境 ...
- Ubuntu 14.10 下安装伪分布式hdoop 2.5.0
折腾了一天,其间配置SSH时候出现了问题,误删了ssh-keygen相关文件,导致配置SSH彻底萎了,又重装了系统.... 采用伪分布式模式,即hadoop将所有进程运行于同一台主机上,但此时Hado ...
- Ubuntu 14.10 下安装伪分布式hbase 0.99.0
HBase 安装分为:单击模式,伪分布式,完全分布式,在单机模式中,HBase使用本地文件系统而不是HDFS ,所有的服务和zooKeeper都运作在一个JVM中.本文是安装的伪分布式. 安装步骤如下 ...
- [转]CentOS下安装伪分布式Hadoop-1.2.1
From: http://blog.csdn.net/yinan9/article/details/16805275 环境:CentOS 5.10(虚拟机下) [root@localhost hado ...
- hadoop一键安装伪分布式
hadoop伪分布式和hive在openSUSE中的安装 在git上的路径为:https://github.com/huabingood/hadoop--------/tree/master 各个文件 ...
- 搭建伪分布式 hadoop3.1.3 + zookeeper 3.5.7 + hbase 2.2.2
安装包 Hadoop 3.1.3 Zookeeper 3.5.7 Hbase 2.2.2 所需工具链接: 链接:https://pan.baidu.com/s/1jcenv7SeGX1gjPT9RnB ...
- CentOS7上安装伪分布式Hadoop
1.下载安装包 下载hadoop安装包 官网地址:https://hadoop.apache.org/releases.html 版本:建议使用hadoop-2.7.3.tar.gz 系统环境:Cen ...
- ubuntu 下安装伪分布式 hadoop
安装准备: (1)hadoop安装包:hadoop-1.2.1.tar.gz (2)jdk安装包:jdk-7u60-linux-i586.gz (3)要是须要eclipse开发的话 还须要eclips ...
随机推荐
- 阿里云服务器CentOS7.5安装RabbitMQ
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件).RabbitMQ服务器是用Erlang语言编写的,而集群和故障转移是构建在开放电信平台框架上的. 为什么 ...
- 28nm工艺下,自动生成管脚排列文件,给设计加PAD,并在PAD上面打Label的流程(含Tcl脚本)
本文转自:自己的微信公众号<数字集成电路设计及EDA教程> 里面主要讲解数字IC前端.后端.DFT.低功耗设计以及验证等相关知识,并且讲解了其中用到的各种EDA工具的教程. 考虑到微信公众 ...
- JVM监控jconsole
1. 描述 程序在开发过程中,有可能会发生CPU飙高.内存溢出等问题或系统在后期调优阶段,不可避免的要监控JVM情况,JDK自带的Jconsole监控工具,结合Tomcat使用非常方便,占用内存小 ...
- ~~番外:说说Python 面向对象编程~~
进击のpython Python 是支持面向对象的 很多情况下使用面向对象编程会使得代码更加容易扩展,并且可维护性更高 但是如果你写的多了或者某一对象非常复杂了,其中的一些写法会相当相当繁琐 而且我们 ...
- Linux关闭进程。
一.shell命令根据端口后关闭指定进程. $(netstat -nlp | | awk '{print $7}' | awk -F"/" '{ print $1 }') nets ...
- 不调用free会内存泄露吗?
内存泄露的概念大家可以自行百度下,本文不做阐述.本文要讲的是在程序中分配了内存,但是最后没有使用free()函数来释放这块内存,会导致内存泄露吗?比如有如下代码: #include <stdio ...
- Linux 提升逼格之 命令别名 分享
1, 使用场景 Linux下开发 肯定是日常要用命令行的,命令行里包含了众多的命令和工具,例如: git.shell.以及一众系统命令等. 举个例子,码农最常用的 git add ,如果加上别名 可设 ...
- [原创]SSH Tunnel for UDP
SSH Tunnel for UDP UDP port forwarding is a bit more complicated. We will need to convert the packet ...
- cozmo 入坑日记及开发环境搭建
前几日,朋友在群里发了一个机器人的小视频,视频里机器人可以对话,可以推箱子,开心以后会哈哈大笑,非常有趣. 详细了解里一下,这是个叫 cozmo 的智能机器人,可以配合 SDK 用 python 编程 ...
- 【并查集】模板 + 【HDU 1213、HDU 1232、POJ 2236、POJ 1703】例题详解
不想看模板,想直接看题目的请戳下面目录: 目录: HDU 1213 How Many Tables[传送门] HDU 1232 畅通工程 [传送门] POJ 2236 Wireless Network ...