java多线程系列16 线程池
当系统系统规模较小,我们可以不使用线程池。但是当系统到达一定规模,频繁的创建和销毁线程池会消耗很多资源。
合理利用线程池能够带来三个好处。
1降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
2提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
3提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
下面演示下线程池的基本的使用
public class ThreadPoolExecutorTest {
public static void main(String[] args) {
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 10, 5, TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>());
Runnable runnable = null;
for (int i = 0; i < 20; i++) {
runnable = new Runnable() {
@Override
public void run() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " run");
}
};
executor.execute(runnable);
}
executor.shutdown();
}
}
Jdk默认了实现了4种线程池。
newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,默认是60秒,若无可回收,则新建线程。
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行
查看源码 ,都是调用

其本质是通过不同的参数初始化一个ThreadPoolExecutor对象,只是传递的参数不同罢了
具体参数解释如下:
corePoolSize 线程池中的核心线程数,
maximumPoolSize 线程池中允许的最大线程数
keepAliveTime 线程空闲时的存活时间,即当线程没有任务执行时,继续存活的时间
keepAliveTime的 单位 unit
workQueue
用来保存等待被执行的任务的阻塞队列,且任务必须实现Runable接口,在JDK中提供了如下阻塞队列:
ArrayBlockingQueue:基于数组的有界阻塞队列,按FIFO排序任务;
LinkedBlockingQuene:基于链表的无界阻塞队列,按FIFO排序任务,吞吐量通常要高于ArrayBlockingQuene;
SynchronousQuene:一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQuene;
priorityBlockingQuene:具有优先级的无界阻塞队列;
handler
线程池的拒绝策略,当阻塞队列满了,且没有空闲的工作线程,如果继续提交任务,必须采取一种策略处理该任务,线程池内置了4种策略:
1、AbortPolicy:直接抛出异常,默认策略;
2、CallerRunsPolicy:用调用者所在的线程来执行任务;
3、DiscardOldestPolicy:丢弃阻塞队列中靠最前的任务,并执行当前任务;
4、DiscardPolicy:直接丢弃任务;
当然我们也可以根据应用场景实现RejectedExecutionHandler接口,自定义拒绝策略,
实际开发中,一般先记录日志 再开一个定时去处理
执行流程图如下
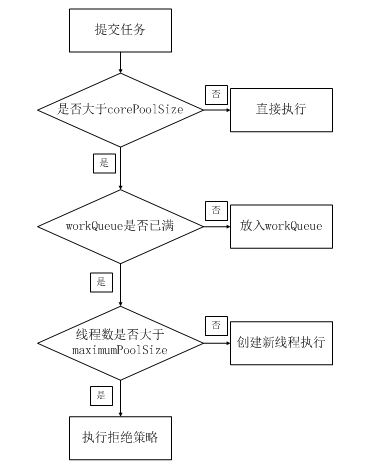
======================================================================
原理解析
找到线程池核心的execute()方法 源代码如下
if (command == null)
throw new NullPointerException();
//ctl是一个包装变量 包含了线程池的状态以及线程池中线程数
int c = ctl.get();
//workerCountOf 获取线程池的当前线程数
if (workerCountOf(c) < corePoolSize) { // 【步骤1】
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) { // 【步骤2】
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command)) //【步骤4】
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false)) // 【步骤3】
reject(command);
}
具体的执行流程如下:
--> 如果线程数小于corePoolSize,则执行addWorker方法创建新的线程执行任务 并返回 ;否则执行步骤2;
--> 如果线程池处于RUNNING状态,并且任务成功放入阻塞队列中,则执行步骤4,否则执行 步骤3
--> 再次检查线程池的状态,如果线程池没有RUNNING,并且从阻塞队列中删除任务,则执行reject方法处理任务;
--> 执行addWorker方法创建新的线程执行任务,如果addWoker执行失败,则执行reject方法处理任务;
接下来我们看看addWorker方法
addWorker分为2部分
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false; for (;;) {
int wc = workerCountOf(c);
//通过自旋的方式,判断要添加的Worker是否是true,如果是的话,那么
//则判断当前的workerCount是否大于corePoolsize,否则则判断是否大于//maximumPoolSize,如果满足的话,说明workerCount超出了线程池大小,直//接返回false 如果没有超出就cas让workerCount+1 如果成功就跳出循环 失//败就继续进行状态的判断
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
--------第一部分完
/*如果满足了的话,那么则创建一个新的Worker对象 满足状态就添加到works中 然后启动Worker中的线程开始执行任务*/
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
java多线程系列16 线程池的更多相关文章
- Java多线程系列--“JUC线程池”06之 Callable和Future
概要 本章介绍线程池中的Callable和Future.Callable 和 Future 简介示例和源码分析(基于JDK1.7.0_40) 转载请注明出处:http://www.cnblogs.co ...
