python爬虫---从零开始(五)pyQuery库
什么是pyQuery:
强大又灵活的网页解析库。如果你觉得正则写起来太麻烦(我不会写正则),如果你觉得BeautifulSoup的语法太难记,如果你熟悉JQuery的语法,那么PyQuery就是你最佳的选择。
pyQuery的安装pip3 install pyquery即可安装啦。
pyQuery的基本用法:
初始化:
字符串初始化:
#!/usr/bin/env python
# -*- coding: utf-8 -*- html = """
<html><head><title>The Dormouse's story</head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters;and thier names were
<a href ="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>
<a href ="http://example.com/lacle" class="sister" id="link2">Lacie</a> and
<a href ="http://example.com/title" class="sister" id="link3">Title</a>; and they lived at the boottom of a well.</p>
<p class="story">...</p>
""" from pyquery import PyQuery as pq
doc = pq(html)
print(doc('a'))
运行结果:

URL初始化:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# URL初始化 from pyquery import PyQuery as pq
doc = pq('http://www.baidu.com')
print(doc('input'))
运行结果:

文件初始化:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 文件初始化 from pyquery import PyQuery as pq
doc = pq(filename='baidu.html')
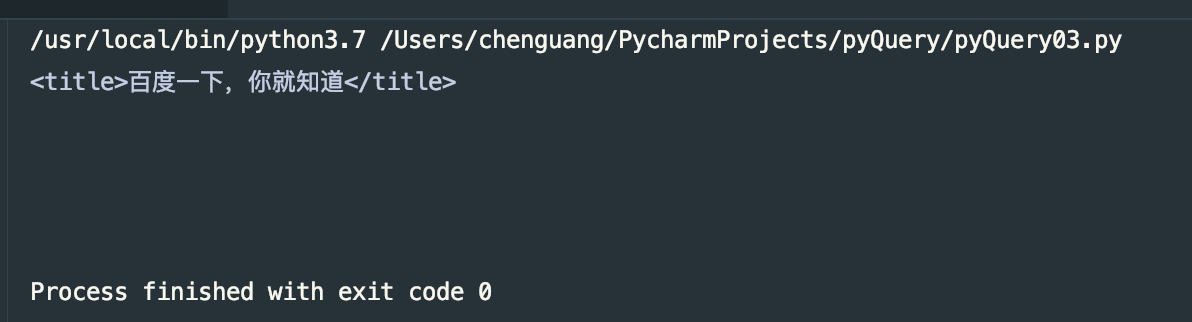
print(doc('title'))
运行结果:
选择方式和jquery一致,id、name、class都是如此,还有很多都和jquery一致。
基本CSS选择器:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Css选择器 html = """
<html><head><title>The Dormouse's story</head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters;and thier names were
<a href ="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>
<a href ="http://example.com/lacle" class="sister" id="link2">Lacie</a> and
<a href ="http://example.com/title" class="title" id="link3">Title</a>; and they lived at the boottom of a well.</p>
<p class="story">...</p>
"""
from pyquery import PyQuery as pq
doc = pq(html)
print(doc('.title'))
运行结果:

查找元素:
子元素:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 子元素 html = """
<html><head><title>The Dormouse's story</head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters;and thier names were
<a href ="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>
<a href ="http://example.com/lacle" class="sister" id="link2">Lacie</a> and
<a href ="http://example.com/title" class="title" id="link3">Title</a>; and they lived at the boottom of a well.</p>
<p class="story">...</p>
"""
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.title')
print(type(items))
print(items)
p = items.find('b')
print(type(p))
print(p)
该代码为查找id为title的标签,我们可以看到id为title的标签有两个一个是p标签,一个是a标签,然后我们再使用find方法,查找出我们需要的p标签,运行结果:

这里需要注意的是,我们所使用的find是查找每一个元素内部的标签.
children:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 子元素 html = """
<html><head><title>The Dormouse's story</head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters;and thier names were
<a href ="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>
<a href ="http://example.com/lacle" class="sister" id="link2">Lacie</a> and
<a href ="http://example.com/title" class="title" id="link3">Title</a>; and they lived at the boottom of a well.</p>
<p class="story">...</p>
"""
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.title')
print(items.children())
运行结果:

也可以在children()内添加选择器条件:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 子元素 html = """
<html><head><title>The Dormouse's story</head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters;and thier names were
<a href ="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>
<a href ="http://example.com/lacle" class="sister" id="link2">Lacie</a> and
<a href ="http://example.com/title" class="title" id="link3">Title</a>; and they lived at the boottom of a well.</p>
<p class="story">...</p>
"""
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.title')
print(items.children('b'))
输出结果和上面的一致。
父元素:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 子元素 html = """
<html><head><title>The Dormouse's story</head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters;and thier names were
<a href ="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>
<a href ="http://example.com/lacle" class="sister" id="link2">Lacie</a> and
<a href ="http://example.com/title" class="title" id="link3">Title</a>; and they lived at the boottom of a well.</p>
<p class="story">...</p>
"""
from pyquery import PyQuery as pq
doc = pq(html)
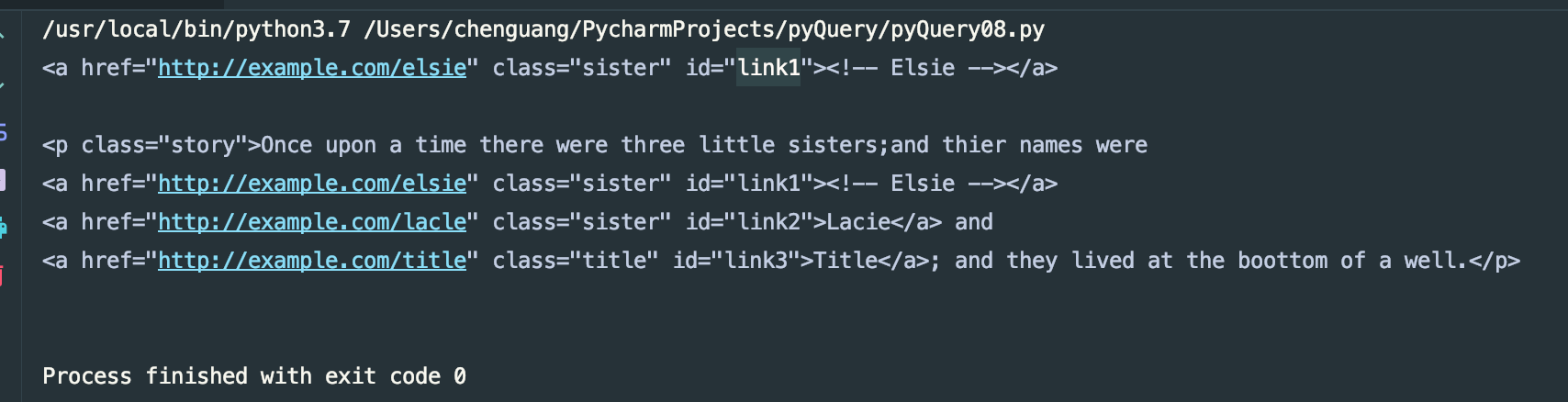
items = doc('#link1')
print(items)
print(items.parent())
运行结果:
这里只输出一个父元素。这里我们用parents方法会给予我们返回所有父元素,祖先元素
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 祖先元素 html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story" id="dromouse">Once upo a time were three little sister;and theru name were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/elsie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/elsie" class="sister" id="link3">Title</a>
<a href="http://example.com/elsie" class="body" id="link4">Title</a>
</p>
<p class="story">...</p>
"""
from pyquery import PyQuery as pq
doc = pq(html)
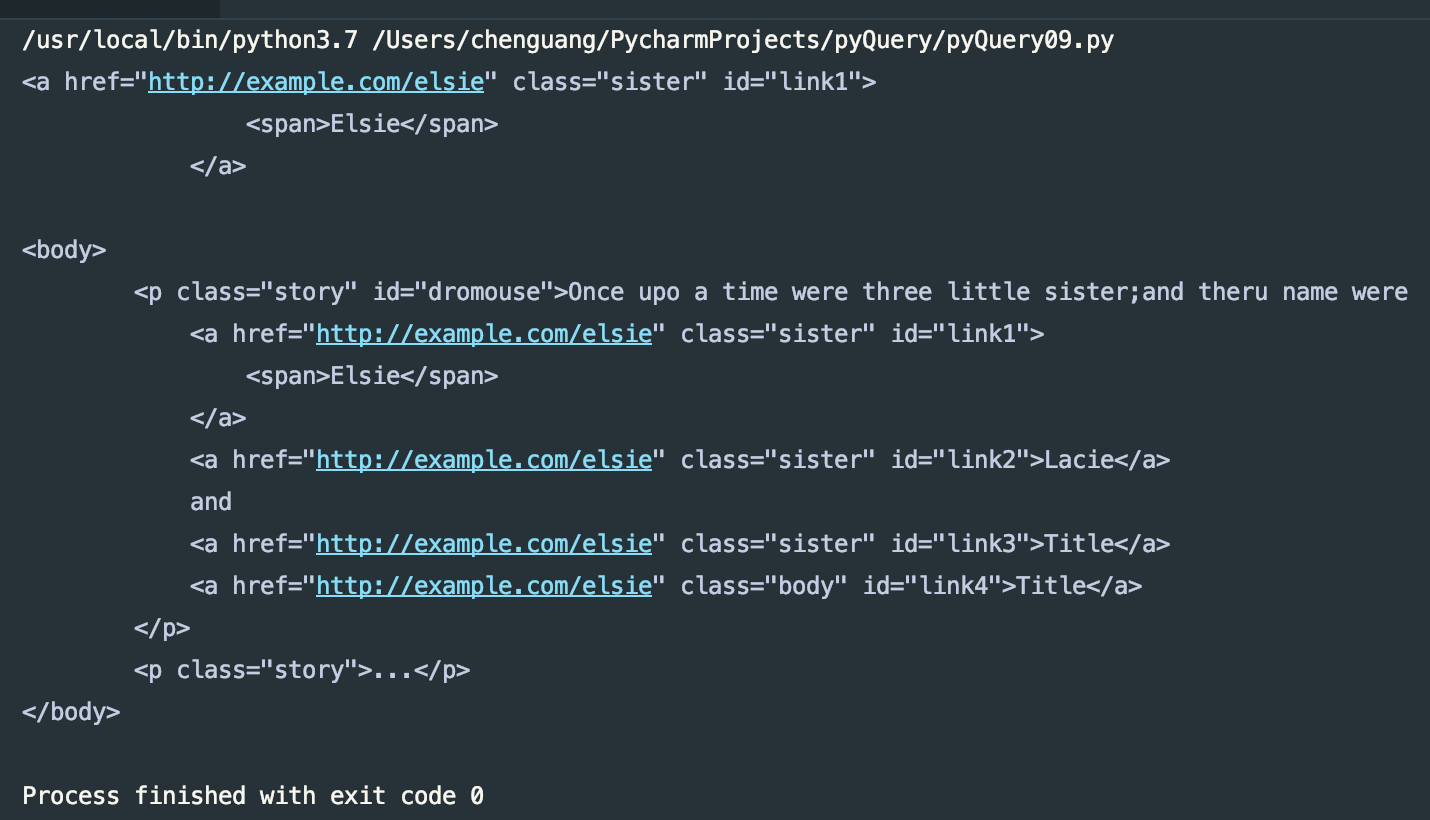
items = doc('#link1')
print(items)
print(items.parents('body'))
运行结果:
兄弟元素:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 兄弟元素 html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story" id="dromouse">Once upo a time were three little sister;and theru name were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/elsie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/elsie" class="sister" id="link3">Title</a>
<a href="http://example.com/elsie" class="body" id="link4">Title</a>
</p>
<p class="story">...</p>
"""
from pyquery import PyQuery as pq
doc = pq(html)
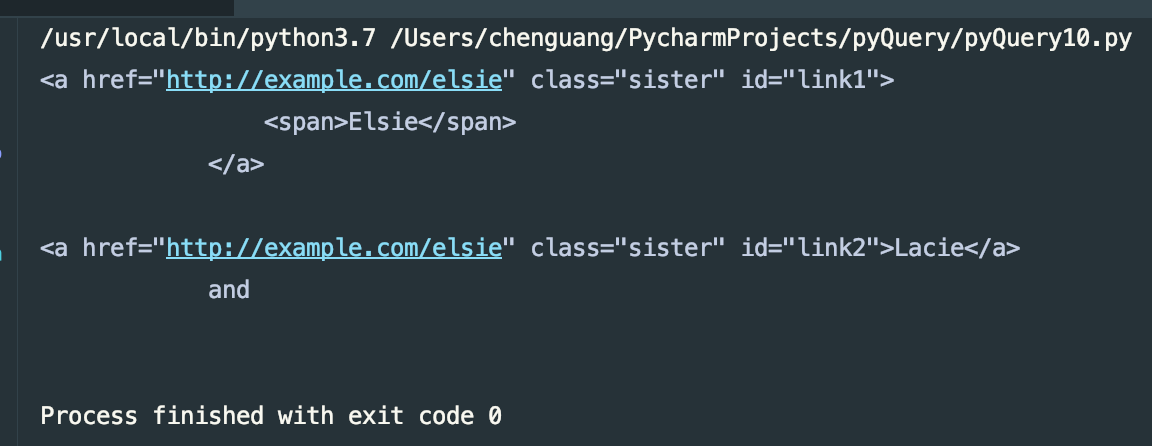
