python之管道, 事件, 信号量, 进程池
管道:双向通信 2个进程之间相互通信
from multiprocessing import Process, Pipe def f1(conn):
from_zjc_msg = conn.recv()
print('我是子进程')
print('来自主进程的消息:', from_zjc_msg) if __name__ == '__main__':
conn1, conn2 = Pipe() # 创建一个管道对象, 全双工, 返回管道的两端, 但是一端发送的消息,只能另一端接受;自己这一端无法接收
# 可以将一端或两端发送给其他的进程, 那么多个进程之间就这一通过这一管道进行通信
p1 = Process(target=f1, args=(conn2, ))
p1.start()
conn1.send('有点困了') print('我是主进程')

Event用法:
from mutiprocessing import Event # 导入Event模块
event=Event() #设置一个事件对象, 初始标志位是False
event.set() # 将标志位改为True
event.clear() # 将标志位改为False
event.wait() # 等待设置标志位, 直到为True,再 继续向下执行
from multiprocessing import Process, Event e = Event() # 创建事件对象, 这个对象的初始状态为False
print('e的状态是', e.is_set()) print('程序运行到了这里') e.set() # 将e的状态改为True
print('e的状态是', e.is_set())
# e.clear() # 将e的状态改为False e.wait() # e这个事件对象如果值为False, 就在此处等待.
print('程序过了wait')

基于事件的进程通信
import time
from multiprocessing import Process, Event def f1(e):
time.sleep(2)
n = 100
print('子进程计算结果为:', n)
e.set() if __name__ == '__main__':
e = Event()
p = Process(target=f1, args=(e, ))
p.start() print('主进程等待.....')
e.wait()
print('结果已经出来, 可以拿到该值')

信号量(Semaphore),用于控制线程并发数
需要导入模块:
from multiprocessing import Process, Semaphore
重要方法有2个 对象.acquire() 和 对象.release()
import time
import random
from multiprocessing import Process, Semaphore def f1(i, s):
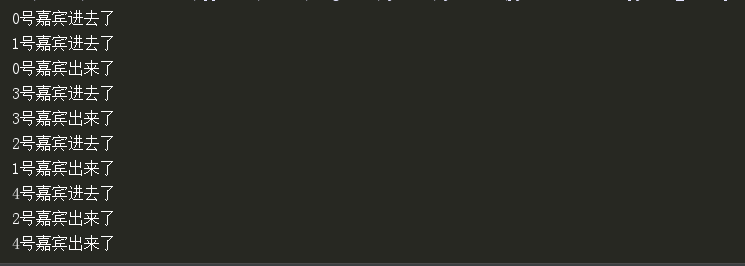
s.acquire() print('%s号嘉宾进去了' % i)
time.sleep(random.randint(1, 3))
print('%s号嘉宾出来了' % i)
s.release() if __name__ == '__main__':
s = Semaphore(2) # 计数器2, acquire 一次减一, 为0, 其他人等待, release加1
for i in range(5):
p = Process(target=f1, args=(i, s))
p.start()
进程池:定义一个池子,在里面放上固定数量的进程,有需求来了,就拿一个池中的进程来处理任务,等到处理完毕,进程并不关闭,而是将进程再放回进程池中继续等待任务。
如果有很多任务需要执行,池中的进程数量不够,任务就要等待之前的进程执行任务完毕归来,拿到空闲进程才能继续执行。也就是说,池中进程的数量是固定的,
那么同一时间最多有固定数量的进程在运行。
# # 进程池和多进程执行时间的对比
import time
from multiprocessing import Process, Pool def f(n):
for i in range(5):
n += i
if __name__ == '__main__':
# 统计进程池执行100个任务的时间
s_time = time.time()
pool = Pool(4) # 里面这个参数是指定进程池中有多少个进程, 4表示4个进程, 如果不传参, 默认开启的进程数一般是cpu的个数
pool.map(f, range(100)) # 参数数据必须是可迭代的, 异步提交任务, 自带join功能
e_time = time.time()
dif_time = e_time - s_time # 统计100个进程, 来执行100个任务的执行时间
p_s_t = time.time() # 多进程起始时间
p_list = [ ]
for i in range(100):
p = Process(target=f, args=(i,))
p.start()
p_list.append(p)
[pp.join() for pp in p_list]
p_e_t = time.time()
p_dif_t = p_e_t - p_s_t
print('进程池的执行时间:', dif_time)
print('多进程的执行时间:', p_dif_t)

进程池同步方法:
import time
from multiprocessing import Process, Pool def f1(n):
# print(n)
time.sleep(2)
return n * 2 if __name__ == '__main__':
pool = Pool(2) for i in range(5):
print('xxxxx')
res = pool.apply(f1, args=(i, ))
print(res)

