Hadoop 之 深入探索MapReduce
1.MapReduce基础概念
答:MapReduce作业时一种大规模数据的并行计算的便程模型。我们可以将HDFS中存储的海量数据,通过MapReduce作业进行计算,得到目标数据。
2.MapReduce的四个阶段
答:Split阶段、Map阶段(需要编码)、Shuffle阶段、Reduce阶段(需要编码),下面以WordCount为例。
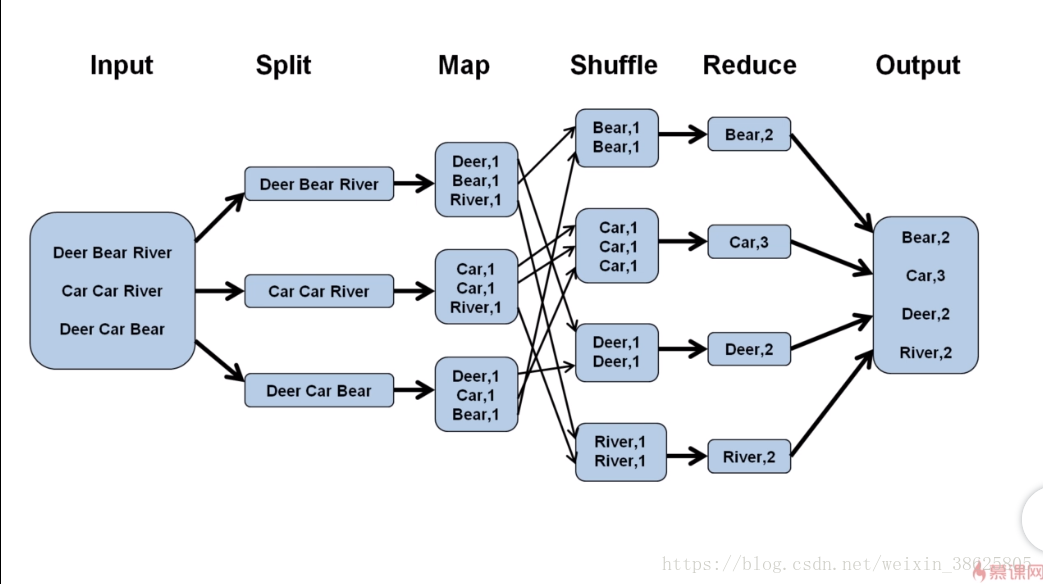
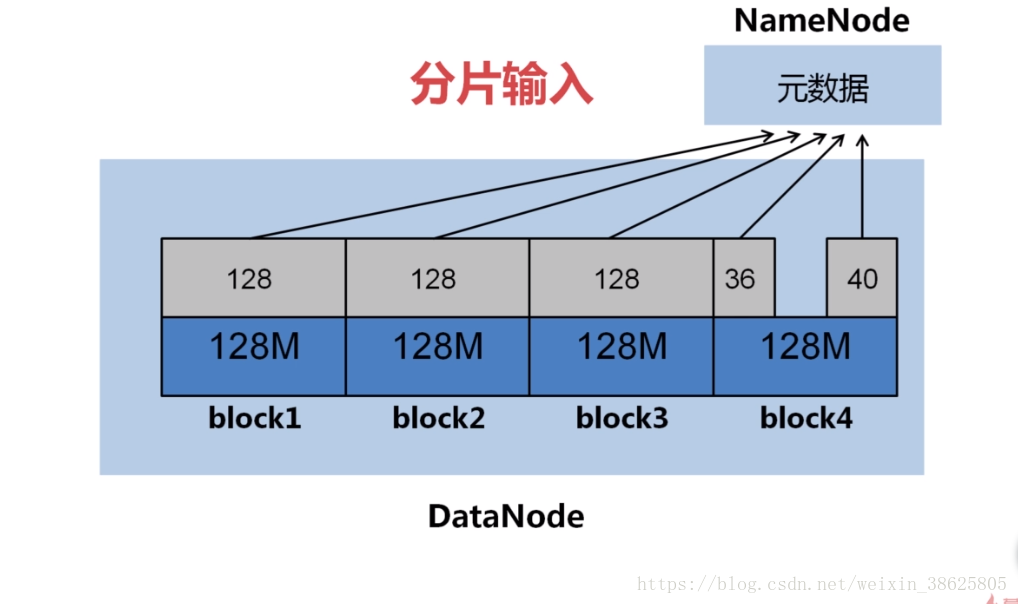
3.从分片到Map
答:我们知道输入的文件时存在DataNode的block之中,Hadoop1.0默认的block大小为64M,Hadoop2.0大小为128M,可以在hdfs-site.xml中设置参数:dfs.block.size。

