darknet是如何对数据集做resize的?
在准备数据集时,darknet并不要求我们预先对图片resize到固定的size. darknet自动帮我们做了图像的resize.
darknet训练前处理
本文所指的darknet版本:https://github.com/AlexeyAB/darknet
./darknet detector train data/trafficlights.data yolov3-tiny_trafficlights.cfg yolov3-tiny.conv.15
main函数位于darknet.c
训练时的入口函数为detector.c里
void train_detector(char *datacfg, char *cfgfile, char *weightfile, int *gpus, int ngpus, int clear, int dont_show, int calc_map, int mjpeg_port, int show_imgs)
{
load_args args = { 0 };
args.type = DETECTION_DATA;
args.letter_box = net.letter_box;
load_thread = load_data(args);
loss = train_network(net, train);
}
函数太长,只贴了几句关键的.注意args.type = DETECTION_DATA;
data.c中
void *load_thread(void *ptr)
{
//srand(time(0));
//printf("Loading data: %d\n", random_gen());
load_args a = *(struct load_args*)ptr;
if(a.exposure == 0) a.exposure = 1;
if(a.saturation == 0) a.saturation = 1;
if(a.aspect == 0) a.aspect = 1;
if (a.type == OLD_CLASSIFICATION_DATA){
*a.d = load_data_old(a.paths, a.n, a.m, a.labels, a.classes, a.w, a.h);
} else if (a.type == CLASSIFICATION_DATA){
*a.d = load_data_augment(a.paths, a.n, a.m, a.labels, a.classes, a.hierarchy, a.flip, a.min, a.max, a.size, a.angle, a.aspect, a.hue, a.saturation, a.exposure);
} else if (a.type == SUPER_DATA){
*a.d = load_data_super(a.paths, a.n, a.m, a.w, a.h, a.scale);
} else if (a.type == WRITING_DATA){
*a.d = load_data_writing(a.paths, a.n, a.m, a.w, a.h, a.out_w, a.out_h);
} else if (a.type == REGION_DATA){
*a.d = load_data_region(a.n, a.paths, a.m, a.w, a.h, a.num_boxes, a.classes, a.jitter, a.hue, a.saturation, a.exposure);
} else if (a.type == DETECTION_DATA){
*a.d = load_data_detection(a.n, a.paths, a.m, a.w, a.h, a.c, a.num_boxes, a.classes, a.flip, a.blur, a.mixup, a.jitter,
a.hue, a.saturation, a.exposure, a.mini_batch, a.track, a.augment_speed, a.letter_box, a.show_imgs);
} else if (a.type == SWAG_DATA){
*a.d = load_data_swag(a.paths, a.n, a.classes, a.jitter);
} else if (a.type == COMPARE_DATA){
*a.d = load_data_compare(a.n, a.paths, a.m, a.classes, a.w, a.h);
} else if (a.type == IMAGE_DATA){
*(a.im) = load_image(a.path, 0, 0, a.c);
*(a.resized) = resize_image(*(a.im), a.w, a.h);
}else if (a.type == LETTERBOX_DATA) {
*(a.im) = load_image(a.path, 0, 0, a.c);
*(a.resized) = letterbox_image(*(a.im), a.w, a.h);
} else if (a.type == TAG_DATA){
*a.d = load_data_tag(a.paths, a.n, a.m, a.classes, a.flip, a.min, a.max, a.size, a.angle, a.aspect, a.hue, a.saturation, a.exposure);
}
free(ptr);
return 0;
}
根据a.type不同,有不同的加载逻辑.在训练时,args.type = DETECTION_DATA,接着去看load_data_detection().
load_data_detection()有两套实现,用宏#ifdef OPENCV区别开来.我们看opencv版本
load_data_detection()
{
src = load_image_mat_cv(filename, flag);
image ai = image_data_augmentation(src, w, h, pleft, ptop, swidth, sheight, flip, jitter, dhue, dsat, dexp);
}
注意load_image_mat_cv()中imread读入的是bgr顺序的,用cv::cvtColor做了bgr-->rgb的转换.
if (mat.channels() == 3) cv::cvtColor(mat, mat, cv::COLOR_RGB2BGR);
这里有个让人困惑的地方,为什么是cv::COLOR_RGB2BGR而不是cv::COLOR_BGR2RGB,实际上这两个enum值是一样的,都是4.
