Storm 系列(四)—— Storm 集群环境搭建
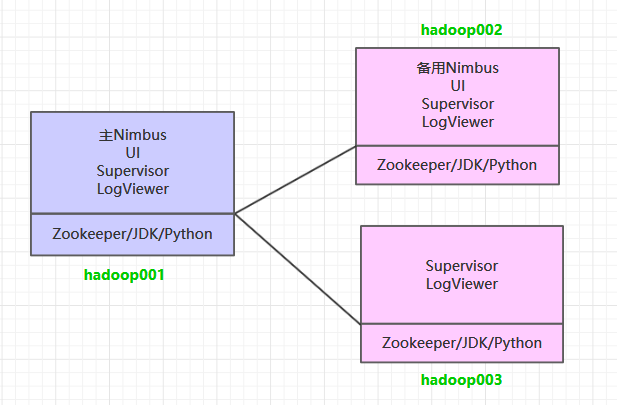
一、集群规划
这里搭建一个 3 节点的 Storm 集群:三台主机上均部署 Supervisor 和 LogViewer 服务。同时为了保证高可用,除了在 hadoop001 上部署主 Nimbus 服务外,还在 hadoop002 上部署备用的 Nimbus 服务。Nimbus 服务由 Zookeeper 集群进行协调管理,如果主 Nimbus 不可用,则备用 Nimbus 会成为新的主 Nimbus。
二、前置条件
Storm 运行依赖于 Java 7+ 和 Python 2.6.6 +,所以需要预先安装这两个软件。同时为了保证高可用,这里我们不采用 Storm 内置的 Zookeeper,而采用外置的 Zookeeper 集群。由于这三个软件在多个框架中都有依赖,其安装步骤单独整理至 :
三、集群搭建
1. 下载并解压
下载安装包,之后进行解压。官方下载地址:http://storm.apache.org/downloads.html
# 解压
tar -zxvf apache-storm-1.2.2.tar.gz
2. 配置环境变量
# vim /etc/profile添加环境变量:
export STORM_HOME=/usr/app/apache-storm-1.2.2
export PATH=$STORM_HOME/bin:$PATH使得配置的环境变量生效:
# source /etc/profile3. 集群配置
修改 ${STORM_HOME}/conf/storm.yaml 文件,配置如下:
# Zookeeper集群的主机列表
storm.zookeeper.servers:
- "hadoop001"
- "hadoop002"
- "hadoop003"
# Nimbus的节点列表
nimbus.seeds: ["hadoop001","hadoop002"]
# Nimbus和Supervisor需要使用本地磁盘上来存储少量状态(如jar包,配置文件等)
storm.local.dir: "/home/storm"
# workers进程的端口,每个worker进程会使用一个端口来接收消息
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703supervisor.slots.ports 参数用来配置 workers 进程接收消息的端口,默认每个 supervisor 节点上会启动 4 个 worker,当然你也可以按照自己的需要和服务器性能进行设置,假设只想启动 2 个 worker 的话,此处配置 2 个端口即可。
4. 安装包分发
将 Storm 的安装包分发到其他服务器,分发后建议在这两台服务器上也配置一下 Storm 的环境变量。
