xpath分析 html文件抽正文的过程
使用Py3的HTMLParser解析模块解析HTML的时候,出现:no moudle named 'markupbase' 错误。
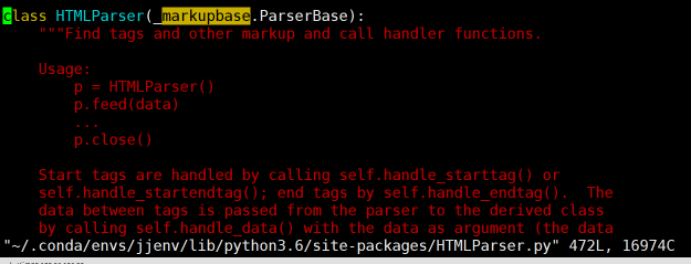
用xpath打算分析html里面的新闻。根据运行程序后的报错的信息,知道出问题的地方是 "~/.conda/envs/jjenv/lib/python3.6/site-packages/HTMLParser.py" 在这个文件的 72行出问题了。但是不知道是什么原因,
然后我就百度了下,说是:
解决方法:将所有的 markupbase 改为 _markupbase 即可。原因为markupbase是py2库的,_markupbase是py3库的。
于是我进入"~/.conda/envs/jjenv/lib/python3.6/site-packages/HTMLParser.py"这个文件,修改后的结果如上图的第一行。问题得到解决.
反思总结:勇于根据程序报错的信息里面所提示的出错文件位置,定位到相应的文件,然后修改对应的源码代码!
############################## ###################### ##################################
原html文件如下:

content1 = tree.xpath('//text()')
print ('content1====',content1)
这个输出结果如下:
<html>
<head>
<meta charset="utf-8"/>
<title>
供给忧虑推升油价破纪录_国际经济_新浪财经_新浪网
</title>
</head>
<body><div><div id="artibodyTitle">
<h1>供给忧虑推升油价破纪录</h1>
<p class="from_info">http://www.sina.com.cn 2008年04月29日 13:14 <span class="linkRed02">南方日报</span></p>
</div> <div class="artibody" id="artibody">
<center>
<center/></center> <p> <font face="楷体_GB2312">纽约油价盘中达每桶119.93美元</font> </p>
<p> 据新华社北京4月28日电由于英国石油公司在北海油田的一条输油管道被关闭等因素引起市场交易者担心石油供给短缺,4月28日纽约油价在电子交易时段创出新高,进一步逼近每桶120美元的高位。</p>
<p> 纽约商品交易所6月份交货的轻质原油期货价格在电子交易中一度达到每桶119.93美元,刷新了4月22日创下的每桶119.90美元的最高交易价。</p>
<p> 由于英国一家主要炼油厂工人4月27日举行罢工,英国石油公司被迫关闭了在北海油田的一条主输油管道。这条输油管道日输油能力为70万桶,接近英国全国原油日产量的一半。另外,受工人罢工和石油生产设施遭到袭击的影响,非洲产油大国尼日利亚超过一半的石油产能处于关闭状态,进一步加剧了市场对原油供应的担忧。</p>
<p> 受美元贬值以及石油输出国组织拒绝增加石油产量等因素影响,国际油价近来一直在高位运行,分析人士认为目前市场交易者因突发事件对石油供给的担忧将对近期油价走势产生较大影响,并可能推升油价进一步走高。</p>
<p> 据阿拉伯金融网站报道,沙特阿拉伯最大的国家石油公司———阿美石油公司已作出新的发展计划,将石油钻井数量在目前的基础上再增加三分之一,并将进一步加大对能源项目的投资,使投资额提高40%。</p>
<p> 该网站援引英国《中东经济文摘》周刊的一篇报道说,这项将于2009至2013年实施的计划草案将被提交到今年5月中旬的公司董事会上讨论通过。 </p> <a href="target=_blank"/>
</div> </div></body></html>
是根据这个输出结果写的如下代码,
接下来说说如何用xpath 去抽取html中我想要的正文部分
#coding=utf-8
from lxml import etree
from HTMLParser import HTMLParser
from lxml import html filepath = '/data0/news_cleaned/sina/finance/2008-04-29/finance.sina.com.cn_+world_+gjjj_+20080429_+13144815898.html' with open(filepath) as f:
s=f.read()
#print(s)
#print(html)
tree = html.fromstring(s) ##################################
### 输出整个html的东西 ####
content1 = tree.xpath('//text()')
print ('content1====',content1)
### 输出 h1标签的内容 ##############
title = tree.xpath("//h1/text()")[0]
print('title===',title) ######################################################## filepath = '/data0/news_cleaned/sina/finance/2008-04-29/finance.sina.com.cn_+world_+gjjj_+20080429_+13144815898.html'
each_paper=''
with open(filepath) as f:
s=f.read()
tree = html.fromstring(s)
div_list = tree.xpath("//div[@class='artibody']/p")
for div_i in div_list:
each_paper = each_paper + div_i.xpath('.//text()')[0] print('each_paper===',each_paper) #结果是正确的,但是未保留html正文文本的中的换行之类的。
#########################################################3 #################################
div_list = tree.xpath("//div[@class='artibody']")
print('shishi===',(div_list[0].text_content())) # 成功的,保留了原html正文的格式,如换行
#print('shishi===',html.tostring(div_list[0])) #不成功的尝试 #for div_i in div_list:
#print('shishi===',str(html.tostring(div_i))) #不成功的尝试
#print('shishi===',(div_i.text_content())) #不成功的尝试
############################# #################### ##########################
张miao同事也给了我一个不错的版本
from bs4 import BeautifulSoup
import re
html='xxxxxxx'
soup=BeautifulSoup(html)
div=soup.find('div')
content=re.findall('<font.*/font>(.*)a href',str(div))
 我: 这个还得继续进行re吧 :
我: 这个还得继续进行re吧 :
张 :replace 无用符号就行了 :或者sub一下
我: :我看看是不是能解决所有html文本。
:
xpath分析 html文件抽正文的过程的更多相关文章
- MyBatis 源码分析 - 映射文件解析过程
1.简介 在上一篇文章中,我详细分析了 MyBatis 配置文件的解析过程.由于上一篇文章的篇幅比较大,加之映射文件解析过程也比较复杂的原因.所以我将映射文件解析过程的分析内容从上一篇文章中抽取出来, ...
