UI控件之 ScrollView垂直滚动控件 和 HorizontalScrollView水平滚动控件的使用
关于倒排索引
搜索引擎通常检索的场景是:给定几个关键词,找出包含关键词的文档。
怎么快速找到包含某个关键词的文档就成为搜索的关键。这里我们借助单词——文档矩阵模型,通过这个模型我们可以很方便知道某篇文档包含哪些关键词,某个关键词被哪些文档所包含。
单词-文档矩阵的具体数据结构可以是倒排索引、签名文件、后缀树等。
倒排索引源于实际应用中需要根据属性的值来查找记录,lucene是基于倒排索引实现的。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。
由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。
带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。
倒排索引一般表示为一个关键词,然后是它的频度(出现的次数),位置(出现在哪一篇文章或网页中,及有关的日期,作者等信息),它相当于为互联网上几千亿页网页做了一个索引,好比一本书的目录、标签一般。读者想看哪一个主题相关的章节,直接根据目录即可找到相关的页面。不必再从书的第一页到最后一页,一页一页的查找。
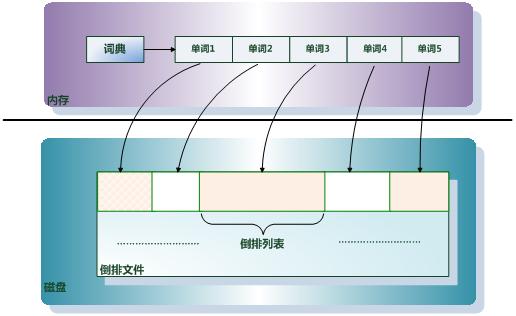
倒排索引由两个部分组成:单词词典和倒排文件。
倒排文件
所有单词的倒排列表顺序的存储在磁盘的某个文件里,这个文件即被称为倒排文件,倒排文件是存储倒排索引的物理文件。
单词词典
单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
单词词典是倒排索引中非常重要的组成部分,它是用来维护文档集合中所有单词的相关信息,同时用来记载某个单词对应的倒排列表在倒排文件中的位置信息。在支持搜索时,根据用户的查询词,去单词词典里查询,就能够获得相应的倒排列表。
对于一个规模很大的文档集合来说,可能包含了几十万甚至上百万的不同单词,
快速定位某个单词直接决定搜索的响应速度,所以我们需要很高效的数据结构对单词词典进行构建和查找。
常用的数据结构包含哈希加链表和树形词典结构。
Lucene倒排索引原理
Lucerne使用的是倒排文件索引结构。该结构及相应的生成算法如下:
设有两篇文章1和2:
文章1的内容为:Tom lives in Guangzhou,I live in Guangzhou too.
文章2的内容为:He once lived in Shanghai.
<1>取得关键词
由于lucene是基于关键词索引和查询的,首先我们要取得这两篇文章的关键词,通常我们需要如下处理措施:
a.我们现在有的是文章内容,即一个字符串,我们先要找出字符串中的所有单词,即分词。英文单词由于用空格分隔,比较好处理。中文单词间是连在一起的需要特殊的分词处理。
b.文章中的”in”, “once” “too”等词没有什么实际意义,中文中的“的”“是”等字通常也无具体含义,这些不代表概念的词可以过滤掉
c.用户通常希望查“He”时能把含“he”,“HE”的文章也找出来,所以所有单词需要统一大小写。
d.用户通常希望查“live”时能把含“lives”,“lived”的文章也找出来,所以需要把“lives”,“lived”还原成“live”
e.文章中的标点符号通常不表示某种概念,也可以过滤掉
在lucene中以上措施由Analyzer类完成。 经过上面处理后,
文章1的所有关键词为:[tom] [live] [guangzhou] [i] [live] [guangzhou]
文章2的所有关键词为:[he] [live] [shanghai]
<2>建立倒排索引
有了关键词后,我们就可以建立倒排索引了。上面的对应关系是:“文章号”对“文章中所有关键词”。倒排索引把这个关系倒过来,变成: “关键词”对“拥有该关键词的所有文章号”。
文章1,2经过倒排后变成