items = doc('#link1')
print(items)
print(items.siblings('#link2'))
运行结果:
上面就把查找元素的方法都说了,下面我来看一下如何遍历元素。
遍历
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 兄弟元素 html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story" id="dromouse">Once upo a time were three little sister;and theru name were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/elsie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/elsie" class="sister" id="link3">Title</a>
<a href="http://example.com/elsie" class="body" id="link4">Title</a>
</p>
<p class="story">...</p>
"""
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('a')
for k,v in enumerate(items.items()):
print(k,v)
运行结果:

获取信息:
获取属性:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 获取属性 html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story" id="dromouse">Once upo a time were three little sister;and theru name were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/elsie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/elsie" class="sister" id="link3">Title</a>
<a href="http://example.com/elsie" class="body" id="link4">Title</a>
</p>
<p class="story">...</p>
"""
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('a')
print(items)
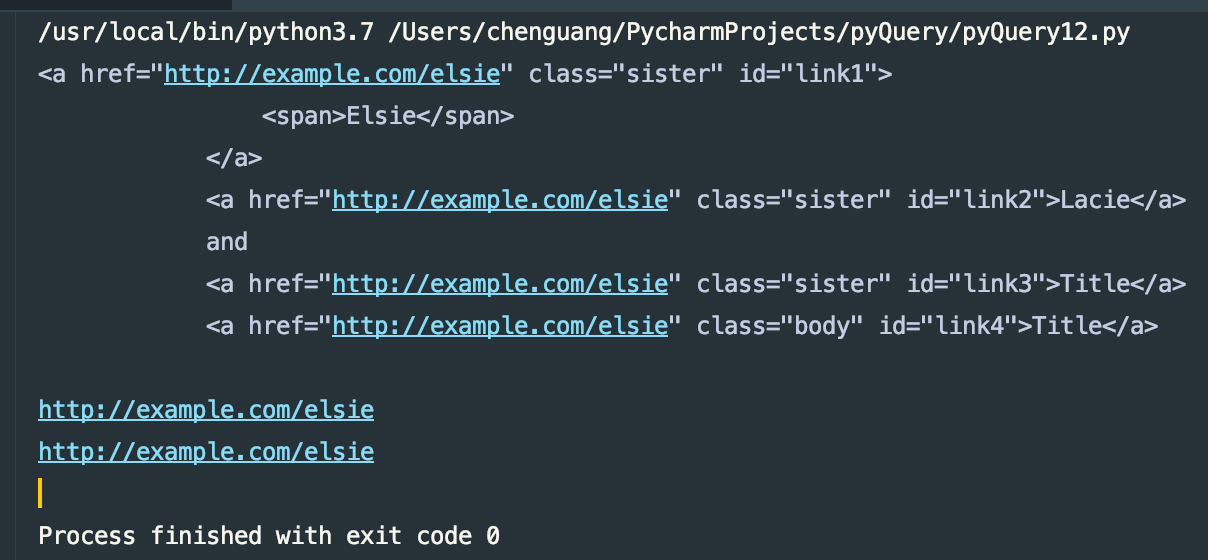
print(items.attr('href'))
print(items.attr.href)
运行结果:
获得文本:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 获取属性 html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story" id="dromouse">Once upo a time were three little sister;and theru name were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/elsie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/elsie" class="sister" id="link3">Title</a>
