01布尔模型&倒排索引
原文链接: http://www.cnblogs.com/jacklu/p/8379726.html
博士一年级选了这门课 SEEM 5680 Text Mining Models and Applications,记下来以便以后查阅。
1. 信息检索的布尔模型
用0和1表示某个词是否出现在文档中。如下图例子,要回答“Brutus AND Caesar but NOT Calpurnia”,我们需要对词的向量做布尔运算,即110100 AND 110111 AND 101111=100100 对应的文档是Antony and Cleopatra和Hamlet

然而这种方法随着数据的增大是非常耗费空间的。比如我们有100万个文档,每个文档平均有1000字,总共有50万个不同的词语,那么矩阵将是500 000 x 1 000 000。这个矩阵是稀疏的,1的个数一般不会超过1亿个。
2. 倒排索引
倒排索引是为了解决上述布尔模型的问题。具体来说,每个词用链表顺序存储文档编号。如下图所示:
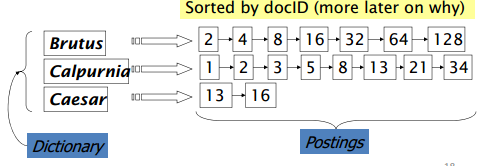
建立索引的核心是将词按字母顺序排列,合并重复词,但是要记录词频。
3. 倒排索引模型中对查询语句(AND)的处理
1、求Brutus AND Calpurnia,即求两个链表的交集。

算法思路是如果文档号不同就移动较小的指针,伪代码 INTERSECTION(p1, p2):
answer<-()
while p1 != NIL and p2 != NIL
do if docID(p1) = docID(p2)
then ADD(answer, docID(p1))
p1 <-next(p1)
p2 <-next(p2)
else if docID(p1) < docID(p2)
p1 <-next(p1)
else p2<-next(p2)
return answer
思考题,有两个词项A,B,其文档编号链表长度分别为3和5,那么对A,B求交集,最少的访问次数和最多的访问次数分别是多少?各举一个例子
最少访问次数是4,比如A:1-2-3,B:3-4-5-6-7;最多访问次数是8,比如A:1-7-8, B:3-4-5-7-9
2、思考题:求Brutus OR Calpurnia,即求两个链表的并集。伪代码 UNION(p1,p2):
answer<-()
while p1 != NIL and p2 != NIL
do if docID(p1) = docID(p2)
then ADD(answer, docID(p1))
p1 <-next(p1)
p2 <-next(p2)
else if docID(p1) < docID(p2)
then ADD(answer, docID(p1))
p1<-next(p1)
else ADD(answer, docID(p2))
p2<-next(p2)
return answer
3、思考题:求Brutus AND NOT Calpurnia。伪代码 INTERSECTION(p1,p2, AND NOT):
answer<-()
while p1 != NIL and p2 != NIL
do if docID(p1) = docID(p2)
p1 <-next(p1)
p2 <-next(p2)
else if docID(p1) < docID(p2)
then ADD(answer, docID(p1))
p1<-next(p1)
else p2<-next(p2) if p1 != NIL and P2 = NIL
then ADD(answer, docID(p1))
p1<-next(p1)
return answer
参考资料:http://www1.se.cuhk.edu.hk/~seem5680/
01布尔模型&倒排索引的更多相关文章
- Dubble 01 架构模型&start project
Dubbo 01 架构模型 传统架构 All in One 测试麻烦,微小修改 全都得重新测 单体架构也称之为单体系统或者是单体应用.就是一种把系统中所有的功能.模块耦合在一个应用中的架构方式.其优点 ...
- 【再探backbone 01】模型-Model
前言 点保存时候不注意发出来了,有需要的朋友将就看吧,还在更新...... 几个月前学习了一下backbone,这段时间也用了下,感觉之前对backbone的学习很是基础,前几天有个园友问我如何将路由 ...
- (01)odoo模型中调用窗体动作
*模型代码 addons/stock/stock.py ---------------- #移库单执行移库动作(弹出详细框) @api.cr_uid_ids_context def ...
- 文本信息检索——布尔模型和TF-IDF模型
文本信息检索--布尔模型和TF-IDF模型 1. 布尔模型 如要检索"布尔检索"或"概率检索"但不包括"向量检索"方面的文档,其相应的查 ...
