学习使用scrapy itemspipeline过程
开始非常不理解from https://www.jianshu.com/p/18ec820fe706 找到了一个比较完整的借鉴,然后编写自己的煎蛋pipeline
首先在items里创建
image_urls = scrapy.Field() #
images = scrapy.Field() #这两个是必须的
image_paths = scrapy.Field() #这个是因为在pipeline中设置了image_paths,所以这里要有,但不是必须的
然后在settings里面打开pipeline
ITEM_PIPELINES = {'jiandan.pipelines.JianPipeline': 1} #这里是打开pipeline
IMAGES_STORE =r'F:\jiandan' #这里是存储位置,绝对路径;
然后在pipeline里编写jianpipeline
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem class JianPipeline(ImagesPipeline): def get_media_requests(self, item, info):
for image_url in item['image_urls']:
yield scrapy.Request(image_url) def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
item['image_paths'] = image_paths #在这里写了image_paths,所以要在items里面声明item
return item
#此段完全摘抄自别人的代码,然后在自己里面用,
在spider主程序中只要生成item就好了,别的不用管
yield JiandanItem({
'image_urls':urls , #只要生成这个image_urls,pipeline会自动下载这里面的链接
})
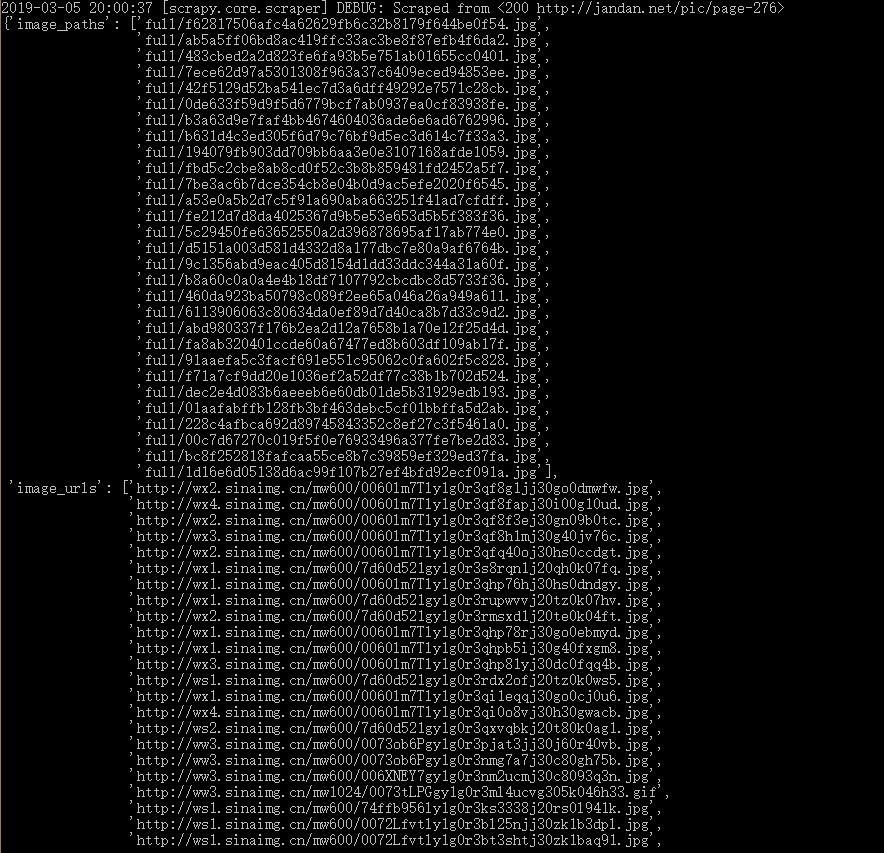
上面为实际运行情况
但是imagepipeline不能下载gif图片
******************************************************************************************************************************
改成filepipeline,更改path,这里传递的只是一个path,name,
def file_path(self, request, response=None, info=None):
path = super().file_path(request, response=None, info=None)
file_store = os.path.join(settings.FILES_STORE,'images')
if not os.path.exists(file_store):
os.mkdir(file_store)
file_name = os.path.join(file_store,path) # file_guid = request.url.split('/')[-1]
# filename = u'full/{0[name]}/{0[albumname]}/{1}'.format(item, file_guid)
return file_name
学习使用scrapy itemspipeline过程的更多相关文章
- 学习 Git的使用过程
原文链接: http://www.cnblogs.com/NickQ/p/8882726.html 学习 Git的使用过程 初次使用 git config --global user.name &qu ...
