大雄的elk实践
目录
一、ElK环境搭建
1.1.elasticsearch
1..kibana
1..logstash
二、elk实践
2.1 使用elk分析nginx日志
一、ElK环境搭建
1.1 elasticsearch
下载的地址如下,我们这里下载2.4.6版本,我们kibana后面用的是4.x的,对应的是2.x版本
https://www.elastic.co/blog/elasticsearch-5-5-1-and-2-4-6-released
如果想下载6.x版本,建议到你要安装的目录下执行,会下载在该目录下,我这里下载到opt的elk目录下,
cd /opt/elk
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.4.tar.gz
改名字
tar zxvf elasticsearch-6.2.4.tar.gz (按下载的版本改)
mv elasticsearch-6.2.4 elasticsearch
添加用户组与用户,设置用户的组名和密码,useradd elasticsearch(用户名) -g elasticsearch(组名) -p elasticsearch(密码)
groupadd elasticsearch
useradd elasticsearch -g elasticsearch -p elasticsearch
我们刚刚不是改目录为elasticsearch嘛,现在去到那个目录授权,我的目录在/opt/elk/elasticsearch,所以应该先去/opt/elk下面
cd /opt/elk
chown -R elasticsearch:elasticsearch elasticsearch
到目前为止,我们都是在root用户进行的,启动命令是./bin/elasticsearch,但是用root启动会报错,因为他不允许在root用户下面启动。
所以这个时候我们进入用户,输入刚刚设置好的密码
su elasticsearch
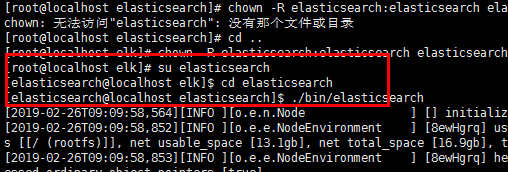
最后我们去目录下启动
./bin/elasticsearch
看到这样的就是成功了
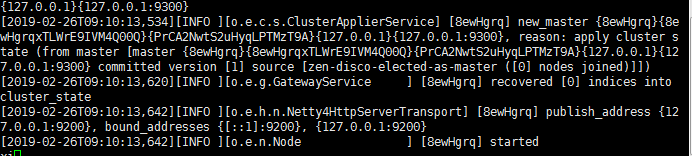
当然了,我们都喜欢它在后台启动
./bin/elasticsearch -d
我们需要配置ip,这样才可以访问。跳转到Elasticsearch的config配置文件下,使用vim打开elasticsearch.yml,找到里面的"network.host",将其改为你ifconfig查询得到的IP,保存。
cd elasticsearch/config/ vi elasticsearch.yml
配置完我们需要重启,好的,然后elasticsearch最坑爹的一点来了,这个东西没有重启命令!!!只能ps -ef| grep查进程然后杀掉重新开,集群采用滚动重启。
ps -ef | grep elastic
kill - 你的进程
到这里你可能还会发现这货是没有关闭命令的。
好的,跑起来。。emm?
ERROR: [] bootstrap checks failed
[]: max file descriptors [] for elasticsearch process is too low, increase to at least []
[]: max number of threads [] for user [elasticsearch] is too low, increase to at least []
[]: max virtual memory areas vm.max_map_count [] is too low, increase to at least []
[--26T09::,][INFO ][o.e.n.Node ] [8ewHgrq] stopping ...
[--26T09::,][INFO ][o.e.n.Node ] [8ewHgrq] stopped
[--26T09::,][INFO ][o.e.n.Node ] [8ewHgrq] closing ...
