03.搭建Spark集群(CentOS7+Spark2.1.1+Hadoop2.8.0)
接上一篇:https://www.cnblogs.com/yjm0330/p/10077076.html
一、下载安装scala
1、官网下载
2、spar01和02都建立/opt/scala目录,解压tar -zxvf scala-2.12.8.tgz
3、配置环境变量
vi /etc/profile 增加一行
export SCALA_HOME=/opt/scala/scala-2.12.8
同时把hadoop的环境变量增加进去,完整版是:
export JAVA_HOME=/opt/java/jdk1.8.0_191
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export SCALA_HOME=/opt/scala/scala-2.12.8
export CLASSPATH=$:CLASSPATH:${JAVA_HOME}/lib/
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${SCALA_HOME}/bin:$PATH
然后source /etc/profile
4、验证
scala -version
5、同步spark02配置文件
scp /etc/profile spark02:/etc
二、下载安装spark
1、下载,解压,同scala,建立/opt/spark目录
2、配置环境变量
export SPARK_HOME=/opt/spark/spark-2.4.0-bin-hadoop2.7
完整版更新:
export JAVA_HOME=/opt/java/jdk1.8.0_191
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export SCALA_HOME=/opt/scala/scala-2.12.8
export SPARK_HOME=/opt/spark/spark-2.4.0-bin-hadoop2.7
export CLASSPATH=$:CLASSPATH:${JAVA_HOME}/lib/
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${SCALA_HOME}/bin:$PATH
source /etc/profile
scp /etc/profile spark02:/etc
3、配置conf下文件
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
vi spark-env.sh
export SCALA_HOME=/opt/scala/scala-2.12.8
export JAVA_HOME=/opt/java/jdk1.8.0_191
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/opt/spark/spark-2.4.0-bin-hadoop2.7
export SPARK_MASTER_IP=spark01
export SPARK_EXECUTOR_MEMORY=2G
vi slaves
spark02
同步到spark02
scp /opt/spark/spark-2.4.0-bin-hadoop2.7/conf/spark-env.sh spark02:/opt/spark/spark-2.4.0-bin-hadoop2.7/conf/
scp /opt/spark/spark-2.4.0-bin-hadoop2.7/conf/slaves spark02:/opt/spark/spark-2.4.0-bin-hadoop2.7/conf/
三、测试spark
因为spark是依赖于hadoop提供的分布式文件系统的,所以在启动spark之前,先确保hadoop在正常运行。
在hadoop正常运行的情况下,在spark01(也就是hadoop的namenode,spark的marster节点)上执行命令:
cd /opt/spark/spark-2.4.0-bin-hadoop2.7/sbin
执行启动脚本:./start-all.sh
在浏览器里访问Mster机器,我的Spark集群里Master机器是spark01,IP地址是192.168.2.245,访问8080端口,URL是:http://192.168.2.245:8080/
用local模式运行一个计算圆周率的Demo。按照下面的步骤来操作。
第一步,进入到Spark的根目录,也就是执行下面的脚本:
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master local examples/jars/spark-examples_2.11-2.4.0.jar
yarn-client模式:
注意执行之前关闭010203的防火墙:
centos7.0(默认是使用firewall作为防火墙,如若未改为iptables防火墙,使用以下命令查看和关闭防火墙)
查看防火墙状态:firewall-cmd --state
关闭防火墙:systemctl stop firewalld.service
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client examples/jars/spark-examples_2.11-2.4.0.jar
四、遇到的问题
1、jps命令无法找到
[root@namenode ~]# jps
bash: jps: command not found...
[root@namenode ~]# find / -name jps
find: ‘/run/user/1001/gvfs’: Permission denied
[root@namenode ~]# rpm -qa |grep -i jdk
java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64
java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64
java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64
java-1.7.0-openjdk-headless-1.7.0.91-2.6.2.3.el7.x86_64
[root@namenode ~]# yum list *openjdk-devel*
需要安装openjdk-devel包
[root@namenode ~]# yum install java-1.8.0-openjdk-devel.x86_64
[root@namenode ~]# which jps
/usr/bin/jps
[root@namenode ~]# jps
12995 Jps
10985 ResourceManager
11179 NodeManager
10061 NameNode
10301 DataNode
10655 SecondaryNameNode
2、XShell上传文件到Linux服务器上
在学习Linux过程中,我们常常需要将本地文件上传到Linux主机上,这里简单记录下使用Xsheel工具进行文件传输
1:首先连接上一台Linux主机
2:输入rz命令,看是否已经安装了lrzsz,如果没有安装则执行 yum -y install lrzsz命令进行安装。
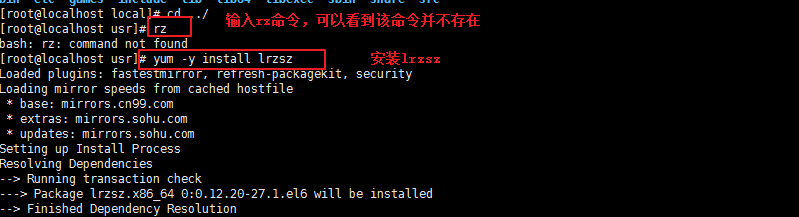
3:安装成功后,输入rpm命令确认是否正确安装

