为编写网络爬虫程序安装Python3.5
1. 下载Python3.5.1安装包
1.1 进入python官网,点击menu->downloads,网址:https://www.python.org/downloads/
1.2 根据系统选择32位还是64位,这里下载的可执行exe为64位安装包
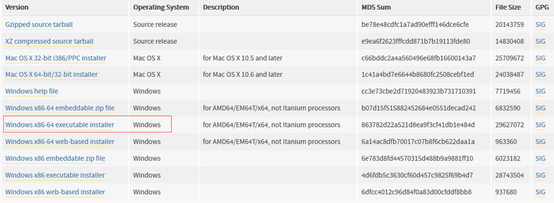
2. 安装Python3.5
2.1 双击打开安装包,选择自定义路径(注意安装路径中尽量不要含有有中文或者空格),然后选中Add Python 3.5 to PATH(将Python安装路径添加到系统变量Path中,这样做以后在任意目录下都可以执行pyhton命令了)

2.2 默认全选,Next
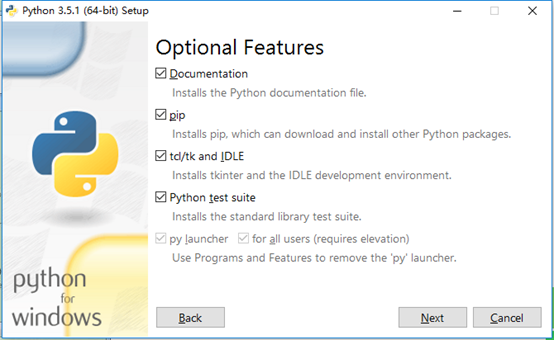
2.3 修改安装路径,勾选加上Install for all user为所有用户安装和Precompile standard library 预编译标准库,然后点击Install
2.4 等待安装完成

2.5 验证,使用快捷键win + R 或 右键开始选择运行,输入cmd回车,打开命令提示符窗口,然后输入python->回车,若出现python版本信息则软件安装完成
3. 简单实践,敲一个简单小爬虫程序
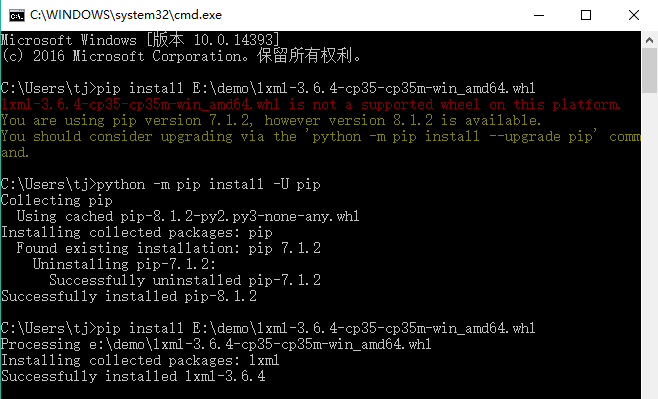
3.1 安装lxml库,由于直接使用pip lxml 对于3.0x以上的版本来说经常会出现版本不适应而失败,所以这里介绍直接使用whl文件安装
3.1.1 下载对应python3.5版本的lxml库,下载网址:http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml

3.1.2 同检查python是否安装成功一样,使用快捷键win + R 或 右键开始选择运行,输入cmd回车,打开命令提示符窗口,然后
pip install E:\demo\lxml-3.6.4-cp35-cp35m-win_amd64.whl(下载的lxml库whl文件存放路径)
可能碰到问题,pip的版本低了,需要更新一下pip的版本。更新pip版本命令:
python -m pip install -U pip
更新完成后,再次使用pip命令:
pip install E:\demo\lxml-3.6.4-cp35-cp35m-win_amd64.whl
3.2 Lxml库安装成功后,环境就准备好了, 可以开始敲代码了
3.2.1 引入Gooseeker规则提取器模块gooseeker.py(引入该模块的原因和价值 ),在自定义目录下创建gooseeker.py文件,如:这里为E:\Demo\gooseeker.py,再以记事本打开,复制下面的代码粘贴
),在自定义目录下创建gooseeker.py文件,如:这里为E:\Demo\gooseeker.py,再以记事本打开,复制下面的代码粘贴
#!/usr/bin/python
# -*- coding: utf-8 -*-
# 模块名: gooseeker
# 类名: GsExtractor
# Version: 2.0
# 说明: html内容提取器
# 功能: 使用xslt作为模板,快速提取HTML DOM中的内容。
# github: https://github.com/FullerHua/jisou/core/gooseeker.py from urllib import request
from urllib.parse import quote
from lxml import etree
import time class GsExtractor(object):
def _init_(self):
self.xslt = ""
# 从文件读取xslt
def setXsltFromFile(self , xsltFilePath):
file = open(xsltFilePath , 'r' , encoding='UTF-8')
try:
self.xslt = file.read()
finally:
file.close()
# 从字符串获得xslt
def setXsltFromMem(self , xsltStr):
self.xslt = xsltStr
# 通过GooSeeker API接口获得xslt
def setXsltFromAPI(self , APIKey , theme, middle=None, bname=None):
apiurl = "http://www.A.com/api/getextractor?key="+ APIKey +"&theme="+quote(theme) 这里要将A替换成gooseeker