[--26T09::,][INFO ][o.e.n.Node ] [8ewHgrq] closed
解决它,我们先退回root(用exit退出当前用户)用户,来改点东西
、max file descriptors [] for elasticsearch process is too low, increase to at least [] 每个进程最大同时打开文件数太小,可通过下面2个命令查看当前数量 ulimit -Hn
ulimit -Sn
修改/etc/security/limits.conf文件,增加配置,用户退出后重新登录生效,配置完别急着退出这个文件,下面还要接着插入指令 * soft nofile
* hard nofile 65536
2.max number of threads [3818] for user [es] is too low, increase to at least [4096]
问题同上,最大线程个数太低。修改配置文件/etc/security/limits.conf,增加配置
|
1
2
|
* soft nproc 4096* hard nproc 4096 |
可通过命令查看
ulimit -Hu
ulimit -Su
3、max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
修改/etc/sysctl.conf文件,增加配置vm.max_map_count=262144
vi /etc/sysctl.conf
sysctl -p
执行命令sysctl -p生效
现在我们访问centos服务器的9200端口

终于能正常访问了。但是好 j。。b丑啊。一堆json。
1.2.kibana
1.2.1. 创建kibana.repo
$ sudo vi /etc/yum.repos.d/kibana.repo
[kibana-4.4]
name=Kibana repository for 4.4.x packages
baseurl=http://packages.elastic.co/kibana/4.4/centos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
1.2.2. 使用yum install安装kibana
你要先指定一下你的路径再yum install
$ cd /opt