结果: 先执行xxxxx 过2s执行0, xxxxx 过2s执行2 xxxxx
进程池异步:
import time
from multiprocessing import Process, Pool def f1(n):
time.sleep(2)
return n * 2 if __name__ == '__main__':
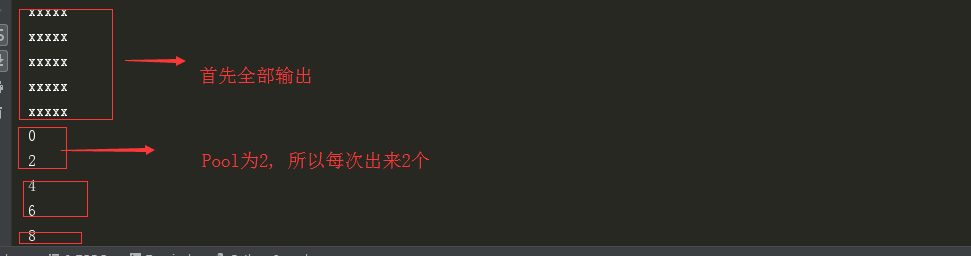
pool = Pool(2)
res_list = [ ]
for i in range(5):
print('xxxxx')
res = pool.apply_async(f1, args=(i,))
res_list.append(res)
for i in res_list:
print(i.get())
进程池的回调函数:
import os
from multiprocessing import Pool, Process def f1(n):
print('进程池里面的进程pid', os.getpid())
print(n)
return 2 * n def f2(n):
print('回调函数里面的进程pid', os.getpid())
print(n) if __name__ == '__main__':
pool = Pool(4)
res = pool.apply_async(f1, args=(5,), callback=f2)
pool.close()
pool.join()
print('主程序里面的进程pid', os.getpid())

python之管道, 事件, 信号量, 进程池的更多相关文章
- python之路--管道, 事件, 信号量, 进程池
一 . 管道 (了解) from multiprocessing import Process, Pipe def f1(conn): # 管道的recv 里面不用写数字 from_main_proc ...
- Python 并发编程(管道,事件,信号量,进程池)
管道 Conn1,conn2 = Pipe() Conn1.recv() Conn1.send() 数据接收一次就没有了 from multiprocessing import Process,Pip ...
- python并发编程之进程2(管道,事件,信号量,进程池)
管道 Conn1,conn2 = Pipe() Conn1.recv() Conn1.send() 数据接收一次就没有了 from multiprocessing import Process,Pip ...
- day 32 管道 事件 信号量 进程池
一.管道(多个时数据不安全) Pipe 类 (像队列一样,数据只能取走一次) conn1,conn2 = Pipe() 建立管道 .send() 发送 .recv() 接收 二.事 ...
- 并发编程7 管道&事件&信号量&进程池(同步和异步方法)
1,管道 2.事件 3.信号量 4.进程池的介绍&&进程池的map方法&&进程池和多进程的对比 5.进程池的同步方法和异步方法 6.重新解释同步方法和异步方法 7.回调 ...
- python--管道, 事件, 信号量, 进程池
一 . 管道 (了解) from multiprocessing import Process, Pipe def f1(conn): # 管道的recv 里面不用写数字 from_main_proc ...
- Python多进程库multiprocessing中进程池Pool类的使用[转]
from:http://blog.csdn.net/jinping_shi/article/details/52433867 Python多进程库multiprocessing中进程池Pool类的使用 ...
- python 管道 事件(Event) 信号量 进程池(map/同步/异步)回调函数
####################总结######################## 管道:是进程间通信的第二种方式,但是不推荐使用,因为管道会导致数据不安全的情况出现 事件:当我运行主进程的 ...
- day 32 管道,信号量,进程池,线程的创建
1.管道(了解) Pipe(): 在进程之间建立一条通道,并返回元组(conn1,conn2),其中conn1,conn2表示管道两端的连接对象,强调一点:必须在产生Process对象之前产生管道. ...
随机推荐
- 剑指offer编程题Java实现——面试题10二进制中1的个数
题目: 请实现一个函数,输入一个整数,输出该整数二进制表示中1的个数.例如,把9表示成二进制是1001,有2位是1,该函数输出2解法:把整数减一和原来的数做与运算,会把该整数二进制表示中的最低位的1变 ...
- Lerning Entity Framework 6 ------ Complex types
Complex types are classes that map to a subset of columns of a table.They don't contains key. They a ...
- go语言异常处理
go语言异常处理 error接口 go语言引入了一个关于错误错里的标准模式,即error接口,该接口的定义如下: type error interface{ Error() string } 对于要返 ...
- Android 开发工具推荐
简评: 自己过去在 Android 开发中发现的好工具,在这里分享给大家.: ) Library methods count 每一个 Android App 的开发中都会用到很多的库,这个工具能够让你 ...
- linux系统学习方法分享
初学者可以自己安装虚拟机,然后把 linux 常用命令例如 cd.ls.chmod.useradd.vi 等等多练习几十遍,把自己敲打命令的熟练程度提升上来.然后根据文档搭建 Linux 下常见的各种 ...
- 关于c++11中的thread库
c++11中新支持了thread这个库,常见的创建线程.join.detach都能支持. join是在main函数中等待线程执行完才继续执行main函数,detach则是把该线程分离出来,不管这个线程 ...
- Xamarin.Android 调用本地相册
调用本地相册选中照片在ImageView上显示 代码: using System; using System.Collections.Generic; using System.Linq; using ...
- (转)mtr命令详解诊断网络路由
原文:https://blog.51cto.com/6226001001/1941355 http://www.zzbiji.com/2212.html----Linux下使用mtr做路由图进行网络分 ...
- Django--视图函数views
1 视图函数 一个视图函数,简称视图,是一个简单的Python 函数,它接受Web请求并且返回Web响应.响应可以是一张网页的HTML内容,一个重定向,一个404错误,一个XML文档,或者一张图片. ...
- 2.WF 4.5 流程引擎设计思路
本文主要给大家分享下基于WF 4.5框架的流程引擎设计思路 1.流程启动时的数据写入EventMsgPP对象中,ObjectAssemblyType记录流程启动时需要的类型,ObjectContent ...