- linux内核学习之六 进程创建过程学习
一 关于linux进程概念的补充 关于进程的基本概念这里不多说,把自己的学习所得作一些补充: 1. 在linux内核中,系统最多可以有64个进程同时存在. 2.linux进程包含的关键要素:一段可执行 ...
- python爬虫学习之Scrapy框架的工作原理
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- 强化学习-MDP(马尔可夫决策过程)算法原理
1. 前言 前面的强化学习基础知识介绍了强化学习中的一些基本元素和整体概念.今天讲解强化学习里面最最基础的MDP(马尔可夫决策过程). 2. MDP定义 MDP是当前强化学习理论推导的基石,通过这套框 ...
- go微服务框架go-micro深度学习 rpc方法调用过程详解
摘要: 上一篇帖子go微服务框架go-micro深度学习(三) Registry服务的注册和发现详细解释了go-micro是如何做服务注册和发现在,服务端注册server信息,client获取serv ...
- 1.1(java学习笔记) 面向过程与面向对象
面向过程思考时,我们会先思考具体的步骤,第一步走什么,第二步做什么. 比如电脑新建文件夹,第一步:打开电脑 第二步:按下鼠标右键. 第三步:找到新建选项 第四步:点击新建选项下的文件夹 c语言是典型的 ...
- 七天从零基础学习android(3)--实现过程
首先这是我对自己编写程序的认识,要实现一个程序,根据之前编写C++的经验,要对所编写的软件有一个模糊的了解. 一个记账本软件,要实现的过程是,添加收支,显示本日,本月或本年的收支状态.然而基于是完全没 ...
- RocketMQ事务消息学习及刨坑过程
一.背景 MQ组件是系统架构里必不可少的一门利器,设计层面可以降低系统耦合度,高并发场景又可以起到削峰填谷的作用,从单体应用到集群部署方案,再到现在的微服务架构,MQ凭借其优秀的性能和高可靠性,得到了 ...
- USB2.0协议学习笔记---USB工作过程(类的方法)
前面学习了那么多的概念,这里需要记住一点分层概念即设备 ---> 配置 ---> 接口 ---> 端点,这种分层的概念结构 . 也可以理解为端点构成接口,接口组成配置,配置组成设备. ...
随机推荐
- Ubuntu下创建新用户后,不能使用管理员用户下安装的Anaconda
解决办法: 将管理员用户下Anaconda的安装环境添加到新用户下的环境变量里,具体操作: 系统切换到新用户下: vim .bashrc #添加Anaconda的环境变量 source .bashrc ...
- [hbase] hbase 基础使用
一.准备 hadoop 2.8.0 (提前配置好) hbase 1.2.6 zookeeper 3.4.9 (配置完成) jdk1.8 hadoop 集群信息: zk集群: 二.安装配置 1.下载(官 ...
- HTTP 请求头 WIKI 地址
https://en.wikipedia.org/wiki/List_of_HTTP_header_fields
- Ionic异常及解决
1. 编译时提示: ERROR: In <declare-styleable> FontFamilyFont, unable to find attribute android:fontV ...
- js实现十分钟内在页面无任何操作,页面跳转至登陆页
// 如果10分钟没有操作,退出到登录页 var timer; function startTimer(){ clearTimeout(timer); timer=setTimeout(functio ...
- npm install 错误 安装 chromedriver 失败的解决办法
npm 安装 chromedriver 失败的解决办法npm 安装 chromedriver 时,偶尔会出错,错误提示类似于:npm ERR! chromedriver@2.35.0 install: ...
- Mac os的使用
来北京入职java开发实习,公司标配macook.一开始不会使用macos系统,用起来很不适应,我是拒绝的.但是leader说mac是开发效率最高的工具了·.一开我很怀疑,后来觉得mac系统用起来还真 ...
- gym 101873
题还没补完 以下是牢骚:删了 现在只有六个...太恐怖了,我发现四星场我连300人的题都不会啊. C:最短路加一维状态就好了叭..嗯,一开始没看到输出的那句话 那个 "."也要输 ...
- 寻求js
寻找登录的post地址 在form表单中寻找action对应的url地址 post的数据是input标签中的name值作为键,真正的用户名密码作为值得字典,post的url地址就是action对应的u ...
- image的srcset属性
介绍 响应式页面中经常用到根据屏幕密度设置不同的图片.这个时候肯定会用到image标签的srcset属性.srcset属性用于设置不同屏幕密度下,image自动加载不同的图片.用法如下: <im ...