- Java多线程系列--“JUC线程池”02之 线程池原理(一)
概要 在上一章"Java多线程系列--“JUC线程池”01之 线程池架构"中,我们了解了线程池的架构.线程池的实现类是ThreadPoolExecutor类.本章,我们通过分析Th ...
- Java多线程系列--“JUC线程池”03之 线程池原理(二)
概要 在前面一章"Java多线程系列--“JUC线程池”02之 线程池原理(一)"中介绍了线程池的数据结构,本章会通过分析线程池的源码,对线程池进行说明.内容包括:线程池示例参考代 ...
- Java多线程系列--“JUC线程池”04之 线程池原理(三)
转载请注明出处:http://www.cnblogs.com/skywang12345/p/3509960.html 本章介绍线程池的生命周期.在"Java多线程系列--“基础篇”01之 基 ...
- Java多线程系列--“JUC线程池”05之 线程池原理(四)
概要 本章介绍线程池的拒绝策略.内容包括:拒绝策略介绍拒绝策略对比和示例 转载请注明出处:http://www.cnblogs.com/skywang12345/p/3512947.html 拒绝策略 ...
- Java多线程系列--“JUC线程池”01之 线程池架构
概要 前面分别介绍了"Java多线程基础"."JUC原子类"和"JUC锁".本章介绍JUC的最后一部分的内容——线程池.内容包括:线程池架构 ...
- java多线程系列(六)---线程池原理及其使用
线程池 前言:如有不正确的地方,还望指正. 目录 认识cpu.核心与线程 java多线程系列(一)之java多线程技能 java多线程系列(二)之对象变量的并发访问 java多线程系列(三)之等待通知 ...
- Java多线程系列 JUC线程池04 线程池原理解析(三)
转载 http://www.cnblogs.com/skywang12345/p/3509954.html https://blog.csdn.net/qq_22929803/article/det ...
- Java多线程系列 JUC线程池06 线程池原理解析(五)
ScheduledThreadPoolExecutor解析 ScheduledThreadPoolExecutor适用于延时执行,或者周期性执行的任务调度,ScheduledThreadPoolExe ...
随机推荐
- 2013-7-30 802.1X企业级加密
今天做了U9510的企业级加密标杆测试,写了企业级加密标杆设备的操作指南.最后做到server 2003却出了问题,peap能关联,但是TLS怎么都关联不上.用adb shell查看logcat日志, ...
- Ubuntu 16.04 LTS 常用快捷键
在Linux下Win键就是Super键 启动器 Win(长按) 打开启动器,显示快捷键 Win + Tab 通过启动器切换应用程序 Win + 1到9 与点击启动器上的图标效果一样 Win + Shi ...
- getattribute
属性访问拦截器 class Itcast(object): def __init__(self,subject1): self.subject1 = subject1 self.subject2 = ...
- IIC时序详解
Verilog IIC通信实验笔记 Write by Gianttank 我实验的是 AT24C08的单字节读,单字节写,页读和页写,在高于3.3V系统中他的通信速率最高400KHZ的,我实验里用的是 ...
- LeetCode【100. 相同的树】
看到这道题,第一思考是结构和节点完全相同 第一次,就没有思考null的情况 if(p.val == q.val && p.left.val == q.left.val &&am ...
- tips:Jquery的attr和prop的区别
Jquery的attr和prop的区别 描述:想做一个复选框checkbox全选的功能,当勾选全选后,将子项的复选框状态设置成一致的, 但遇到了一个问题,就是attr函数并不能改变子项的checkbo ...
- composer在phpstorm中安装代码库
E:\php\PHPTutorial\WWW\kmmhtt>composer install composer 安装地址 :https://getcomposer.org/download/
- OpenStack Q版本新功能以及各核心组件功能对比
OpenStack Q版本已经发布了一段时间了.今天, 小编来总结一下OpenStack Q版本核心组件的各项主要新功能, 再来汇总一下最近2年来OpenStack N.O.P.Q各版本核心组件的主要 ...
- java实现pdf按页切分成图片
package com.ces.component.pictrueCut.entity; import java.awt.Image; import java.awt.Rectangle; impor ...
- DateTimeOffset DateTime
DateTime只保存两部分信息:Ticks和KindTicks 一个Tick是100纳秒(1万Tick等于1毫秒)Ticks记录了从1/1/0001 12:00 AM到现在经过了多少100纳秒.Ki ...