Python中识别DataFrame中的nan
# 识别python中DataFrame中的nan
for i in pfsj.index:
if type(pfsj.loc[i]['WZML']) == float:
print('float value is ${}'.format(pfsj.loc[i]['WZML']))
elif type(pfsj.loc[i]['WZML']) == str:
print('str value is ${}'.format(pfsj.loc[i]['WZML']))
结果:

# 根据结果可知在DataFrame中,nan的类型为float
# 使用math中的isnan函数识别数据是否是nan类型的
for i in pfsj.index:
if type(pfsj.loc[i]['WZML']) == float:
if isnan(pfsj.loc[i]['WZML']):
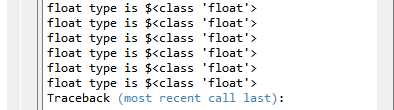
print('float type is ${}'.format(type(pfsj.loc[i]['WZML'])))
结果:
Python中识别DataFrame中的nan的更多相关文章
- python数据分析pandas中的DataFrame数据清洗
pandas中的DataFrame中的空数据处理方法: 方法一:直接删除 1.查看行或列是否有空格(以下的df为DataFrame类型,axis=0,代表列,axis=1代表行,以下的返回值都是行或列 ...
- [Spark][Python][DataFrame][RDD]DataFrame中抽取RDD例子
[Spark][Python][DataFrame][RDD]DataFrame中抽取RDD例子 sqlContext = HiveContext(sc) peopleDF = sqlContext. ...
- [Spark][Python]DataFrame中取出有限个记录的例子
[Spark][Python]DataFrame中取出有限个记录的例子: sqlContext = HiveContext(sc) peopleDF = sqlContext.read.json(&q ...
- Python dataframe中如何使y列按x列进行统计?
如图:busy=0 or 1,求出busy=1时los的平均,同样对busy=0时也求出los的平均 Python dataframe中如何使y列按x列进行统计? >> python这个答 ...
- Python 实现将numpy中的nan和inf,nan替换成对应的均值
nan:not a number inf:infinity;正无穷 numpy中的nan和inf都是float类型 t!=t 返回bool类型的数组(矩阵) np.count_nonzero( ...
- python – 基于pandas中的列中的值从DataFrame中选择行
如何从基于pandas中某些列的值的DataFrame中选择行?在SQL中我将使用: select * from table where colume_name = some_value. 我试图看看 ...
- [转]python中pandas库中DataFrame对行和列的操作使用方法
转自:http://blog.csdn.net/u011089523/article/details/60341016 用pandas中的DataFrame时选取行或列: import numpy a ...
- python中pandas库中DataFrame对行和列的操作使用方法
用pandas中的DataFrame时选取行或列: import numpy as np import pandas as pd from pandas import Sereis, DataFram ...
- 如何使用Python在Kaggle竞赛中成为Top15
如何使用Python在Kaggle竞赛中成为Top15 Kaggle比赛是一个学习数据科学和投资时间的非常的方式,我自己通过Kaggle学习到了很多数据科学的概念和思想,在我学习编程之后的几个月就开始 ...
随机推荐
- mint-ui Infinite scroll 重复加载、加载无效的原因及解决方案
1.无限滚动的运用场景: 一般运用在列表展示,有分页.下拉加载更多的需求中. 2.代码分析 代码很简单,实现了列表分页,数据加载完之后显示数据状态 <template> <div c ...
- Xamarin.Android Timer使用方法
首先声明命名空间: using System.Threading; 然后创建Timer对象: Timer timer; 接着实例化timer并且给委托事件: TimerCallback timerDe ...
- Xamarin.Android 调用本地相册
调用本地相册选中照片在ImageView上显示 代码: using System; using System.Collections.Generic; using System.Linq; using ...
- matlab中数组的拼接
matlab中,行拼接用逗号“:”,列拼接用分号“,”.示例如下: >> a=[1,2,3,4] 结果: a = 1 2 3 4 >> b=[1;2;3;4] 结果: b = ...
- Pthon常用模块之requests,urllib和re
urllib Python标准库中提供了:urllib等模块以供Http请求,但是,它的 API 太渣了. 它需要巨量的工作,甚至包括各种方法覆盖,来完成最简单的任务, 下面是简单的使用urllib来 ...
- 构建Docker Compose服务堆栈
1.安装了docker-compose,现在我们要使用docker-compose来运行容器栈.这个地方会有两个容器,一个容器中使用Flask搭建的简单应用,另一个容器是Redis,Flash会向re ...
- SpringBoot2.0源码分析(一):SpringBoot简单分析
SpringBoot2.0简单介绍:SpringBoot2.0应用(一):SpringBoot2.0简单介绍 本系列将从源码角度谈谈SpringBoot2.0. 先来看一个简单的例子 @SpringB ...
- C语言第五讲,语句 顺序循环选择.
C语言第五讲,语句 顺序循环选择. 一丶语句的简明了解 我们知道,在编写C语言程序的时候,代码是顺序执行的. 从上往下执行. 但是我们可以控制流程的. 在控制之前,我们要先熟悉什么是语句. 相比大家学 ...
- python3爬虫——下载unsplash美图到本地
最近发现一个网站www.unsplash.com ( 没有广告费哈,纯粹觉得不错 ),网页做得很美观,上面也都是一些免费的摄影照片,觉得很好看,就决定利用蹩脚的技能写个爬虫下载图片. 先随意感受一下这 ...
- pycharm专业版破解
网上找的用license server破解的地址都不可用== 有个方法倒是靠谱的,记录一下: 1.将C:\Windows\System32\drivers\etc里面的hosts文件打开,然后在文件中 ...