见https://docs.opencv.org/3.1.0/d7/d1b/group__imgproc__misc.html
https://github.com/pjreddie/darknet/issues/427
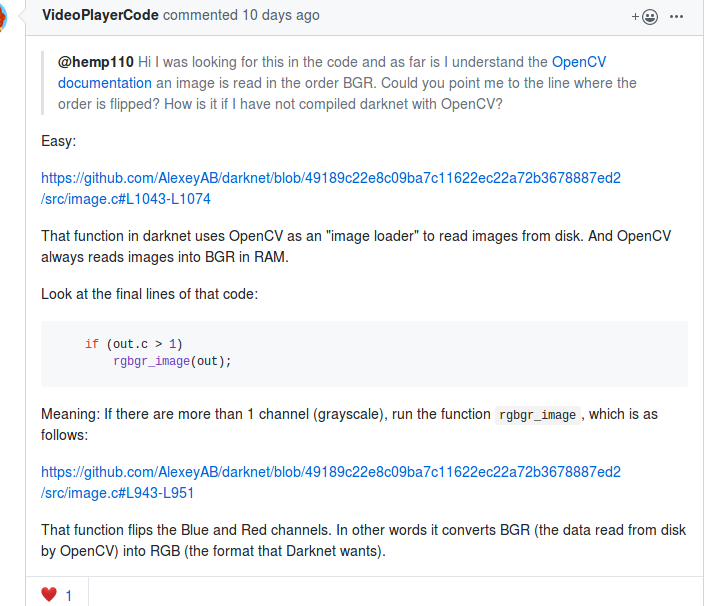
所以在做推理的时候,也应该转换到rgb的顺序.
image_data_argmentation()的主要逻辑
cv::Mat cropped(src_rect.size(), img.type());
//cropped.setTo(cv::Scalar::all(0));
cropped.setTo(cv::mean(img));
img(new_src_rect).copyTo(cropped(dst_rect));
// resize
cv::resize(cropped, sized, cv::Size(w, h), 0, 0, cv::INTER_LINEAR);
其实主要就是cv::resize. 这里cropped的img是在原图上随机截取出来的一块区域(当然是有范围的).
在load_data_detection()中有这样一段逻辑,生成pleft,pright,ptop,pbot. 这些参数被传递给image_data_argmentation(),用以截取出cropped image.
int oh = get_height_mat(src);
int ow = get_width_mat(src);
int dw = (ow*jitter);
int dh = (oh*jitter);
if(!augmentation_calculated || !track)
{
augmentation_calculated = 1;
r1 = random_float();
r2 = random_float();
r3 = random_float();
r4 = random_float();
dhue = rand_uniform_strong(-hue, hue);
dsat = rand_scale(saturation);
dexp = rand_scale(exposure);
flip = use_flip ? random_gen() % 2 : 0;
}
int pleft = rand_precalc_random(-dw, dw, r1);
int pright = rand_precalc_random(-dw, dw, r2);
int ptop = rand_precalc_random(-dh, dh, r3);
int pbot = rand_precalc_random(-dh, dh, r4);
int swidth = ow - pleft - pright;
int sheight = oh - ptop - pbot;
float sx = (float)swidth / ow;
float sy = (float)sheight / oh;
float dx = ((float)pleft/ow)/sx;
float dy = ((float)ptop /oh)/sy;
这么做的目的是,参考作者AlexeyAB大神的回复:
https://github.com/AlexeyAB/darknet/issues/3703
Your test images will not be the same as training images, so you should change training images as many times as possible. So maybe one of the modified training images of the object coincides with the test image.
