hdfs HA原理
早期的hadoop版本,NN是HDFS集群的单点故障点,每一个集群只有一个NN,如果这个机器或进程不可用,整个集群就无法使用。为了解决这个问题,出现了一堆针对HDFS HA的解决方案(如:Linux HA, VMware FT, shared NAS+NFS, BookKeeper, QJM/Quorum Journal Manager, BackupNode等); 在HA具体实现方法不同的情况下,HA框架的流程是一致的, 不一致的就是如何存储和管理日志。在Active NN和Standby NN之间要有个共享的存储日志的地方,Active NN把EditLog写到这个共享的存储日志的地方,Standby NN去读取日志然后执行,这样Active和Standby NN内存中的HDFS元数据保持着同步。一旦发生主从切换Standby NN可以尽快接管Active NN的工作。
SPOF方案回顾:
- Secondary NameNode:它不是HA,它只是阶段性的合并edits和fsimage,以缩短集群启动的时间。当NN失效的时候,Secondary NN并无法立刻提供服务,Secondary NN甚至无法保证数据完整性:如果NN数据丢失的话,在上一次合并后的文件系统的改动会丢失
- Backup NameNode (HADOOP-4539):它在内存中复制了NN的当前状态,算是Warm Standby,可也就仅限于此,并没有failover等。它同样是阶段性的做checkpoint,也无法保证数据完整性
- 手动把name.dir指向NFS(Network File System),这是安全的Cold Standby,可以保证元数据不丢失,但集群的恢复则完全靠手动
- Facebook AvatarNode:Facebook有强大的运维做后盾,所以Avatarnode只是Hot Standby,并没有自动切换,当主NN失效的时候,需要管理员确认,然后手动把对外提供服务的虚拟IP映射到Standby NN,这样做的好处是确保不会发生脑裂的场景。其某些设计思想和Hadoop 2.0里的HA非常相似,从时间上来看,Hadoop 2.0应该是借鉴了Facebook的做法
- Facebook AvatarNode 原理示例图

- PrimaryNN与StandbyNN之间通过NFS来共享FsEdits、FsImage文件,这样主备NN之间就拥有了一致的目录树和block信息;而block的位置信息,可以根据DN向两个NN上报的信息过程中构建起来。这样再辅以虚IP,可以较好达到主备NN快速热切的目的。但是显然,这里的NFS又引入了新的SPOF
- 在主备NN共享元数据的过程中,也有方案通过主NN将FsEdits的内容通过与备NN建立的网络IO流,实时写入备NN,并且保证整个过程的原子性。这种方案,解决了NFS共享元数据引入的SPOF,但是主备NN之间的网络连接又会成为新的问题
hadoop2.X ha 原理:
- hadoop2.x之后,Clouera提出了QJM/Qurom Journal Manager,这是一个基于Paxos算法实现的HDFS HA方案,它给出了一种较好的解决思路和方案,示意图如下:
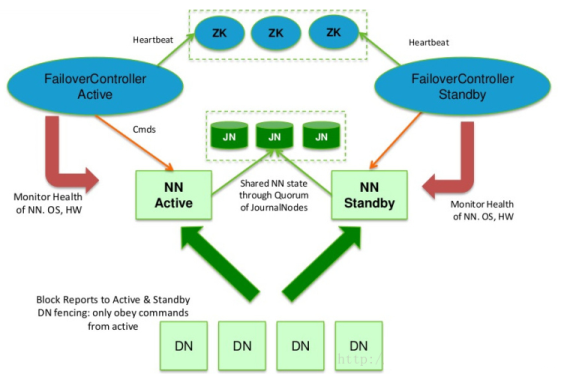
- 基本原理就是用2N+1台 JN 存储EditLog,每次写数据操作有大多数(>=N+1)返回成功时即认为该次写成功,数据不会丢失了。当然这个算法所能容忍的是最多有N台机器挂掉,如果多于N台挂掉,这个算法就失效了。这个原理是基于Paxos算法
- 在HA架构里面SecondaryNameNode这个冷备角色已经不存在了,为了保持standby NN时时的与主Active NN的元数据保持一致,他们之间交互通过一系列守护的轻量级进程JournalNode
- 任何修改操作在 Active NN上执行时,JN进程同时也会记录修改log到至少半数以上的JN中,这时 Standby NN 监测到JN 里面的同步log发生变化了会读取 JN 里面的修改log,然后同步到自己的的目录镜像树里面,如下图:
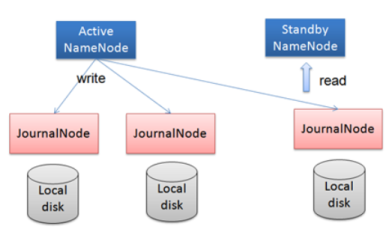