<a href="http://example.com/elsie" class="body" id="link4">Title</a>
</p>
<p class="story">...</p>
"""
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('a')
print(items)
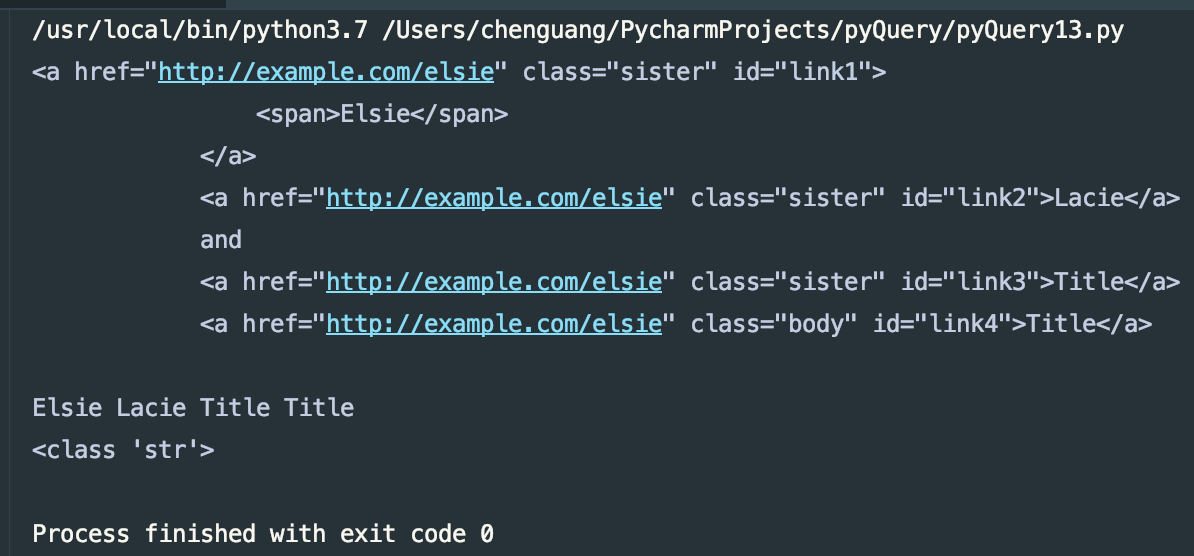
print(items.text())
print(type(items.text()))
运行结果:
获得HTML:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 获取属性 html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story" id="dromouse">Once upo a time were three little sister;and theru name were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/elsie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/elsie" class="sister" id="link3">Title</a>
<a href="http://example.com/elsie" class="body" id="link4">Title</a>
</p>
<p class="story">...</p>
"""
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('a')
print(items.html())
运行结果:

DOM操作:
addClass、removeClass
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# DOM操作,addClass、removeClass html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story" id="dromouse">Once upo a time were three little sister;and theru name were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/elsie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/elsie" class="sister" id="link3">Title</a>
<a href="http://example.com/elsie" class="body" id="link4">Title</a>
</p>
<p class="story">...</p>
"""
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('#link2')
