Apache Kylin Cube 的构建过程
不多说,直接上干货!
1、 Cube的物理模型

如上图所示,一个常用的3维立方体,包含:时间、地点、产品。假如data cell 中存放的是产量,则我们可以根据时间、地点、产品来确定产量,同时也可以根据时间、地点来确定所有产品的总产量等。
Apache Kylin就将所有(时间、地点、产品)的各种组合实现算出来,data cell 中存放度量,其中每一种组合都称为cuboid。估n维的数据最多有2^n个cuboid,不过Kylin通过设定维度的种类,可以减少cuboid的数目。
2 、Cube构建算法介绍
2.1 逐层算法(Layer Cubing)
我们知道,一个N维的Cube,是由1个N维子立方体、N个(N-1)维子立方体、N*(N-1)/2个(N-2)维子立方体、......、N个1维子立方体和1个0维子立方体构成,总共有2^N个子立方体组成,在逐层算法中,按维度数逐层减少来计算,每个层级的计算(除了第一层,它是从原始数据聚合而来),是基于它上一层级的结果来计算的。
比如,[Group by A, B]的结果,可以基于[Group by A, B, C]的结果,通过去掉C后聚合得来的;这样可以减少重复计算;当 0维度Cuboid计算出来的时候,整个Cube的计算也就完成了。
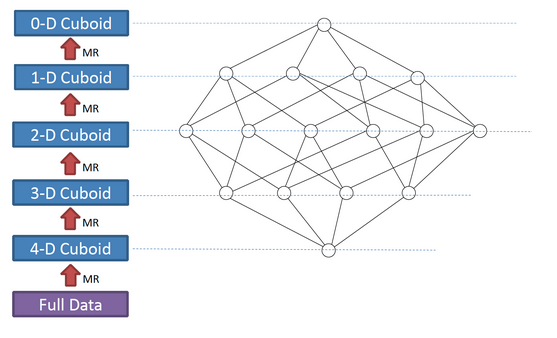
如上图所示,展示了一个4维的Cube构建过程。
此算法的Mapper和Reducer都比较简单。Mapper以上一层Cuboid的结果(Key-Value对)作为输入。由于Key是由各维度值拼接在一起,从其中找出要聚合的维度,去掉它的值成新的Key,并对Value进行操作,然后把新Key和Value输出,进而Hadoop MapReduce对所有新Key进行排序、洗牌(shuffle)、再送到Reducer处;Reducer的输入会是一组有相同Key的Value集合,对这些Value做聚合计算,再结合Key输出就完成了一轮计算。
每一轮的计算都是一个MapReduce任务,且串行执行; 一个N维的Cube,至少需要N次MapReduce Job。
算法优点
- 此算法充分利用了MapReduce的能力,处理了中间复杂的排序和洗牌工作,故而算法代码清晰简单,易于维护;
- 受益于Hadoop的日趋成熟,此算法对集群要求低,运行稳定;在内部维护Kylin的过程中,很少遇到在这几步出错的情况;即便是在Hadoop集群比较繁忙的时候,任务也能完成。
算法缺点
- 当Cube有比较多维度的时候,所需要的MapReduce任务也相应增加;由于Hadoop的任务调度需要耗费额外资源,特别是集群较庞大的时候,反复递交任务造成的额外开销会相当可观;
- 由于Mapper不做预聚合,此算法会对Hadoop MapReduce输出较多数据; 虽然已经使用了Combiner来减少从Mapper端到Reducer端的数据传输,所有数据依然需要通过Hadoop MapReduce来排序和组合才能被聚合,无形之中增加了集群的压力;
- 对HDFS的读写操作较多:由于每一层计算的输出会用做下一层计算的输入,这些Key-Value需要写到HDFS上;当所有计算都完成后,Kylin还需要额外的一轮任务将这些文件转成HBase的HFile格式,以导入到HBase中去;
- 总体而言,该算法的效率较低,尤其是当Cube维度数较大的时候;时常有用户问,是否能改进Cube算法,缩短时间。
2 .2 快速Cube算法(Fast Cubing)