关键词 文章号 guangzhou 1 he 2 i 1 live 1,2 shanghai 2 tom 1 通常仅知道关键词在哪些文章中出现还不够,我们还需要知道关键词在文章中出现次数和出现的位置,通常有两种位置:
a.字符位置,即记录该词是文章中第几个字符(优点是关键词亮显时定位快);
b.关键词位置,即记录该词是文章中第几个关键词(优点是节约索引空间、词组(phase)查询快),lucene中记录的就是这种位置。
加上“出现频率”和“出现位置”信息后,我们的索引结构变为:
|
1
2
3
4
5
6
7
8
|
关键词 文章号[出现频率] 出现位置 guangzhou 1[2] 3,6 he 2[1] 1 i 1[1] 4 live 1[2] 2,5, 2[1] 2 shanghai 2[1] 3 tom 1[1] 1 |
以live 这行为例我们说明一下该结构:live在文章1中出现了2次,文章2中出现了一次,它的出现位置为“2,5,2”这表示什么呢?我们需要结合文章号和出现频率来分析,文章1中出现了2次,那么“2,5”就表示live在文章1中出现的两个位置,文章2中出现了一次,剩下的“2”就表示live是文章2中第 2个关键字。
以上就是lucene索引结构中最核心的部分。我们注意到关键字是按字符顺序排列的(lucene没有使用B树结构),因此lucene可以用二分搜索算法快速定位关键词。
<3>实现
实现时,lucene将上面三列分别作为词典文件(Term Dictionary)、频率文件(frequencies)、位置文件 (positions)保存。其中词典文件不仅保存有每个关键词,还保留了指向频率文件和位置文件的指针,通过指针可以找到该关键字的频率信息和位置信息。
Lucene中使用了field的概念,用于表达信息所在位置(如标题中,文章中,url中),在建索引中,该field信息也记录在词典文件中,每个关键词都有一个field信息(因为每个关键字一定属于一个或多个field)。
<4>压缩算法
为了减小索引文件的大小,Lucene对索引还使用了压缩技术。
首先,对词典文件中的关键词进行了压缩,关键词压缩为<前缀长度,后缀>,例如:当前词为“阿拉伯语”,上一个词为“阿拉伯”,那么“阿拉伯语”压缩为<3,语>。
其次大量用到的是对数字的压缩,数字只保存与上一个值的差值(这样可以减小数字的长度,进而减少保存该数字需要的字节数)。例如当前文章号是16389(不压缩要用3个字节保存),上一文章号是16382,压缩后保存7(只用一个字节)。
<5>应用原因
下面我们可以通过对该索引的查询来解释一下为什么要建立索引。
假设要查询单词 “live”,lucene先对词典二元查找、找到该词,通过指向频率文件的指针读出所有文章号,然后返回结果。词典通常非常小,因而,整个过程的时间是毫秒级的。
而用普通的顺序匹配算法,不建索引,而是对所有文章的内容进行字符串匹配,这个过程将会相当缓慢,当文章数目很大时,时间往往是无法忍受的。
整理自
UI控件之 ScrollView垂直滚动控件 和 HorizontalScrollView水平滚动控件的使用的更多相关文章
- HorizontalScrollView水平滚动控件
HorizontalScrollView水平滚动控件 一.简介 用法ScrollView大致相同 二.方法 1)HorizontalScrollView水平滚动控件使用方法 1.在layout布局文件 ...
- iframe的滚动栏问题:显示/隐藏滚动栏
iframe 问题2008-01-22 16:37****** 显示 iframe 内容 XHTML 1.0 Transitional 标准不能显示 <!DOCTYPE html PUBLI ...
- ScrollView垂直滚动控件
ScrollView垂直滚动控件 一.简介 二.方法 1)ScrollView垂直滚动控件使用方法 1.在layout布局文件的最外层建立一个ScrollView控件 2.在ScrollView控件中 ...