print(items)
items.addClass('addStyle') # add_class
print(items)
items.remove_class('sister') # removeClass
print(items)
运行结果:

attr、css:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# DOM操作,attr,css html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story" id="dromouse">Once upo a time were three little sister;and theru name were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/elsie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/elsie" class="sister" id="link3">Title</a>
<a href="http://example.com/elsie" class="body" id="link4">Title</a>
</p>
<p class="story">...</p>
"""
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('#link2')
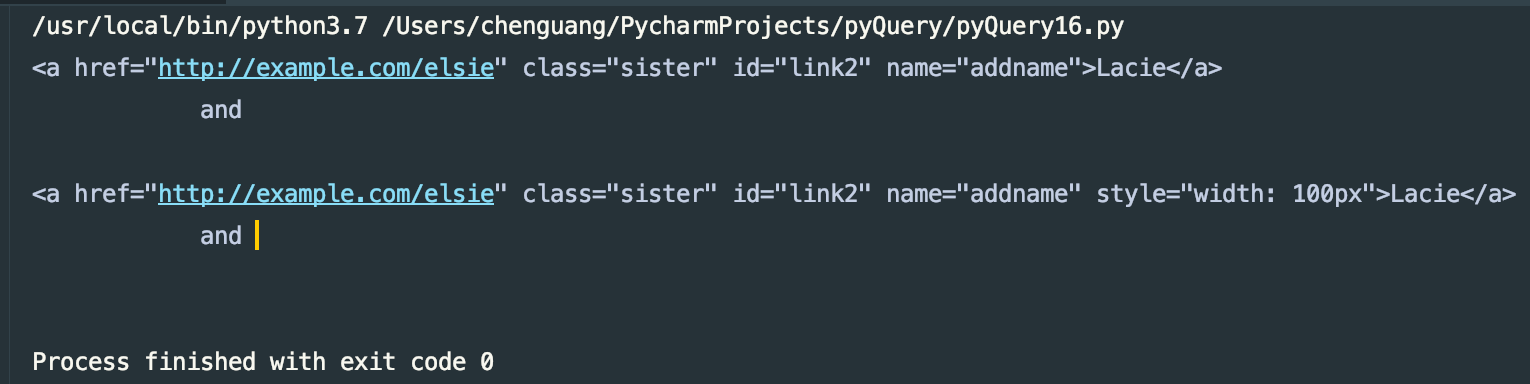
items.attr('name','addname')
print(items)
items.css('width','100px')
print(items)
可以给予新的属性,如果原来有该属性,会覆盖掉原有的属性
运行结果:
remove:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# DOM操作,remove html = """
<div class="wrap">
Hello World
<p>This is a paragraph.</p>
</div>
"""
from pyquery import PyQuery as pq
doc = pq(html)
wrap = doc('.wrap')
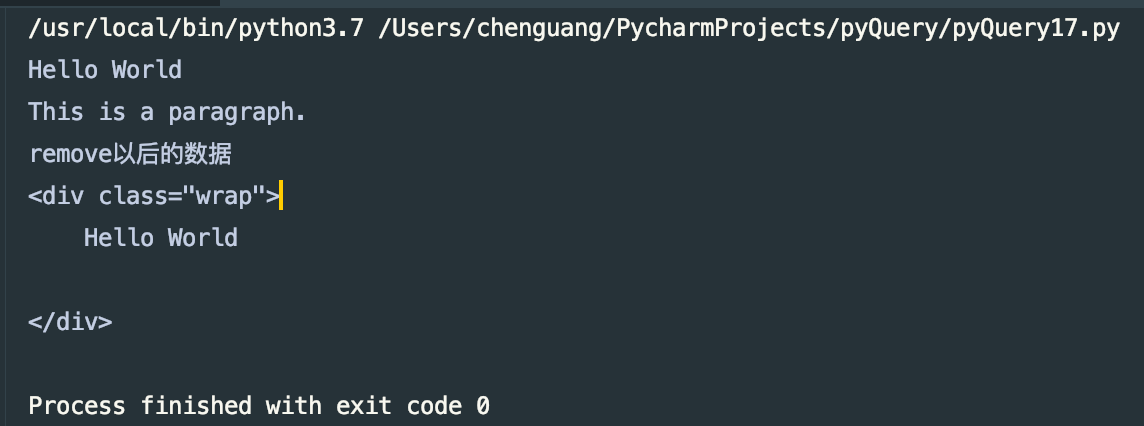
print(wrap.text())
wrap.find('p').remove()
print("remove以后的数据")
print(wrap)
运行结果:
还有很多其他的DOM方法,想了解更多的小伙伴可以阅读其官方文档,地址:https://pyquery.readthedocs.io/en/latest/api.html
伪类选择器:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# DOM操作,伪类选择器 html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story" id="dromouse">Once upo a time were three little sister;and theru name were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/elsie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/elsie" class="sister" id="link3">Title</a>