$ sudo yum -y install kibana
注:
1、Kibana默认端口为5601
2、kibana默认安装在/opt/kibana目录下
3、Kibana配置文件路径为/opt/kibana/config/kibana.yml
$ rpm -qc kibana
/opt/kibana/config/kibana.yml
1.2.3. 修改kibana配置
$ sudo vi /opt/kibana/config/kibana.yml
server.host: "192.168.0.228"
elasticsearch.url: "http://192.168.0.228:9200"
1.2.4. 启动kibana并添加为开机自启动服务
$ sudo systemctl start kibana
$ sudo chkconfig kibana on
kibana的访问端口是5601,如果是6.4.2的elasticsearch就会出现这种问题:提示你需要2.x的
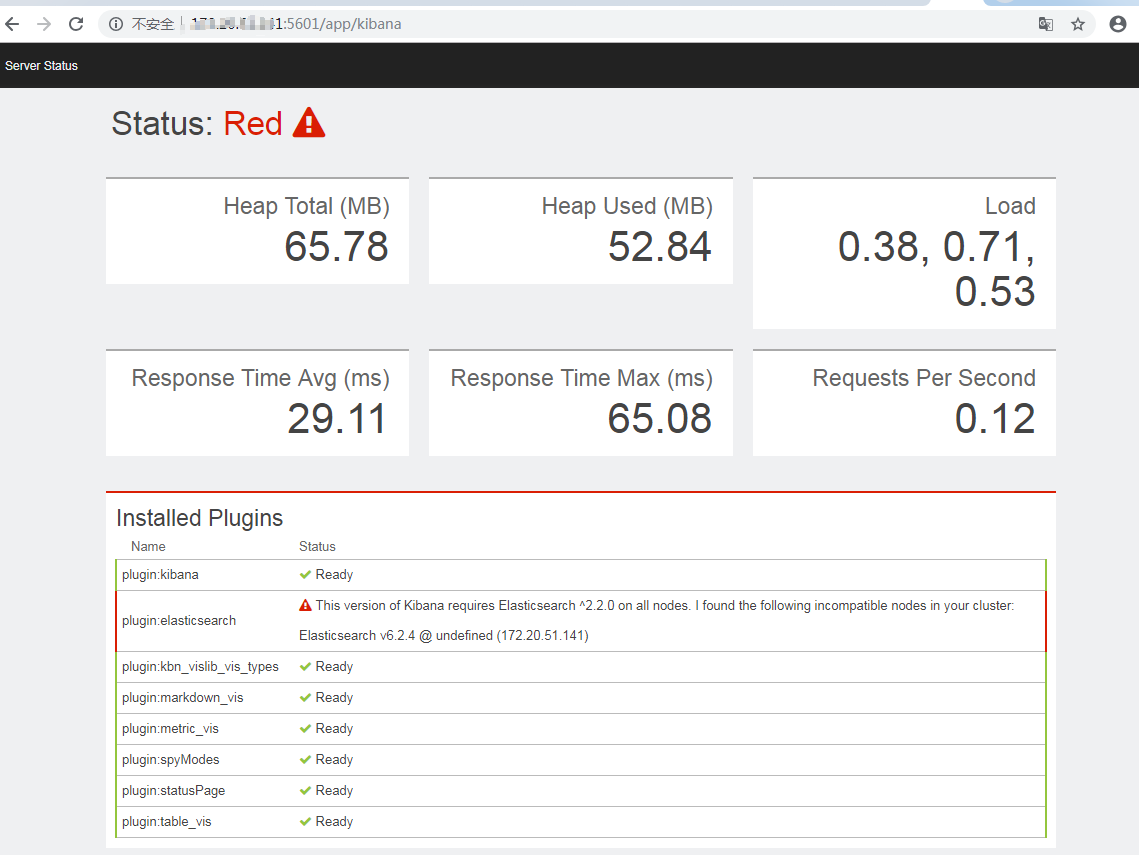
然后我改了2.x的
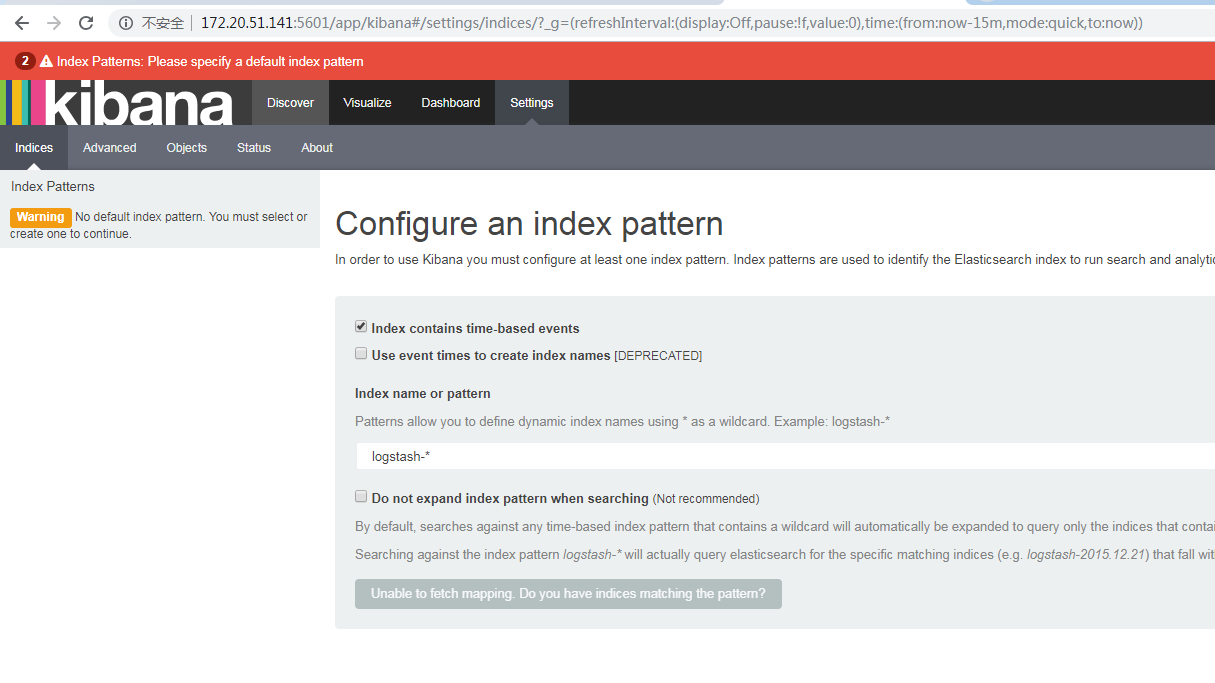
啊,好感动啊,终于出现了一个正常的界面
1.3.logstash
安装步骤
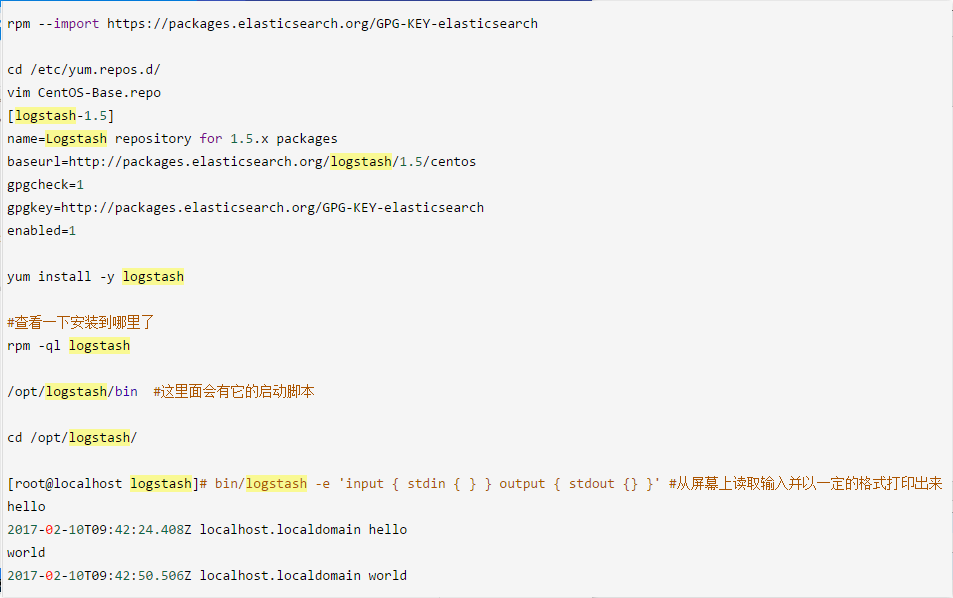
$ sudo vi /etc/yum.repos.d/logstash.repo
[logstash-2.2]
name=logstash repository for 2.2 packages
baseurl=http://packages.elasticsearch.org/logstash/2.2/centos
gpgcheck=
gpgkey=http://packages.elasticsearch.org/GPG-KEY-elasticsearch
enabled= $ sudo yum -y install logstash
以下按照网友的步骤,也可以,只不过版本不同
二、elk实践
2.1.使用elk分析nginx日志
现在我们用logstash连接一下nginx的日志,我们设置acesslogs使用的类型是json,
#在下面可以设置accesslog的参数是main还是json
log_format main