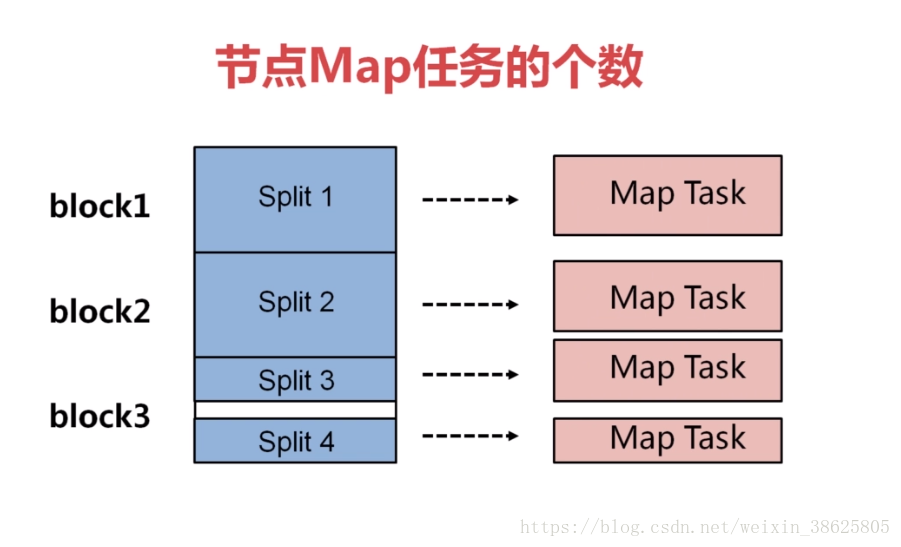

4.控制Map任务的个数在一个合理的范围之内

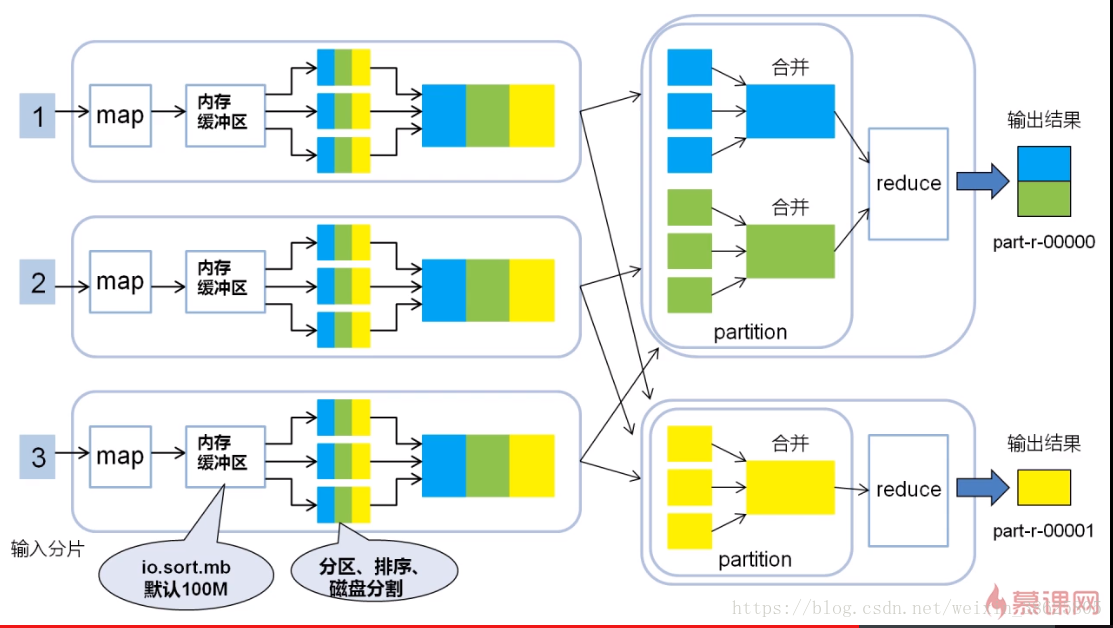
5.Map——Shuffle——Reduce




Hadoop 之 深入探索MapReduce的更多相关文章
- Hadoop化繁为简(三)—探索Mapreduce简要原理与实践
目录-探索mapreduce 1.Mapreduce的模型简介与特性?Yarn的作用? 2.mapreduce的工作原理是怎样的? 3.配置Yarn与Mapreduce.演示Mapreduce例子程序 ...