- 当发生故障时,Active的 NN 挂掉后,Standby NN 会在它成为Active NN 前,读取所有的JN里面的修改日志,这样就能高可靠的保证与挂掉的NN的目录镜像树一致,然后无缝的接替它的职责,维护来自客户端请求,从而达到一个高可用的目的
- QJM方式来实现HA的主要优势:
- 不需要配置额外的高共享存储,降低了复杂度和维护成本
- 消除spof
- 系统鲁棒性(Robust:健壮)的程度是可配置
- JN不会因为其中一台的延迟而影响整体的延迟,而且也不会因为JN的数量增多而影响性能(因为NN向JN发送日志是并行的)
hadoop2.x ha 详述:
- datanode的fencing: 确保只有一个NN能命令DN。HDFS-1972中详细描述了DN如何实现fencing
- 每个NN改变状态的时候,向DN发送自己的状态和一个序列号
- DN在运行过程中维护此序列号,当failover时,新的NN在返回DN心跳时会返回自己的active状态和一个更大的序列号。DN接收到这个返回则认为该NN为新的active
- 如果这时原来的active NN恢复,返回给DN的心跳信息包含active状态和原来的序列号,这时DN就会拒绝这个NN的命令
- 客户端fencing:确保只有一个NN能响应客户端请求,让访问standby nn的客户端直接失败。在RPC层封装了一层,通过FailoverProxyProvider以重试的方式连接NN。通过若干次连接一个NN失败后尝试连接新的NN,对客户端的影响是重试的时候增加一定的延迟。客户端可以设置重试此时和时间
- Hadoop提供了ZKFailoverController角色,部署在每个NameNode的节点上,作为一个deamon进程, 简称zkfc,示例图如下:

- FailoverController主要包括三个组件:
- HealthMonitor: 监控NameNode是否处于unavailable或unhealthy状态。当前通过RPC调用NN相应的方法完成
- ActiveStandbyElector: 管理和监控自己在ZK中的状态
- ZKFailoverController 它订阅HealthMonitor 和ActiveStandbyElector 的事件,并管理NameNode的状态
- ZKFailoverController主要职责:
- 健康监测:周期性的向它监控的NN发送健康探测命令,从而来确定某个NameNode是否处于健康状态,如果机器宕机,心跳失败,那么zkfc就会标记它处于一个不健康的状态
- 会话管理:如果NN是健康的,zkfc就会在zookeeper中保持一个打开的会话,如果NameNode同时还是Active状态的,那么zkfc还会在Zookeeper中占有一个类型为短暂类型的znode,当这个NN挂掉时,这个znode将会被删除,然后备用的NN,将会得到这把锁,升级为主NN,同时标记状态为Active
- 当宕机的NN新启动时,它会再次注册zookeper,发现已经有znode锁了,便会自动变为Standby状态,如此往复循环,保证高可靠,需要注意,目前仅仅支持最多配置2个NN
- master选举:如上所述,通过在zookeeper中维持一个短暂类型的znode,来实现抢占式的锁机制,从而判断那个NameNode为Active状态
hdfs HA原理的更多相关文章
- hadoop(二):hdfs HA原理及安装
早期的hadoop版本,NN是HDFS集群的单点故障点,每一个集群只有一个NN,如果这个机器或进程不可用,整个集群就无法使用.为了解决这个问题,出现了一堆针对HDFS HA的解决方案(如:Linux ...
- 【Hadoop学习之四】HDFS HA搭建(QJM)
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 由于NameNode对于整个HDF ...
- HDFS HA架构以及源代码引导
HA体系架构 相关知识介绍 HDFS master/slave架构,HDFS节点分为NameNode节点和DataNode节点. NameNode存有HDFS的元数据:主要由FSImage和EditL ...