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"' log_format json '{"@timestamp":"$time_iso8601",'
'"@version":"1",'
'"client":"$remote_addr",'
'"url":"$uri",'
'"status":"$status",'
'"domain":"$host",'
'"host":"$server_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"referer": "$http_referer",'
'"ua": "$http_user_agent"'
'}';
#access_log /var/log/nginx/access.log main;
access_log /var/log/nginx/access_json.log json;
我这边建议多开一条
access_log /var/log/nginx/access_json.log json;,不然logstash收集日志的时候可能会解析不了json,因为之前nginx会打印非json类型的日志,比如出现这样的错误
Logstash startup completed
JSON parse failure. Falling back to plain-text {:error=>#<LogStash::Json::ParserError: Invalid UTF- start byte 0xae
at [Source: [B@18b40dae; line: , column: ]>, :data=>":13723.230.531.124
然后的话,telnet一下自己的9200端口,看看elesticseach哪种是通的,我的只有ip:port是通的,用127.0.0.1或者localhost会报错,因为让ogstash收集nginx的日志,然后放到elasticsearch,那么配置一下,我们建立一个
log_nginx.conf的这样的一个配置文件。
hosts => ["142.20.31.921:9200"]这一句的ip按telnet的结果来搞。
vi /etc/logstash/conf.d/log_nginx.conf
input {
file {
path => "/var/log/nginx/access.log"
codec => json