if (middle):
apiurl = apiurl + "&middle="+quote(middle)
if (bname):
apiurl = apiurl + "&bname="+quote(bname)
apiconn = request.urlopen(apiurl)
self.xslt = apiconn.read()
# 返回当前xslt
def getXslt(self):
return self.xslt
# 提取方法,入参是一个HTML DOM对象,返回是提取结果
def extract(self , html):
xslt_root = etree.XML(self.xslt)
transform = etree.XSLT(xslt_root)
result_tree = transform(html)
return result_tree
# 提取方法,入参是html源码,返回是提取结果
def extractHTML(self , html):
doc = etree.HTML(html)
return self.extract(doc)
3.2.2 在提取器模块gooseeker.py同级目录下创建一个.py后缀文件,如这里为E:\Demo\first.py,再以记事本打开,敲入代码:
# -*- coding: utf-8 -*-
# 使用gsExtractor类的示例程序
# 访问集搜客论坛,以xslt为模板提取论坛内容
# xslt保存在xslt_bbs.xml中
# 采集结果保存在result.xml中 import os
from urllib import request
from lxml import etree
from gooseeker import GsExtractor # 访问并读取网页内容
url = "http://www.A.B/cn/forum/7" #这里要将A和B分别替换为gooseeker和com
conn = request.urlopen(url)
doc = etree.HTML(conn.read()) bbsExtra = GsExtractor()
bbsExtra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e" , "gooseeker_bbs_xslt") # 设置xslt抓取规则
result = bbsExtra.extract(doc) # 调用extract方法提取所需内容 # 当前目录
current_path = os.getcwd()
file_path = current_path + "/result.xml" # 保存结果
open(file_path,"wb").write(result) # 打印出结果
print(str(result).encode('gbk','ignore').decode('gbk'))
3.2.3 执行first.py,使用快捷键win + R 或 右键开始选择运行,输入cmd回车,打开命令提示窗口,进入first.py文件所在目录,输入命令 :python first.py 回车
3.2.4 查看保存结果文件,进入first.py文件所在目录,查看名称为result的xml文件(即采集结果)
4. 总结
安装步骤还是很简单,主要需要注意的是:
1. 对应系统版本安装;
2. 将安装路径加入系统环境变量Path。
后面将会讲到如何结合Scrapy快速开发Python爬虫。
5. 集搜客GooSeeker开源代码下载源
6. 文章修改历史
2016-10-20:V1.0
为编写网络爬虫程序安装Python3.5的更多相关文章
- Android网络爬虫程序(基于Jsoup)
摘要:基于 Jsoup 实现一个 Android 的网络爬虫程序,抓取网页的内容并显示出来.写这个程序的主要目的是抓取海投网的宣讲会信息(公司.时间.地点)并在移动端显示,这样就可以随时随地的浏览在学 ...
- python3编写网络爬虫20-pyspider框架的使用
二.pyspider框架的使用 简介 pyspider是由国人binux 编写的强大的网络爬虫系统 github地址 : https://github.com/binux/pyspider 官方文档 ...
- python3编写网络爬虫23-分布式爬虫
一.分布式爬虫 前面我们了解Scrapy爬虫框架的基本用法 这些框架都是在同一台主机运行的 爬取效率有限 如果多台主机协同爬取 爬取效率必然成倍增长这就是分布式爬虫的优势 1. 分布式爬虫基本原理 1 ...