scp -r /usr/app/apache-storm-1.2.2/ root@hadoop002:/usr/app/
scp -r /usr/app/apache-storm-1.2.2/ root@hadoop003:/usr/app/四. 启动集群
4.1 启动ZooKeeper集群
分别到三台服务器上启动 ZooKeeper 服务:
zkServer.sh start4.2 启动Storm集群
因为要启动多个进程,所以统一采用后台进程的方式启动。进入到 ${STORM_HOME}/bin 目录下,执行下面的命令:
hadoop001 & hadoop002 :
# 启动主节点 nimbus
nohup sh storm nimbus &
# 启动从节点 supervisor
nohup sh storm supervisor &
# 启动UI界面 ui
nohup sh storm ui &
# 启动日志查看服务 logviewer
nohup sh storm logviewer &hadoop003 :
hadoop003 上只需要启动 supervisor 服务和 logviewer 服务:
# 启动从节点 supervisor
nohup sh storm supervisor &
# 启动日志查看服务 logviewer
nohup sh storm logviewer &4.3 查看集群
使用 jps 查看进程,三台服务器的进程应该分别如下:

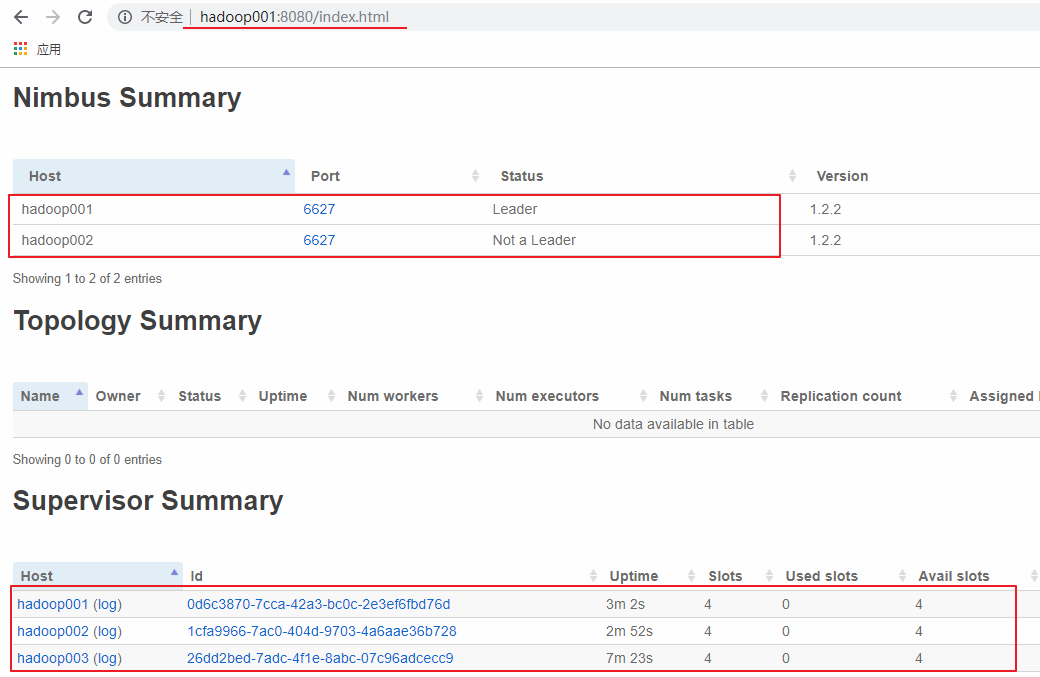
访问 hadoop001 或 hadoop002 的 8080 端口,界面如下。可以看到有一主一备 2 个 Nimbus 和 3 个 Supervisor,并且每个 Supervisor 有四个 slots,即四个可用的 worker 进程,此时代表集群已经搭建成功。
五、高可用验证
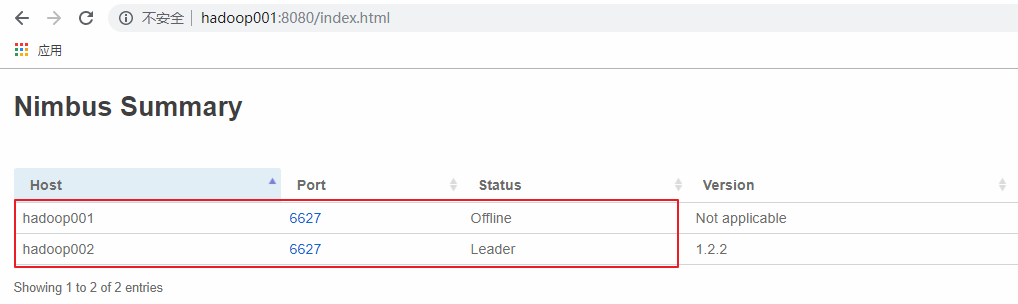
这里手动模拟主 Nimbus 异常的情况,在 hadoop001 上使用 kill 命令杀死 Nimbus 的线程,此时可以看到 hadoop001 上的 Nimbus 已经处于 offline 状态,而 hadoop002 上的 Nimbus 则成为新的 Leader。
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Storm 系列(四)—— Storm 集群环境搭建的更多相关文章
- Storm 学习之路(四)—— Storm集群环境搭建
一.集群规划 这里搭建一个3节点的Storm集群:三台主机上均部署Supervisor和LogViewer服务.同时为了保证高可用,除了在hadoop001上部署主Nimbus服务外,还在hadoop ...