快速Cube算法(Fast Cubing)是麒麟团队对新算法的一个统称,它还被称作“逐段”(By Segment) 或“逐块”(By Split) 算法。
该算法的主要思想是,对Mapper所分配的数据块,将它计算成一个完整的小Cube 段(包含所有Cuboid);每个Mapper将计算完的Cube段输出给Reducer做合并,生成大Cube,也就是最终结果;图2解释了此流程。
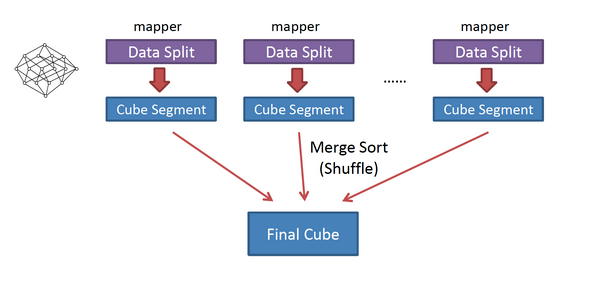
与旧算法相比,快速算法主要有两点不同
- Mapper会利用内存做预聚合,算出所有组合;Mapper输出的每个Key都是不同的,这样会减少输出到Hadoop MapReduce的数据量,Combiner也不再需要;
- 一轮MapReduce便会完成所有层次的计算,减少Hadoop任务的调配。
子立方体生成树的遍历
值得一提的还有一个改动,就是子立方体生成树(Cuboid Spanning Tree)的遍历次序;在旧算法中,Kylin按照层级,也就是广度优先遍历(Broad First Search)的次序计算出各个Cuboid;在快速Cube算法中,Mapper会按深度优先遍历(Depth First Search)来计算各个Cuboid。深度优先遍历是一个递归方法,将父Cuboid压栈以计算子Cuboid,直到没有子Cuboid需要计算时才出栈并输出给Hadoop;最多需要暂存N个Cuboid,N是Cube维度数。
采用DFS,是为了兼顾CPU和内存:
- 从父Cuboid计算子Cuboid,避免重复计算;
- 只压栈当前计算的Cuboid的父Cuboid,减少内存占用。
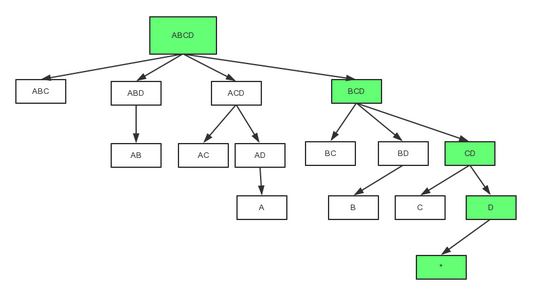
- 立方体生成数的遍历过程
上图是一个四维Cube的完整生成树;按照DFS的次序,在0维Cuboid 输出前的计算次序是 ABCD -> BCD -> CD -> D -> , ABCD, BCD, CD和D需要被暂存;在被输出后,D可被输出,内存得到释放;在C被计算并输出后,CD就可以被输出; ABCD最后被输出。
4.3 、Cube构建流程

主要步骤如下:
- 构建一个中间平表(Hive Table):将Model中的fact表和look up表构建成一个大的Flat Hive Table。
- 重新分配Flat Hive Tables。
- 从事实表中抽取维度的Distinct值。
- 对所有维度表进行压缩编码,生成维度字典。
- 计算和统计所有的维度组合,并保存,其中,每一种维度组合,称为一个Cuboid。
- 创建HTable。
- 构建最基础的Cuboid数据。
- 利用算法构建N维到0维的Cuboid数据。
- 构建Cube。
- 将Cuboid数据转换成HFile。
- 将HFile直接加载到HBase Table中。
- 更新Cube信息。
- 清理Hive。
Apache Kylin Cube 的构建过程的更多相关文章
- Apache Kylin Cube 的存储
不多说,直接上干货! 简单的说Cuboid的维度会映射为HBase的Rowkey,Cuboid的指标会映射为HBase的Value. Cube映射成HBase存储 如上图原始表所示:Hive表有两个维 ...
- KIP-5:Apache Kylin深度集成Hudi
Q1. What are you trying to do? Articulate your objectives using absolutely no jargon. Q2. What probl ...