- HDFS HA: 高可靠性分布式存储系统解决方案的历史演进
1. HDFS 简介 HDFS,为Hadoop这个分布式计算框架提供高性能.高可靠.高可扩展的存储服务.HDFS的系统架构是典型的主/从架构,早期的架构包括一个主节点NameNode和多个从节点Da ...
- Namenode HA原理详解(脑裂)
转自:http://blog.csdn.net/tantexian/article/details/40109331 Namenode HA原理详解 社区hadoop2.2.0 release版本开始 ...
- 3.配置HDFS HA
安装zookeeper下载zookeeper编辑zookeeper配置文件创建myid文件启动zookeeper配置HDFS HA配置手动HA配置自动HA启动HDFS HA namenode负责管理整 ...
- 6,HDFS HA
目录 HDFS HA 一.HA(High Availability)的使用原因 二.HA的同步 三.HA的自动容灾 HDFS HA 一.HA(High Availability)的使用原因 1.1 在 ...
- HDFS 核心原理
HDFS 核心原理 2016-01-11 杜亦舒 HDFS(Hadoop Distribute File System)是一个分布式文件系统文件系统是操作系统提供的磁盘空间管理服务,只需要我们指定把文 ...
- 【解决】HDFS HA无法自动切换问题
[解决]HDFS HA无法自动切换问题 原因: 最早设置为root互相登录,可是zkfc服务是hdfs账号运行的,没有权限访问到root的id_rsa文件.更改为hdfs账号免密钥登录恢复正常. ...
随机推荐
- Nginx 链接
Nginx反向代理以及负载均衡配置:http://www.cnblogs.com/Miss-mickey/p/6734831.html
- js常用总结
常用总结,方便大家学习共享. 1.document.write(""); 输出语句 2.JS中的注释为// 3.传统的HTML文档顺序是:document->html-& ...
- 更改嵌入式Linux中开机画面----左上角小企鹅图标
一直想给嵌入式仪表加个开机LOGO,但是没有找到更换的方法.最近在网上收集了一些文章,整理一下一共自己参考.目前也还没有试过这种方法究竟是否可以.但察看Kernel源代码可以知道,Linux-2.6的 ...
- Runtime应用(三)实现NSCoding的自动归档和自动解档
当我们需要将一个对象进行归档时,都要让该对象的类遵守NSCoding协议,再实现归档和接档方法.例如有一个Person类,该类有两个成员变量 @property (nonatomic,copy) NS ...
- css基础---->学习html(一)
这里零散的总结一下观看css权威指南书的知识.生命中的诸多告别,比不辞而别更让人难过的,是说一句再见,就再也没见过. 一.首字母与首行的伪类 <dvi> <p>I love y ...
- js插件---->jquery通知插件toastr的使用
toastr是一款非常棒的基于jquery库的非阻塞通知提示插件,toastr可设定四种通知模式:成功,出错,警告,提示,而提示窗口的位置,动画效果都可以通过能数来设置.toastr需要jquery的 ...
- 深入浅出Docker(四):Docker的集成测试部署之道
1. 背景 敏捷开发已经流行了很长时间,如今有越来越多的企业开始践行敏捷开发所提倡的以人为中心.迭代.循序渐进的开发理念.在这样的场景下引入Docker技术,首要目的就是使用Docker提供的虚拟化方 ...
- [数据库系列之MySQL]Mysql优化笔记
大型网站提速之MySql优化 数据库优化包括的方面 数据库优化是一个综合性的技术,并不是通过某一种方式让数据库效率提高很多,而是通过多方面的提高,从而使得数据库提高很多. 主要包括: 1.表的设计合理 ...
- tomcat配置JMX
最近看JDK的命令行工具,使用Java VisualVM和Jconsole工具都可以监控java程序的运行情况(包括CUP和内存等的使用情况,线程的运行状态等) 在Java VisualVM 工具里可 ...
- SWT/JFace开发遇到org.eclipse.core.runtime.IProgressMonitor问题的解决办法(转载)
今日正在使用SWT和JFace开发一个系统,在搭建JFace平台时遇到了一个问题,运行HelloWorld程序抛出org.eclipse.core.runtime.IProgressMonitor的n ...