<a href="http://example.com/elsie" class="body" id="link4">Title</a>
</p>
<p class="story">...</p>
"""
from pyquery import PyQuery as pq
doc = pq(html)
# print(doc)
wrap = doc('a:first-child') # 第一个标签
print(wrap)
wrap = doc('a:last-child') # 最后一个标签
print(wrap)
wrap = doc('a:nth-child(2)') # 第二个标签
print(wrap)
wrap = doc('a:gt(2)') # 比2大的索引 标签 即为 0 1 2 3 4 从0开始的 不是1
print(wrap)
wrap = doc('a:nth-child(2n)') # 第 2的整数倍 个标签
print(wrap)
wrap = doc('a:contains(Lacie)') # 包含Lacie文本的标签
print(wrap)
这里不在详细的一一列举了,了解更多CSS选择器可以查看官方文档,由W3C提供地址:http://www.w3school.com.cn/css/index.asp
到这里我们就把pyQuery的使用方法大致的说完了,想了解更多,更详细的可以阅读官方文档,地址:https://pyquery.readthedocs.io/en/latest/
上述代码地址:https://gitee.com/dwyui/pyQuery.git
感谢大家的阅读,不正确的地方,还希望大家来斧正,鞠躬,谢谢
python爬虫---从零开始(五)pyQuery库的更多相关文章
- PYTHON 爬虫笔记六:PyQuery库基础用法
知识点一:PyQuery库详解及其基本使用 初始化 字符串初始化 html = ''' <div> <ul> <li class="item-0"&g ...
- PYTHON 爬虫笔记五:BeautifulSoup库基础用法
知识点一:BeautifulSoup库详解及其基本使用方法 什么是BeautifulSoup 灵活又方便的网页解析库,处理高效,支持多种解析器.利用它不用编写正则表达式即可方便实现网页信息的提取库. ...
- Python爬虫进阶五之多线程的用法
前言 我们之前写的爬虫都是单个线程的?这怎么够?一旦一个地方卡到不动了,那不就永远等待下去了?为此我们可以使用多线程或者多进程来处理. 首先声明一点! 多线程和多进程是不一样的!一个是 thread ...
- python爬虫之re正则表达式库
python爬虫之re正则表达式库 正则表达式是用来简洁表达一组字符串的表达式. 编译:将符合正则表达式语法的字符串转换成正则表达式特征 操作符 说明 实例 . 表示任何单个字符 [ ] 字符集,对单 ...
- Python爬虫实战五之模拟登录淘宝并获取所有订单
经过多次尝试,模拟登录淘宝终于成功了,实在是不容易,淘宝的登录加密和验证太复杂了,煞费苦心,在此写出来和大家一起分享,希望大家支持. 温馨提示 更新时间,2016-02-01,现在淘宝换成了滑块验证了 ...