这里,我此前一直有个错误的理解,在train和test时对image的preprocess应该是完全一致的.大神的回复意思是,并非如此,在train的时候应该尽可能多地使训练图片产生一些变化,因为测试图片不可能与训练图片是完全一致的,这样的话,才更有可能使测试图片与某个随机变化后的训练图片吻合.
但是之前,我在issue里有看到有人训练出来的模型效果并不好,改变了image的preprocess以后,效果就好了.这一点还有待研究.
原始的darknet里图像的preprocess用的是letterbox_image(),AlexeyAB的版本里用的是resize.据作者说这一改变使得对小目标的检测效果更好.
参考https://github.com/AlexeyAB/darknet/issues/1907 https://github.com/AlexeyAB/darknet/issues/232#issuecomment-336955485
resize()并不会保持宽高比,letterbox_image()会保持宽高比.作者认为如果你的dataset的train和test中图像分辨率一致的话,是没有必要保持宽高比的.
darknet 推导前处理
detector.c中
void test_detector(char *datacfg, char *cfgfile, char *weightfile, char *filename, float thresh,
float hier_thresh, int dont_show, int ext_output, int save_labels, char *outfile)
{
image im = load_image(input, 0, 0, net.c);
image sized = resize_image(im, net.w, net.h);
}
这里的resize_image是用C实现的,和cv::resize功能相同
/update 20190821***************/
darknet数据预处理
- 数据加载入口函数void *load_thread(void *ptr)
根据args.type不同有不同加载逻辑 - 喂给模型的输入并不是你训练图片的原始矩阵,darknet自己会做一些数据增强的操作,比如调整对比度,色相,饱和度,对图片旋转角度,翻转图像等等.
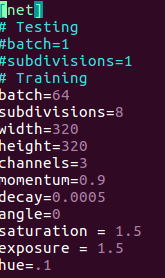
这些是配置在配置文件中的.
具体做了哪些数据增强,要自己看源代码,args.type不同,加载逻辑也略有差异
以./darknet detector train ....,即做目标检测的训练为例的话,对色相/饱和度/对比度的调整代码如下,位于image.c中

基本上前处理的代码都位于data.c,image.c中,image.c里是对图像矩阵的具体操作函数,data.c里是一些调用这些函数的控制流程.
当训练图片特别小时,不同的preprocess对喂给模型的代表图片的矩阵的影响就很大.所以最好先手动resize到模型的input size.
darknet是如何对数据集做resize的?的更多相关文章
- 深度学习入门教程UFLDL学习实验笔记二:使用向量化对MNIST数据集做稀疏自编码
今天来做UFLDL的第二个实验,向量化.我们都知道,在matlab里面基本上如果使用for循环,程序是会慢的一逼的(可以说基本就运行不下去)所以在这呢,我们需要对程序进行向量化的处理,所谓向量化就是将 ...
- 深度学习voc数据集图片resize
本人新写的3个pyhton脚本. (1)单张图片的resize: # coding = utf-8 import Image def convert(width,height): im = Image ...
- darknet YOLOv2安装及数据集训练
一. YOLOv2安装使用 1. darknet YOLOv2安装 git clone https://github.com/pjreddie/darknetcd darknetmake或到网址上下载 ...
- 对数据集做标准化处理的几种方法——基于R语言
数据集——iris(R语言自带鸢尾花包) 一.scale函数 scale函数默认的是对制定数据做均值为0,标准差为1的标准化.它的两个参数center和scale: 1)center和scale默认为 ...
- 4.keras实现-->生成式深度学习之用变分自编码器VAE生成图像(mnist数据集和名人头像数据集)
变分自编码器(VAE,variatinal autoencoder) VS 生成式对抗网络(GAN,generative adversarial network) 两者不仅适用于图像,还可以 ...