- 化繁为简(三)—探索Mapreduce简要原理与实践
目录-探索mapreduce 1.Mapreduce的模型简介与特性?Yarn的作用? 2.mapreduce的工作原理是怎样的? 3.配置Yarn与Mapreduce.演示Mapreduce例子程序 ...
- 【hadoop代码笔记】Mapreduce shuffle过程之Map输出过程
一.概要描述 shuffle是MapReduce的一个核心过程,因此没有在前面的MapReduce作业提交的过程中描述,而是单独拿出来比较详细的描述. 根据官方的流程图示如下: 本篇文章中只是想尝试从 ...
- 大数据时代之hadoop(五):hadoop 分布式计算框架(MapReduce)
大数据时代之hadoop(一):hadoop安装 大数据时代之hadoop(二):hadoop脚本解析 大数据时代之hadoop(三):hadoop数据流(生命周期) 大数据时代之hadoop(四): ...
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
转自:http://blog.csdn.net/iamdll/article/details/20998035 分类: 分布式 2014-03-11 10:31 156人阅读 评论(0) 收藏 举报 ...
- 3.Hadoop测试Yarn和MapReduce
Hadoop测试Yarn和MapReduce 1.配置Yarn (1)配置ResourceManager 生产环境中,一般是重开一台机器作为ResourceManager,这里我们以Master机器代 ...
- [b0013] Hadoop 版hello word mapreduce wordcount 运行(三)
目的: 不用任何IDE,直接在linux 下输入代码.调试执行 环境: Linux Ubuntu Hadoop 2.6.4 相关: [b0012] Hadoop 版hello word mapred ...
- [b0012] Hadoop 版hello word mapreduce wordcount 运行(二)
目的: 学习Hadoop mapreduce 开发环境eclipse windows下的搭建 环境: Winows 7 64 eclipse 直接连接hadoop运行的环境已经搭建好,结果输出到ecl ...
随机推荐
- Collectors.toMap不允许Null Value导致NPE
背景 线上某任务出现报警,报错日志如下: java.lang.NullPointerException: null at java.util.HashMap.merge(HashMap.java:12 ...
- layui下拉框不显示的问题
1.先检查有没有引入layui.js 2.然后看有没有被<form class="layui-form"></form>包住, 3.查看是否有以下代码 &l ...
- 解决ionic 中 $ionicHistory.goBack()无法返回
这种解决方法目前只适合用了 <ion-side-menus>这一组件的<ion-view> 解决方法: 在<ion-view>下一级中包一个div,如下图: 搞了几 ...
- Nginx入门(二):镜像和容器
0.docker常用命令 #镜像名 版本标签 镜像id 创建时间 镜像大小 REPOSITORY TAG IMAGE ID CREATED SIZE hello-world latest fce289 ...
- window下 局域网内使用mysql,mysql 开启远程访问权限
一.window 10 开启3306端口 1.按win键选择设置 2.搜索防火墙 3.选择高级设置 3.右键入站规则->新建规则 4.按照提示,规则类型选择端口,应用于tcp,特定本地端口输入3 ...
- 关于dijkstra的优化 及 多源最短路
先来看这样一道题目 给你N个点,M条双向边,要求求出1号点到其他所有点的距离.其中 2 <= N <= 1e5, 1 <=M <= 1e6. 对于这样的一道题目 我们当然不可 ...
- lightoj 1084 - Winter(dp+二分+线段树or其他数据结构)
题目链接:http://www.lightoj.com/volume_showproblem.php?problem=1084 题解:不妨设dp[i] 表示考虑到第i个点时最少有几组那么 if a[i ...
- HDU 5451 Best Solver 数论 快速幂 2015沈阳icpc
Best Solver Time Limit: 1500/1000 MS (Java/Others) Memory Limit: 65535/102400 K (Java/Others)Tota ...
- 51nod 1257 背包问题 V3(这不是背包问题是二分)
题目链接:https://www.51nod.com/onlineJudge/questionCode.html#!problemId=1257 题解:不能按照单位价值贪心,不然连样例都过不了 要求的 ...
- Dinic算法学习
转自 此文虽为转载,但博主的网络流就是从这开始的,认为写的不错 网络流基本概念 什么是网络流 在一个有向图上选择一个源点,一个汇点,每一条边上都有一个流量上限(以下称为容量),即经过这条边的流量不能超 ...