- Python爬虫入门五之URLError异常处理
大家好,本节在这里主要说的是URLError还有HTTPError,以及对它们的一些处理. 1.URLError 首先解释下URLError可能产生的原因: 网络无连接,即本机无法上网 连接不到特定的 ...
- Python爬虫--- 1.1请求库的安装与使用
来说先说爬虫的原理:爬虫本质上是模拟人浏览信息的过程,只不过他通过计算机来达到快速抓取筛选信息的目的所以我们想要写一个爬虫,最基本的就是要将我们需要抓取信息的网页原原本本的抓取下来.这个时候就要用到请 ...
- 转 Python爬虫入门五之URLError异常处理
静觅 » Python爬虫入门五之URLError异常处理 1.URLError 首先解释下URLError可能产生的原因: 网络无连接,即本机无法上网 连接不到特定的服务器 服务器不存在 在代码中, ...
- python爬虫---从零开始(四)BeautifulSoup库
BeautifulSoup是什么? BeautifulSoup是一个网页解析库,相比urllib.Requests要更加灵活和方便,处理高校,支持多种解析器. 利用它不用编写正则表达式即可方便地实现网 ...
- python爬虫知识点总结(一)库的安装
环境要求: 1.编程语言版本python3: 2.系统:win10; 3.浏览器:Chrome68.0.3440.75:(如果不是最新版有可能影响到程序执行) 4.chromedriver2.41 注 ...
随机推荐
- Mac 下的截图技巧
最近想制作GIF图片,截图后,发现没有截出鼠标小效果,自己就查阅了一下资料,总结了不少的截图技巧,这里写下来,权当笔记,方便今后检索,方便别人共享. 方法一: 下载 QQ,在QQ的皮娜好设置里面设置截 ...
- 在头文件#pragma comment(lib,"glaux.lib");编译器提示waring C4081: 应输入“newline“
在头文件#pragma comment(lib,"glaux.lib");编译器提示waring C4081: 应输入“newline“ #行不能加分号的
- HDU 5882 Balanced Game (水题)
题意:问 nnn 个手势的石头剪刀布游戏是否能保证出每种手势胜率都一样. 析:当每种手势的攻防个数完全相等才能保证平衡,所以容易得出 nnn 是奇数时游戏平衡,否则不平衡. 也就是说打败 i 的和 i ...
- 我的Android笔记(十)—— ProgressDialog的简单应用,等待提示 (转载)
转自:http://blog.csdn.net/barryhappy/article/details/7376231 在应用中经常会用到一些费时的操作,需要用户进行等待,比如加载网页内容…… 这时候就 ...
- E20180419-hm
rectangle n. [数] 长方形,矩形; ratio n. 比例; 比,比率; 系数; vt. 求出比值,除,使…成比例; 将(相片)按比例放大[缩小]; aspect n. 方面; 面貌 ...
- 洛谷 - P2945 - 沙堡Sand Castle - 排序
https://www.luogu.org/problemnew/show/P2945 好像猜一猜就觉得排序之后是最优的,懒得证明了.每个城墙向他最接近的城墙靠近,绝对是最优的.
- 安装elasticsearch-rtf出错
出错信息: elasticsearch-rtf Caused by: java.lang.IllegalStateException: No match found 解决方法: 参考:https: ...
- Python入门小练习-001-备份文件
练习适用于LINUX,类Unix系统,一步一个脚印提高Python . 001. 类Unix系统中用zip命令将文件压缩备份至 /temporary/ 目录下: import os import ti ...
- OGG How to Resync Tables / Schemas on Different SCN s in a Single Replicat
To resync one or more tables/schemas on different SCN's using a single or minimum number of replicat ...
- ES--在windows上快速安装
环境准备 java环境部署: Java下载路径:http://download.oracle.com/otn-pub/java/jdk/8u181-b13/96a7b8442fe848ef90c96a ...