深入理解Adaboost算法
理解算法确实是欲速则不达,唯有一步一步慢慢看懂,然后突然觉得写的真的太好了,那才是真的有所理解了。
Adaboost的两点关键点:
1. 如何根据弱模型的表现更新训练集的权重;
2. 如何根据弱模型的表现决定弱模型的话语权
算法步骤:
从训练数据中训练出一系列的弱分类器,然后把这些弱分类器集成为一个强分类器,这里并没有继续对强分类器继续合成。
给定一个训练数据集T={(x1,y1), (x2,y2)…(xN,yN)},其中实例 ,而实例空间
,而实例空间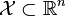 ,yi属于标记集合{-1,+1},Adaboost的目的就是从训练数据中学习一系列弱分类器或基本分类器,然后将这些弱分类器组合成一个强分类器。
,yi属于标记集合{-1,+1},Adaboost的目的就是从训练数据中学习一系列弱分类器或基本分类器,然后将这些弱分类器组合成一个强分类器。
Adaboost的算法流程如下:
- 步骤1. 首先,初始化训练数据的权值分布。每一个训练样本最开始时都被赋予相同的权值:1/N。

- 步骤2. 进行多轮迭代,用m = 1,2, ..., M表示迭代的第多少轮
a. 使用具有权值分布Dm的训练数据集学习,得到基本分类器(选取让误差率最低的阈值来设计基本分类器):

b. 计算Gm(x)在训练数据集上的分类误差率

由上述式子可知,Gm(x)在训练数据集上的误差率em就是被Gm(x)误分类样本的权值之和。

由上述式子可知,em <= 1/2时,am >= 0,且am随着em的减小而增大,意味着分类误差率越小的基本分类器在最终分类器中的作用越大。
d. 更新训练数据集的权值分布(目的:得到样本的新的权值分布),用于下一轮迭代

使得被基本分类器Gm(x)误分类样本的权值增大,而被正确分类样本的权值减小。就这样,通过这样的方式,AdaBoost方法能“重点关注”或“聚焦于”那些较难分的样本上。
其中,Zm是规范化因子,使得Dm+1成为一个概率分布:

- 步骤3. 组合各个弱分类器

从而得到最终分类器,如下:

深入理解Adaboost算法的更多相关文章
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- Adaboost 算法
一 Boosting 算法的起源 boost 算法系列的起源来自于PAC Learnability(PAC 可学习性).这套理论主要研究的是什么时候一个问题是可被学习的,当然也会探讨针对可学习的问题的 ...
- Adaboost 算法的原理与推导
0 引言 一直想写Adaboost来着,但迟迟未能动笔.其算法思想虽然简单“听取多人意见,最后综合决策”,但一般书上对其算法的流程描述实在是过于晦涩.昨日11月1日下午,邹博在我组织的机器学习班第8次 ...
- Adaboost算法结合Haar-like特征
Adaboost算法结合Haar-like特征 一.Haar-like特征 目前通常使用的Haar-like特征主要包括Paul Viola和Michal Jones在人脸检测中使用的由Papageo ...
- adaboost算法
三 Adaboost 算法 AdaBoost 是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器,即弱分类器,然后把这些弱分类器集合起来,构造一个更强的最终分类器.(很多博客里说的三个臭皮匠 ...
- 数据挖掘学习笔记--AdaBoost算法(一)
声明: 这篇笔记是自己对AdaBoost原理的一些理解,如果有错,还望指正,俯谢- 背景: AdaBoost算法,这个算法思路简单,但是论文真是各种晦涩啊-,以下是自己看了A Short Introd ...
- 前向分步算法 && AdaBoost算法 && 提升树(GBDT)算法 && XGBoost算法
1. 提升方法 提升(boosting)方法是一种常用的统计学方法,在分类问题中,它通过逐轮不断改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性能 0x1: 提升方法的基本 ...
- 集成学习值Adaboost算法原理和代码小结(转载)
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类: 第一个是个体学习器之间存在强依赖关系: 另一类是个体学习器之间不存在强依赖关系. 前者的代表算法就是提升(bo ...
- Adaboost 算法实例解析
Adaboost 算法实例解析 1 Adaboost的原理 1.1 Adaboost基本介绍 AdaBoost,是英文"Adaptive Boosting"(自适应增强)的缩写,由 ...
随机推荐
- GATT服务搜索流程(一)
GATT的规范阅读起来还是比较简答, 但是这样的规范在代码上是如何实现的呢?下面就分析一下bluedroid 协议栈关于GATT的代码流程. BLE的设备都是在SMP之后进行ATT的流程的交互.从代码 ...
- Python_闭包_27
#闭包:嵌套函数,内部函数 并且必须调用外部函数的变量 def outer(): a = 1 def inner(): print(a) inner() print(inner.__closure__ ...
- 20135218 Linux 实践二 编译模块
20135218 姬梦馨 1.编写模块代码 模块构造函数:执行insmod或modprobe指令加载内核模块时会调用的初始化函数.函数原型必须是module_init(),括号内是函数指针 模块析构函 ...
- GuiHelloWorld
package com.home.test; import java.awt.Color; import java.awt.Cursor; import java.awt.Font; import j ...
- Github以及推广
非常抱歉,我忘记在这个博客上发一遍了,之前是我同学代发,而我忘记把链接给发过来... Github: http://www.cnblogs.com/case1/p/5060015.html 推广: h ...
- Comparer Under Centos 7
Kompare 效果还行.
- []转帖] 浅谈Linux下的五种I/O模型
浅谈Linux下的五种I/O模型 https://www.cnblogs.com/chy2055/p/5220793.html 一.关于I/O模型的引出 我们都知道,为了OS的安全性等的考虑,进程是 ...
- ubuntu 下搭建redis和php的redis的拓展
系统环境: 腾讯云服务器, ubuntu16.0.4.4 ,php7.0 一.安装redis服务 sudo apt-get install redis-server 安装好的redis目录在 /e ...
- python下划线
单下划线(_) 通常情况下,会在以下3种场景中使用: 1.在解释器中:在这种情况下,“_”代表交互式解释器会话中上一条执行的语句的结果.这种用法首先被标准CPython解释器采用,然后其他类型的解释器 ...
- html DOM簡介
DOM:文檔對象模型 dom分為3類,核心DOM.xml DOM.HTML DOM: 核心DOM:針對任何結構化文檔的標準模型: xml DOM:針對xml的標準模型,定義了所有的元素的對象和屬性,以 ...