- Kylin Cube构建过程优化
原文地址:https://kylin.apache.org/docs16/howto/howto_optimize_build.html Kylin将一个cube的build过程分解为若干个子步骤,然 ...
- 大数据分析神兽麒麟(Apache Kylin)
1.Apache Kylin是什么? 在现在的大数据时代,越来越多的企业开始使用Hadoop管理数据,但是现有的业务分析工具(如Tableau,Microstrategy等)往往存在很大的局限,如难以 ...
- 大数据分析界的“神兽”Apache Kylin有多牛?【转】
本文作者:李栋,来自Kyligence公司,也是Apache Kylin Committer & PMC member,在加入Kyligence之前曾就职于eBay.微软. 1.Apache ...
- Apache Kylin大数据分析平台的演进
转:http://mt.sohu.com/20160628/n456602429.shtml 我是来自Kyligence的李扬,是上海Kyligence的联合创始人兼CTO.今天我主要来和大家分享一下 ...
- 《基于Apache Kylin构建大数据分析平台》
Kyligence联合创始人兼CEO,Apache Kylin项目管理委员会主席(PMC Chair)韩卿 武汉市云升科技发展有限公司董事长,<智慧城市-大数据.物联网和云计算之应用>作者 ...
- kylin cube测试时,报错:org.apache.hadoop.security.AccessControlException: Permission denied: user=root, access=WRITE, inode="/user":hdfs:supergroup:drwxr-xr-x
异常: org.apache.hadoop.security.AccessControlException: Permission denied: user=root, access=WRITE, i ...
- 【转】使用Apache Kylin搭建企业级开源大数据分析平台
http://www.thebigdata.cn/JieJueFangAn/30143.html 本篇文章整理自史少锋4月23日在『1024大数据技术峰会』上的分享实录:使用Apache Kylin搭 ...
随机推荐
- eclipse 添加库
Window ->Preferences ->Java ->Build Path ->User Libraries New,起个名字,如myLibrary add jars,添 ...
- [原创] Karen and Supermarket 2
在回家的路上,凯伦决定到超市停下来买一些杂货. 她需要买很多东西,但因为她是学生,所以她的预算仍然很有限. 事实上,她只花了b美元. 超市出售N种商品.第i件商品可以以ci美元的价格购买.当然,每件商 ...
- unzip解压指定我文件夹
解压try.zip中指定的文件夹 unzip try.zip "try/*" shell中异常处理 { # your 'try' block executeCommandWhich ...
- 修改DEDE系统数据库表前缀
1,修改之前我们先备份下数据(哥们儿之前没有备份,我艹,害苦了),备份的操作过程是:网站后台------系统------数据库备份/还原-------然后按提交.默认保存的数据在data/backup ...
- Axios 请求配置参数详解
axios API 可以通过向 axios 传递相关配置来创建请求 axios(config) // 发送 POST 请求 axios({ method: 'post', url: ' ...
- Silverlight结合Web Service进行文件上传
search了非常多的文章,总算勉强实现了.有许多不完善的地方. 在HCLoad.Web项目下新建目录Pics复制一张图片到根目录下. 图片名:Bubble.jpg 右击->属性->生成操 ...
- 修改fuse库成功
使用的是fuse-2.9.2 在lib目录下的helper.c的fuse_main_real函数里打印一句话,然后将fuse库编译并install. 对ssfs进行编译,运行后,出现了打印的那句话! ...
- AutoIt获取Gridview中可以修改列的值
有一个界面如上图:黑色框框部分是一个整体,也是一个gridview,如果我想把框框中右侧数据获取出来,该如何操作? 我尝试过了很多途径,都无法成功. 今天,我发现,当鼠标焦点在黑色框框左侧的部分的时候 ...
- jmeter+jenkins+ant部署持续集成测试
原文地址:http://blog.csdn.net/kaluman/article/details/74535495 开头的注意事项: 1.所有的环境变量和代码,都需要使用英文的符号,变量之间都需要英 ...
- pdf解锁和脱水印
解锁工具下载http://pan.baidu.com/s/1o8FcKFC 使用方法: 第一步: 打开加密pdf文件保存即可 参考:http://www.epinv.com/post/157.html