- 原创:史上对BM25模型最全面最深刻的解读以及lucene排序深入讲解
垂直搜索结果的优化包括对搜索结果的控制和排序优化两方面,其中排序又是重中之重.本文将全面深入探讨垂直搜索的排序模型的演化过程,最后推导出BM25模型的排序.然后将演示如何修改lucene的排序源代码, ...
- 推荐排序---Learning to Rank:从 pointwise 和 pairwise 到 listwise,经典模型与优缺点
转载:https://blog.csdn.net/lipengcn/article/details/80373744 Ranking 是信息检索领域的基本问题,也是搜索引擎背后的重要组成模块. 本文将 ...
- 数据分析之客户价值模型(RFM)技术总结
作者 | leo 管理学中有一个重要概念那就是客户关系管理(CRM),它核心目的就是为了提高企业的核心竞争力,通过提高企业与客户间的交互,优化客户管理方式,从而实现吸引新客户.保留老客户以及将已有客户 ...
- 概率检索模型及BM25
概率排序原理 以往的向量空间模型是将query和文档使用向量表示然后计算其内容相似性来进行相关性估计的,而概率检索模型是一种直接对用户需求进行相关性的建模方法,一个query进来,将所有的文档分为两类 ...
- 学习笔记TF049:TensorFlow 模型存储加载、队列线程、加载数据、自定义操作
生成检查点文件(chekpoint file),扩展名.ckpt,tf.train.Saver对象调用Saver.save()生成.包含权重和其他程序定义变量,不包含图结构.另一程序使用,需要重新创建 ...
随机推荐
- An In-Depth Look at the HBase Architecture--转载
原文地址:https://www.mapr.com/blog/in-depth-look-hbase-architecture In this blog post, I’ll give you an ...
- 【bzoj3130】[Sdoi2013]费用流 二分+网络流最大流
题目描述 Alice和Bob做游戏,给出一张有向图表示运输网络,Alice先给Bob一种最大流方案,然后Bob在所有边上分配总和等于P的非负费用.Alice希望总费用尽量小,而Bob希望总费用尽量大. ...
- Python网络编程socket
网络编程之socket 看到本篇文章的题目是不是很疑惑,what is this?,不要着急,但是记住一说网络编程,你就想socket,socket是实现网络编程的工具,那么什么是socket,什么是 ...
- 怎样搭建一个自有域名的 WORDPRESS 博客?
博客搭建并不复杂,只是过程有点繁琐,适合喜欢折腾的人,主要有下面几个步骤: 新建一个博客文件 购买域名(Domain Name) 注册一个主机空间(Web Host) 域名解析(DNSPod) 安装W ...
- 常州day3
Task1 小 W 得到了一堆石子,要放在 N 条水平线与 M 条竖直线构成的网格的交点上.因为小 M 最喜欢矩形了, 小 W 希望知道用 K 个石子最多能找到多少四边平行于坐标轴的长方形,它的四个角 ...
- 洛谷 3201 [HNOI2009]梦幻布丁 解题报告
3201 [HNOI2009]梦幻布丁 题目描述 \(N\)个布丁摆成一行,进行\(M\)次操作.每次将某个颜色的布丁全部变成另一种颜色的,然后再询问当前一共有多少段颜色.例如颜色分别为\(1,2,2 ...
- 洛谷 P4585 [FJOI2015]火星商店问题 解题报告
P4585 [FJOI2015]火星商店问题 题目描述 火星上的一条商业街里按照商店的编号\(1,2,\dots,n\) ,依次排列着\(n\)个商店.商店里出售的琳琅满目的商品中,每种商品都用一个非 ...
- 基于centos系统安装pip模块
pip模块安装 centos 6.5安装pip,centos安装Python包管理安装工具pip的方法如下: 此安装包使用的是pip1.5.5版本 wget --no-check-certificat ...
- Hive(一)基础知识
一.Hive的基本概念 (安装的是Apache hive 1.2.1) 1.hive简介 Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表, 并提供类 SQ ...
- 【期望】【P5081】Tweetuzki 爱取球
Description Tweetuzki 有一个袋子,袋子中有 \(N\) 个无差别的球.Tweetuzki 每次随机取出一个球后放回.求取遍所有球的期望次数. 取遍是指,袋子中所有球都被取出来过至 ...