- Storm —— 集群环境搭建
一.集群规划 这里搭建一个3节点的Storm集群:三台主机上均部署Supervisor和LogViewer服务.同时为了保证高可用,除了在hadoop001上部署主Nimbus服务外,还在hadoop ...
- 一:Storm集群环境搭建
第一:storm集群环境准备及部署[1]硬件环境准备--->机器数量>=3--->网卡>=1--->内存:尽可能大--->硬盘:无额外需求[2]软件环境准备---& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十二)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。
Centos7出现异常:Failed to start LSB: Bring up/down networking. 按照<Kafka:ZK+Kafka+Spark Streaming集群环境搭 ...
- ZooKeeper 系列(二)—— Zookeeper单机环境和集群环境搭建
一.单机环境搭建 1.1 下载 1.2 解压 1.3 配置环境变量 1.4 修改配置 1.5 启动 1. ...
- ZooKeeper系列(二)—— Zookeeper 单机环境和集群环境搭建
一.单机环境搭建 1.1 下载 下载对应版本 Zookeeper,这里我下载的版本 3.4.14.官方下载地址:https://archive.apache.org/dist/zookeeper/ # ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- HBase —— 集群环境搭建
一.集群规划 这里搭建一个3节点的HBase集群,其中三台主机上均为Regin Server.同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002上部署备用的 ...
- Spark 1.6.1分布式集群环境搭建
一.软件准备 scala-2.11.8.tgz spark-1.6.1-bin-hadoop2.6.tgz 二.Scala 安装 1.master 机器 (1)下载 scala-2.11.8.tgz, ...
随机推荐
- 【数据结构学习】关于HashMap的那些事儿
涉及数据结构 红黑树 链表 哈希 从CRUD说起 预热知识: DEFAULT_INITIAL_CAPACITY = 1 << 4, HashMap默认容量为16(n << m意 ...
- Spark 系列(四)—— RDD常用算子详解
一.Transformation spark 常用的 Transformation 算子如下表: Transformation 算子 Meaning(含义) map(func) 对原 RDD 中每个元 ...
- 理解MySQL(一)--MySQL介绍
一.Mysql逻辑架构: 1. 第一层:服务器层的服务,连接\线程处理. 2. 第二层:查询执行引擎,MySQL的核心服务功能,包括查询解析.分析.优化和缓存,所有跨存储引擎的功能都在这一层实现. 3 ...
- android——SQLite数据库存储(操作)
public class MyDatabaseHelper extends SQLiteOpenHelper { //把定义SQL建表语句成字符串常量 //图书的详细信息 //ID.作者.价格.页数. ...
- 在linux系统下安装mysql详解,以及远程调用连接不上mysql的解决方法。
步骤: 1)查看CentOS自带的mysql 输入 rpm -qa | grep mysql 2)将自带的mysql卸载 3)上传Mysql的安装包到linux 4)安装mysql的依赖(不是必须) ...
- Zabbix4.0安装浅谈
一.此篇文章存在意义 针对超级小白,大神绕过 在zabbix官网https://www.zabbix.com/download里,需要数据库,但是并没有指导小白的我们如何安装数据库,此文章包含了Mys ...
- 纯数据结构Java实现(3/11)(链表)
题外话: 篇幅停了一下,特意去看看其他人写的类似的内容:然后发现类似博主喜欢画图,喜欢讲解原理. (于是我就在想了,理解数据结构的确需要画图,但我的文章写给懂得人看,只配少量图即可,省事儿) 下面正题 ...
- python的魔术方法大全
在Python中,所有以“__”双下划线包起来的方法,都统称为“Magic Method”(魔术方法),例如类的初始化方法 __init__ ,Python中所有的魔术方法均在官方文档中有相应描述,这 ...
- Nacos(九):Nacos集群部署和遇到的问题
前言 前面的系列文章已经介绍了Nacos的如何接入SpringCloud,以及Nacos的基本使用方式 之前的文章中都是基于单机模式部署进行讲解的,本文对Nacos的集群部署方式进行说明 环境准备 J ...
- jvm系列(六):Java服务GC参数调优案例
本文介绍了一次生产环境的JVM GC相关参数的调优过程,通过参数的调整避免了GC卡顿对JAVA服务成功率的影响. 这段时间在整理jvm系列的文章,无意中发现本文,作者思路清晰通过步步分析最终解决问题. ...