- 结合中断上下文切换和进程上下文切换分析Linux内核的一般执行过程
结合中断上下文切换和进程上下文切换分析Linux内核的一般执行过程 目录 结合中断上下文切换和进程上下文切换分析Linux内核的一般执行过程 一. 实验准备 二. 实验过程 I 分析中断上下文的切换 ...
- 使用MAT(Memory Analyzer Tool)工具分析dump文件--转
原文地址:http://gao-xianglong.iteye.com/blog/2173140?utm_source=tuicool&utm_medium=referral 前言 生产环境中 ...
- mybatis源码分析(1)——SqlSessionFactory实例的产生过程
在使用mybatis框架时,第一步就需要产生SqlSessionFactory类的实例(相当于是产生连接池),通过调用SqlSessionFactoryBuilder类的实例的build方法来完成.下 ...
- 分析Ext2文件系统结构。
1. 目的 分析Ext2文件系统结构. 使用 debugfs 应该跟容易分析 Ext2文件系统结构 了解ext2的hole的 2. 准备工作 预习文件系统基本知识: http://www.doc88. ...
- ELF文件的加载过程(load_elf_binary函数详解)--Linux进程的管理与调度(十三)
加载和动态链接 从编译/链接和运行的角度看,应用程序和库程序的连接有两种方式. 一种是固定的.静态的连接,就是把需要用到的库函数的目标代码(二进制)代码从程序库中抽取出来,链接进应用软件的目标映像中: ...
- Spark源码分析(四)-Job提交过程
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3903478.html 本文将以一个简单的WordCount为例来看看Job的提交过程
- 本地模拟内存溢出并分析Dump文件
java Dump文件分析 前言 dump文件是java虚拟机内存在某一时间点的快照文件,一般是.hprof文件,下面自己模拟一下本地内存溢出,生成dump文件,然后通过mat工具分析的过程. 配置虚 ...
- django源码分析——静态文件staticfiles中间件
本文环境python3.5.2,django1.10.x系列 1.在上一篇文章中已经分析过handler的处理过程,其中load_middleware就是将配置的中间件进行初始化,然后调用相应的设置方 ...
随机推荐
- 使用 curses 函数库管理基于文本的屏幕
curses 函数库提供了终端无关的方式来编写全屏幕的基于字符的程序.curses 还可以管理键盘,提供了一种简单易用的非阻塞字符输入模式. curses 函数库能够优化光标的移动并最小化需要对屏幕进 ...
- Lambda表达式树构建(上)
概述 Lambda是C#常用的语句,采用委托等方式,来封装真实的代码块.Lambda其实就是语法糖,是一个匿名函数,是一种高效的类似于函数式编程的表达式,Lambda简化了开发中需要编写的代码量.它可 ...
- mongodb实现自增的方法
前面操作看菜鸟教程 function getNextSequenceValue(sequenceName){ var sequenceDocument = Counter.findOneAndUpda ...
- JMeter3.0 post参数/BeanShell中文乱码问题
在用JMeter,在http请求的 Body Data或BeanShell中写的中文,为什么都是乱码—都是方框中间有个问号. 而且字体非常小,看着吃力,乱码现象如下图:
- 借助CSS Shapes实现元素滚动自动环绕iPhone X的刘海
CSS代码: .box { max-width: 414px; height: 480px; border: solid #000; margin: auto; overflow: auto; } . ...
- 移动端1px问题
.component-confirm__buttons { border-top: 1px solid #eceef0; box-shadow: 0 1px 1px #fff; } 造成边框变粗的原因 ...
- POJ3321Apple Tree Dfs序 树状数组
出自——博客园-zhouzhendong ~去博客园看该题解~ 题目 POJ3321 Apple Tree 题意概括 有一颗01树,以结点1为树根,一开始所有的结点权值都是1,有两种操作: 1.改变其 ...
- 数学建模:2.监督学习--分类分析- KNN最邻近分类算法
1.分类分析 分类(Classification)指的是从数据中选出已经分好类的训练集,在该训练集上运用数据挖掘分类的技术,建立分类模型,对于没有分类的数据进行分类的分析方法. 分类问题的应用场景:分 ...
- 环形链表(给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null)
思想: 思想:用快慢指针先判断是否有环,有环则 假设头结点到环入口距离为n,环入口到快慢指针相遇结点距离为m,则慢指针走的路程 为m+n,而快指针走的路程为m+n+k*l (k*l表示绕环走的路程), ...
- 爬虫3 requests基础
import requests # get实例 # res = requests.get('http://httpbin.org/get') # # res.encoding='utf-8' # pr ...