start_position => "beginning"
type => "nginx-log"
}
}
output {if [type] == "nginx-log"{
elasticsearch {
hosts => ["142.20.31.921:9200"]
index => "nginxLog-%{+YYYY.MM.dd}"
}
}
启动logstash
/opt/logstash/bin/logstash -f /etc/logstash/conf.d/log_nginx.conf
现在是这样的

我们把数据打到elastisearch的9200上去了,索引我们设置nginxLog-%{+YYYY.MM.dd},但是我们不知道它是多少,所以我们查一下
curl 'IP:9200/_cat/indices?v'
这样我们就看到索引了。

现在去9200端口拿一下这个索引。

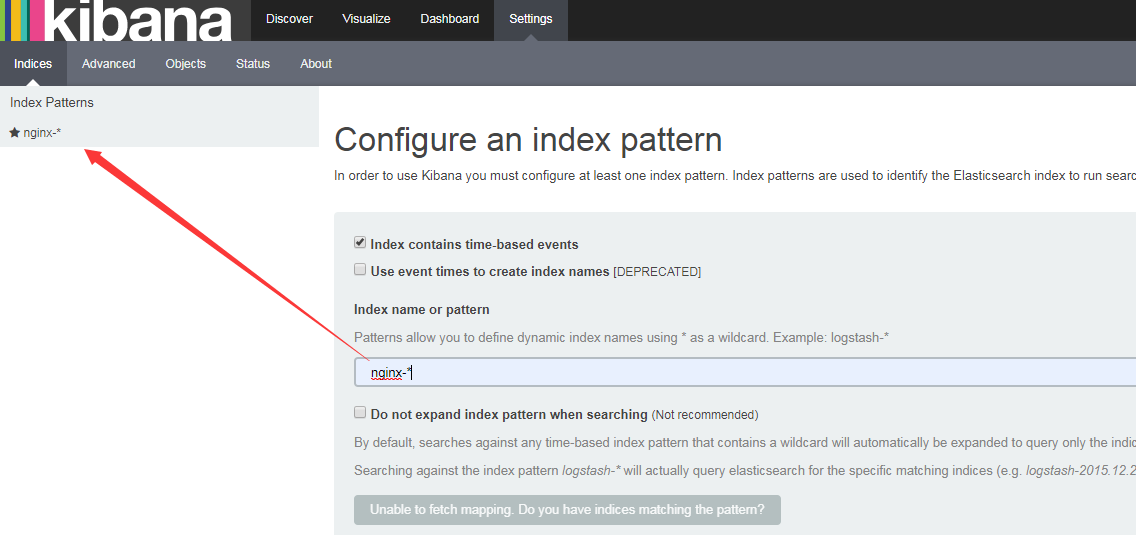
一堆json,看不清楚,上kibana,我们设置的elasticsearch以nginx-开头,搜索nginx-*即可查看。
ps:隔一段时间后启动会报错,经常会出现到kibana的bin目录下去手动启动kibana的操作。
这个时候一般找出那个扑街的进程,然后kill即可。
[root@localhost bin]# netstat -apn|grep
[root@localhost bin]# sudo systemctl start kibana
大雄的elk实践的更多相关文章
- Node 框架接入 ELK 实践总结
本文由云+社区发表 作者:J2X 我们都有过上机器查日志的经历,当集群数量增多的时候,这种原始的操作带来的低效率不仅给我们定位现网问题带来极大的挑战,同时,我们也无法对我们服务框架的各项指标进行有效的 ...
- ELK实践-Kibana定制化扩展
纵观任何一家大数据平台的技术架构,总少不了ElasticSearch:ES作为溶合了后端存储.快速检索.OLAP分析等功能的一套开源组件,更绝的是提供了一套集数据采集与前端展现为一体的框架(即ELK) ...
- ELK实践(二):收集Nginx日志
Nginx访问日志 这里补充下Nginx访问日志使用的说明.一般在nginx.conf主配置文件里需要定义一种格式: log_format main '$remote_addr - $remote_u ...