- WPF中获取TreeView以及ListView获取其本身滚动条的方法,可实现自行调节scoll滚动的位置(可相应获取任何控件中的内部滚动条)
原文:WPF中获取TreeView以及ListView获取其本身滚动条的方法,可实现自行调节scoll滚动的位置(可相应获取任何控件中的内部滚动条) 对于TreeView而言: TreeViewAut ...
- Android-动态添加控件到ScrollView
在实际开发过程中,会需要动态添加控件到ScrollView,就需要在Java代码中,找到ScrollView的孩子(ViewGroup),进行添加即可. Layout: <?xml versio ...
- Android 解决下拉刷新控件和ScrollVIew的滑动冲突问题。
最近项目要实现ScrollView中嵌套广告轮播图+RecyleView卡片布局,并且RecyleView按照header和内容的排列样式,因为RecyleView的可扩展性很强,所以我毫无疑问的选择 ...
- 【摸鱼神器】UI库秒变低代码工具——表单篇(二)子控件
上一篇介绍了表单控件,这一篇介绍一下表单里面的各种子控件的封装方式. 主要内容 需求分析 子控件的分类 子控件属性的分类 定义 interface. 定义子控件的的 props. 定义 json 文件 ...
- android基本控件学习-----ScrollView
ScrollView(滚动条)的讲解: 一.对于ScrollView滚动条还是很好理解的,共有两种水平和垂直,ScrollView和HorizontalScrollview,这个里面不知道该总结写什么 ...
- android控件拖动,移动、解决父布局重绘时控件回到原点
这是主要代码: 保证其params发生改变,相对于父布局的位置就能达到位置移动到原来的位置 // 每次移动都要设置其layout,不然由于父布局可能嵌套listview,当父布局发生改变冲毁(如下拉刷 ...
随机推荐
- Javascript的9张思维导图学习
思维导图小tips:思维导图又叫心智图,是表达发射性思维的有效的图形思维工具 ,它简单却又极其有效,是一种革命性的思维工具.思维导图运用图文并重的技巧,把各级主题的关系用相互隶属与相关的层级图表现出来 ...
- 2013 Multi-University Training Contest 2 Balls Rearrangement
先算出lcm(a,b),如果lcm>=n,则直接暴力解决:否则分段,求出0-lcm内的+0-n%lcm内的值. 再就是连续相同的一起计算!! #include<iostream> # ...
- lintcode 中等题:subSets 子集
题目 子集 给定一个含不同整数的集合,返回其所有的子集 样例 如果 S = [1,2,3],有如下的解: [ [3], [1], [2], [1,2,3], [1,3], [2,3], [1,2], ...
- Eliza Doolittle lyrics Big City
Eliza Doolittle lyrics Big City 歌词很好,现在还没有,以后添加进来.
- Drawable(5)关于从资源文件构造的Drawable不显示
要给它设置个bounds才可以 TextView noticeHeaderView; TextView headerRefreshText; ProgressBar headerRefreshPgrs ...
- OPENGL画图类库
链接 https://www.opengl.org/wiki/Language_bindings http://blog.csdn.net/luozhuang/article/details/421 ...
- Lucas定理学习小记
(1)Lucas定理:p为素数,则有: (2)证明: n=(ak...a2,a1,a0)p = (ak...a2,a1)p*p + a0 = [n/p]*p+a0,m=[m/p]*p+b0其次,我们 ...
- [原]用WebBrowser组件模拟人工运行搜索引擎自动点击搜索结果的实验
本代码只是业余时间无聊写着试试,用WebBrowser组件模拟人工运行搜索引擎自动点击搜索结果的实验 这是网络中盛传的提高搜索引擎点击率的一种方式,当然属于作弊,不推荐各位使用.另外这种方式的性能不佳 ...
- 1934. Black Spot(spfa)
1934 水题 RE了N久 后来发现是无向图 #include <iostream> #include<cstring> #include<algorithm> # ...
- poj 3101 Astronomy (java 分数的最小公倍数 gcd)
题目链接 要用大数,看了别人的博客,用java写的. 题意:求n个运动周期不完全相同的天体在一条直线上的周期. 分析:两个星球周期为a,b.则相差半周的长度为a*b/(2*abs(a-b)),对于n个 ...