4: 使用 rz -y命令进行文件上传,此时会弹出上传的窗口:
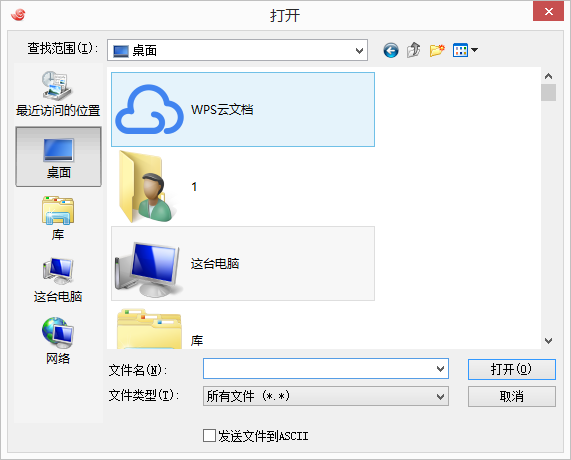
5:选择要上传的文件,点击确定即可将本地文件上传到Linux上,如图表示成功上传文件

6:使用ls命令可以看到文件已经上传到了当前目录下

03.搭建Spark集群(CentOS7+Spark2.1.1+Hadoop2.8.0)的更多相关文章
- 使用Docker搭建Spark集群(用于实现网站流量实时分析模块)
上一篇使用Docker搭建了Hadoop的完全分布式:使用Docker搭建Hadoop集群(伪分布式与完全分布式),本次记录搭建spark集群,使用两者同时来实现之前一直未完成的项目:网站日志流量分析 ...
- 实验室中搭建Spark集群和PyCUDA开发环境
1.安装CUDA 1.1安装前工作 1.1.1选取实验器材 实验中的每台计算机均装有双系统.选择其中一台计算机作为master节点,配置有GeForce GTX 650显卡,拥有384个CUDA核心. ...
- 从0到1搭建spark集群---企业集群搭建
今天分享一篇从0到1搭建Spark集群的步骤,企业中大家亦可以参照次集群搭建自己的Spark集群. 一.下载Spark安装包 可以从官网下载,本集群选择的版本是spark-1.6.0-bin-hado ...
- 搭建spark集群
搭建spark集群 spark1.6和hadoop2.61.准备hadoop环境:2.准备下载包:3.解压安装包:tar -xf spark-1.6.0-bin-hadoop2.6.tgz4.修改配置 ...
- 如何基于Jupyter notebook搭建Spark集群开发环境
摘要:本文介绍如何基于Jupyter notebook搭建Spark集群开发环境. 本文分享自华为云社区<基于Jupyter Notebook 搭建Spark集群开发环境>,作者:apr鹏 ...
- 大数据平台搭建-spark集群安装
版本要求 java 版本:1.8.*(1.8.0_60) 下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downl ...
- 利用最新的CentOS7.5,hadoop3.1,spark2.3.2搭建spark集群
1. 桥接模式,静态ip上外网:vi /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE=EthernetPROXY_METHOD=noneBROWSER_ ...
- CDH搭建Hadoop集群(Centos7)
一.说明 节点(CentOS7.5) Server || Agent CPU node11 Server || Agent 4G node12 Agent 2G node13 Agent 2G 二 ...
- docker使用Dockerfile搭建spark集群
1.创建Dockerfile文件,内容如下 # 基础镜像,包括jdk FROM openjdk:8u131-jre-alpine #作者 LABEL maintainer "tony@163 ...
随机推荐
- Java学习---InetAddress类的学习
基础知识 1.InetAddress类 在网络API套接字,InetAddress类和它的子类型对象使用域名DNS系统,处理主机名到主机IPv4或IPv6地址的转换.如图1-1所示. 由于InetAd ...
- 沉淀,再出发:web前端的一些认识
沉淀,再出发:web前端的一些认识 一.前言 作为程序员,我一直认为全栈是一种最基本的能力,没有了这种目标就会发现自己越往后面发展路就越窄,很多自己不了解的东西会阻塞自己去理解整个系统的开发过程和效率 ...
- DZ拿shell总结
今天碰到一个dz的站,好久没拿了 ,拿下shell觉得应该总结一下 Uc_server默认密码 其实有了UC_SERVER就是有了网站的全部权限了,有了UC_SERVER你可以重置管理员密码 可以进后 ...
- SQL简单基础(1)
对于SQL不再做过多的介绍,毕竟作为一个初学者对于SQL(结构化查询语言)也好,关系型数据库也好理解都并不是很深,只知道一些基本的概念. 本系列旨在介绍一些简单开发中用得上的SQL语句以及其使用方法, ...
- Oracle数据库用户名密码【转载自百度经验】
登录到安装oracle数据库服务器的操作系统.打开命令窗口:(我的演示机器是windows) 查看环境变量ORACLE_SID的设置情况: windows: echo %ORACLE_SID% l ...
- CString char BSTR 转换
关于字符集不一的历史原因,可以参考: UNICODE与ANSI的区别 以下是网上转载的资料.我将辅以自己的实例,说明并总结关系. 一.CString, int, string, char*之间的转换 ...
- BZOJ1369:[Baltic2003]Gem(树形DP)
Description 给出一棵树,要求你为树上的结点标上权值,权值可以是任意的正整数 唯一的限制条件是相临的两个结点不能标上相同的权值,要求一种方案,使得整棵树的总价值最小. Input 先给出一个 ...
- python反序列化
import pickle import os class A(object): def __reduce__(self): a = """python -c 'impo ...
- 【bbs】logout.php
字体大小通过js设定,并结合@media,可实现自适应. 图片自适应窗口 实现流水灯手机端不滚动,script嵌套 多余文字省略号显示 http://www.cnblogs.com/yujihang ...
- 【jQuery】jQuery与Ajax的应用
1.demo1 <script language="javascript" type="text/javascript"> //通过这个函数来异步获 ...