- ELK实践(一):基础入门
虽然用了ELK很久了,但一直苦于没有自己尝试搭建过,所以想抽时间尝试尝试.原本打算按照教程 <ELK集中式日志平台之二 - 部署>(作者:樊浩柏科学院) 进行测试的,没想到一路出了很多坑, ...
- ELK实践
一.ElasticSearch+FileBeat+Kibana搭建平台 在C# 里面运行程序,输出日志(xxx.log 文本文件)到FileBeat配置的路径下面. 平台搭建,参考之前的随笔. Fil ...
- logstash 学习小记
logstash 学习小记 标签(空格分隔): 日志收集 Introduce Logstash is a tool for managing events and logs. You can use ...
- springcloud --- spring cloud sleuth和zipkin日志管理(spring boot 2.18)
前言 在spring cloud分布式架构中,系统被拆分成了许多个服务单元,业务复杂性提高.如果出现了异常情况,很难定位到错误位置,所以需要实现分布式链路追踪,跟进一个请求有哪些服务参与,参与的顺序如 ...
- Nginx双机主备(Keepalived实现)
前言 首先介绍一下Keepalived,它是一个高性能的服务器高可用或热备解决方案,起初是专为LVS负载均衡软件设计的,Keepalived主要来防止服务器单点故障的发生问题,可以通过其与Nginx的 ...
- ELK初步实践
ELK是一个日志分析和统计框架,是Elasticsearch.Logstash和Kibana三个核心开源组件的首字母缩写,实践中还需要filebeat.redis配合完成日志的搜集. 组件一览 名称 ...
随机推荐
- 从零开始一起学习SLAM | 理解图优化,一步步带你看懂g2o代码
首发于公众号:计算机视觉life 旗下知识星球「从零开始学习SLAM」 这可能是最清晰讲解g2o代码框架的文章 理解图优化,一步步带你看懂g2o框架 小白:师兄师兄,最近我在看SLAM的优化算法,有种 ...
- python 爬虫-1
买了本书在自学,我也不知道自己能学到什么地步,反正不用这个找工作,纯属爱好,有可能之后就会放弃 233333333.... 先来一个特别简单点的:将百度搜索主页 扒下来,并保存到一个文件里面 fir ...
- a标签和p标签不能设置margin
经常会发现正常div的属性在a标签上或者p标签上都不管用,这是因为a标签和p标签都不是盒子模型. 例如: <div style="margin-top:5px;">&l ...
- angularjs 的ng-disabled属性操作
ng-readonly:不可用,但是可以提交数据 ng-disabled: 属性是控制标签是否可用(不可用且无法传值) 表达式控制: <input class="col-md-2 fo ...
- mysql迁移到data下
http://www.jb51.net/article/47897.htm 由于yum安装mysql的时候,数据库的data目录默认是在/var/lib下,出于数据安全性的考虑需要把它挪到/data分 ...
- restful规范快速记忆
restful规范: 十个规则: 用户发来请求,url必须: 1.因为是面向资源编程,所以每个URL代表一种资源,URL中尽量不要用动词,要用名词 2.尽量使用HTTPS,https代替http 3. ...
- Windwos Live Writer插件指南
Windows Live Writer 即(WLW) 是一个免费的桌面应用程序,可以用于发布博客. 官网下载地址:https://www.microsoft.com/zh-CN/download/de ...
- Android Studio NDK开发环境搭建
一. 下载安装Android studio 和 NDK 二. 在Android studio中配置NDK(和SDK配置一样) 三. 用Android studio建立一个工程,打开proj ...
- 禁止chrome浏览器的缓冲图片以及css等资源文件
今天做了一个动画的效果,在ff下正常 但是到了谷歌下就不正常了,非常郁闷,看了下是缓存的问题 ,于是度娘了一下发现清理缓存的技巧还是满多的,这里借鉴一下别人的总结,人的大脑有限,下次忘记的时候还可以在 ...
- 将Bdd100k数据集转为CoCo数据集
小可爱,加油噻~ 添加上级目录 import sys sys.append('../..') 这样 from ... import 就会把加入的路径要扫描哒 os.walk() 方法用于通过在目录树中 ...