- 利用Python编写网络爬虫下载文章
#coding: utf-8 #title..href... str0='blabla<a title="<论电影的七个元素>——关于我对电影的一些看法以及<后会无期 ...
- 使用Python写的第一个网络爬虫程序
今天尝试使用python写一个网络爬虫代码,主要是想訪问某个站点,从中选取感兴趣的信息,并将信息依照一定的格式保存早Excel中. 此代码中主要使用到了python的以下几个功能,因为对python不 ...
- 吴裕雄--天生自然python学习笔记:编写网络爬虫代码获取指定网站的图片
我们经常会在网上搜索井下载图片,然而一张一张地下载就太麻烦了,本案例 就是通过网络爬虫技术, 一次性下载该网站所有的图片并保存 . 网站图片下载并保存 将指定网站的 .jpg 和 .png 格式的图片 ...
- python3编写网络爬虫18-代理池的维护
一.代理池的维护 上面我们利用代理可以解决目标网站封IP的问题 在网上有大量公开的免费代理 或者我们也可以购买付费的代理IP但是无论是免费的还是付费的,都不能保证都是可用的 因为可能此IP被其他人使用 ...
- python3编写网络爬虫19-app爬取
一.app爬取 前面都是介绍爬取Web网页的内容,随着移动互联网的发展,越来越多的企业并没有提供Web页面端的服务,而是直接开发了App,更多信息都是通过App展示的 App爬取相比Web端更加容易 ...
- python3编写网络爬虫21-scrapy框架的使用
一.scrapy框架的使用 前面我们讲了pyspider 它可以快速的完成爬虫的编写 不过pyspider也有一些缺点 例如可配置化不高 异常处理能力有限对于一些反爬虫程度非常强的网站 爬取显得力不从 ...
随机推荐
- 文成小盆友python-num2 数据类型、列表、字典
一.先聊下python的运行过程 计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程.这个过程分成两类,第一种是 ...
- ionic2+angular2
ionic2+angular2中踩的那些坑 好久没写什么东西了,最近在做一个ionic2的小东西,遇到了不少问题,也记录一下,避免后来的同学走弯路. 之前写过一篇使用VS2015开发ionic1的文章 ...
- 数据结构之------C++指针冒泡排序算法
C++通过指针实现一位数组的冒泡排序算法. 冒泡排序 冒泡排序(Bubble Sort),是一种计算机科学领域的较简单的排序算法. 代码: /* Name:冒泡排序算法 Copyright:Null ...
- DSASync: Managing End-to-End Connections in Dynamic Spectrum Access Wireless LANs
其实跟上一篇是同一篇文章.不过上一篇是发表在IEEE Secon2010了,这篇是后来又增加了部分内容后的一版,收录在IEEE/ACM TRANSACTIONS ON NETWORKING, VOL. ...
- XJOI网上同步训练DAY2 T2
[问题描述] 火车司机出秦川跳蚤国王下江南共价大爷游长沙.每个周末勤劳的共价大爷都会开车游历长沙市. 长沙市的交通线路可以抽象成为一个
- NLS_LANG SIMPLIFIED CHINESE_CHINA.AL32UTF8 和american_america.AL32UTF8
oadb01:/home/oracle> echo $NLS_LANG SIMPLIFIED CHINESE_CHINA.AL32UTF8 oadb01:/home/oracle> sql ...
- c# list exists(contains) delegate 委托判断 元素是否在LIST中存在
static void Main(string[] args) { List<GoodsInfo> list = new List<GoodsIn ...
- Spark机器学习笔记一
Spark机器学习库现支持两种接口的API:RDD-based和DataFrame-based,Spark官方网站上说,RDD-based APIs在2.0后进入维护模式,主要的机器学习API是spa ...
- Java异步调用Future对象
Future类存在于JDK的concurrent包中,主要用途是接收Java的异步线程计算返回的结果. 个人理解的使用场景大概如下: 有两个任务A和B,A任务中仅仅需要使用B任务计算成果,有两种方法实 ...
- iOS opencv
1.在iPhone上使用 OpenCV http://blog.csdn.net/kmyhy/article/details/7560472 2. OpenCV iOS Hello¶ http://d ...