- 机器学习 — 从mnist数据集谈起
做了一些简单机器学习任务后,发现必须要对数据集有足够的了解才能动手做一些事,这是无法避免的,否则可能连在干嘛都不知道,而一些官方例程并不会对数据集做过多解释,你甚至连它长什么样都不知道... 以skl ...
- 基于pytorch实现Resnet对本地数据集的训练
本文是使用pycharm下的pytorch框架编写一个训练本地数据集的Resnet深度学习模型,其一共有两百行代码左右,分成mian.py.network.py.dataset.py以及train.p ...
- 最近用django做了个在线数据分析小网站
用最近做的理赔申请人测试数据集做了个在线分析小网站. 数据结构,算法等设置都保存在json文件里.将来对这个小破站扩充算法,只修改一下json文件就行. 当然,结果分析还是要加代码的.页面代码不贴了, ...
- ArcGIS 网络分析[8.3] 设置IDENetworkDataset的属性及INetworkDataset的对比/创建网络数据集
创建网络数据集就得有各种数据和参数,这篇文章很长,慎入. 网络分析依赖于网络数据集的质量,这句话就在这里得到了验证:复杂.精确定义. 本节目录如下: 1. INetworkDataset与IDENet ...
随机推荐
- mysql的配置和启动命令
一.mysql配置文件在linux系统下的位置 使用命令查询位置: 1.找到安装位置 which mysql -> /usr/bin/mysql 2.接下来就可以针对这个目录通过一些命令查看配 ...
- php对象在内存中创建于释放
<?php /** * 1.对象的创建占用内存, * 对象内存释放,析构方法就是在对象释放前运行最后的一步.可以自动释放和手动释放 * 手动释放:通过unset($p);来释放对象,在这个时候会 ...
- php使用webservice调用C#服务端/调用PHP服务端
由于公司业务需要,用自产平台对接某大厂MES系统,大厂提出使用webservice来互通,一脸懵逼啊,一直没有使用过php的webservice的我,瞬间打开手册开始阅读,最终爬过无数坑之后,总结出如 ...
- core文件生成和路径设置
在程序崩溃时,内核会生成一个core文件,即程序最后崩溃时的内存映像,和程序调试信息. 之后可以通过gdb,打开core文件察看程序崩溃时的堆栈信息,可以找出程序出错的代码所在文件和函数. 1.cor ...
- kafka源码分析(二)Metadata的数据结构与读取、更新策略
一.基本思路 异步发送的基本思路就是:send的时候,KafkaProducer把消息放到本地的消息队列RecordAccumulator,然后一个后台线程Sender不断循环,把消息发给Kafka集 ...
- java高并发系列 - 第6天:线程的基本操作
新建线程 新建线程很简单.只需要使用new关键字创建一个线程对象,然后调用它的start()启动线程即可. Thread thread1 = new Thread1(); t1.start(); 那么 ...
- 浅入深出Vue:注册
基本布局已经有了, 现在我们来开始做我们的注册页面~ 当然需要注册才能发表文章啊(糟老头子坏得很, 我可以只有我一个人能发啊). 这里我们设定只有注册才能发表文章,也就淡化了管理员这个概念.在开发中先 ...
- xfs 文件系统修复
pvcreate /dev/sdb1 pvcreate /dev/sdc1 pvcreate /dev/sdd1 vgcreate vg_bricks /dev/sdb1 vgcreate vg_br ...
- infiniband install driver
硬件:Mellanox InfiniBand,主要包括 HCA(主机通道适配器)和交换机两部分 软件:CentOS 6.4 MLNX_OFED_LINUX-2.1-1.0.0-rhel6.4-x86_ ...
- .net持续集成cake篇之cake任务依赖、自定义配置荐及环境变量读取
系列目录 新建一个构建任务及任务依赖关系设置 上节我们通过新建一个HelloWorld示例讲解了如何编写build.cake以及如何下载build.ps1启动文件以及如何运行.实际项目中,我们使用最多 ...